 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Incremental Unlearning: Techniques, Challenges, and Future Directions
Feb 23, 2025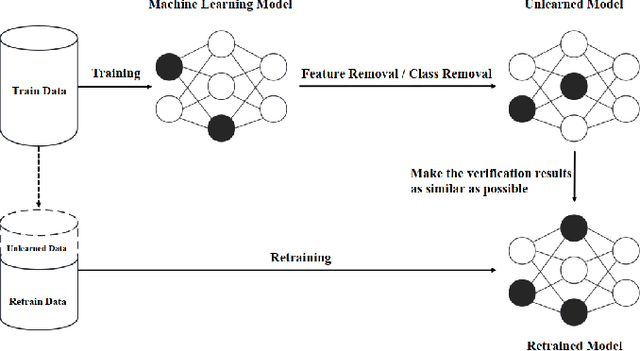
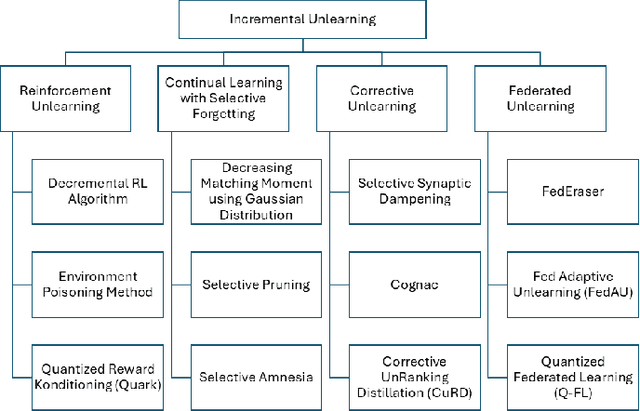
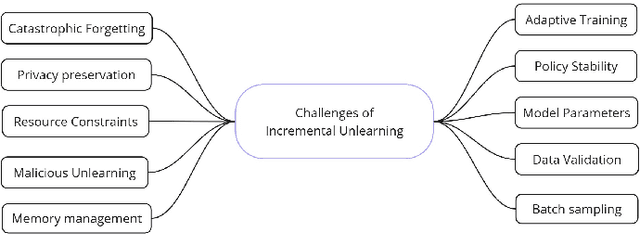

The growing demand for data privacy in Machine Learning (ML) applications has seen Machine Unlearning (MU) emerge as a critical area of research. As the `right to be forgotten' becomes regulated globally, it is increasingly important to develop mechanisms that delete user data from AI systems while maintaining performance and scalability of these systems. Incremental Unlearning (IU) is a promising MU solution to address the challenges of efficiently removing specific data from ML models without the need for expensive and time-consuming full retraining. This paper presents the various techniques and approaches to IU. It explores the challenges faced in designing and implementing IU mechanisms. Datasets and metrics for evaluating the performance of unlearning techniques are discussed as well. Finally, potential solutions to the IU challenges alongside future research directions are offered. This survey provides valuable insights for researchers and practitioners seeking to understand the current landscape of IU and its potential for enhancing privacy-preserving intelligent systems.