 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring ChatGPT-based Augmentation Strategies for Contrastive Aspect-based Sentiment Analysis
Sep 17, 2024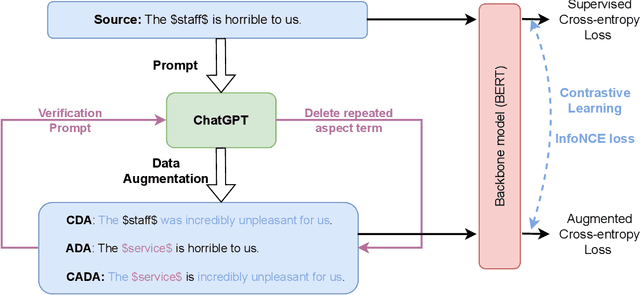

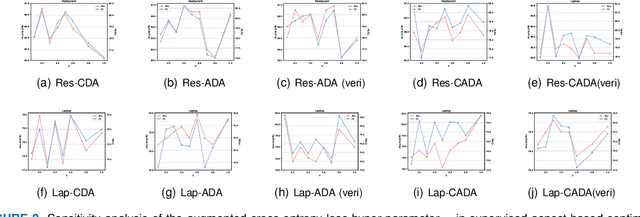
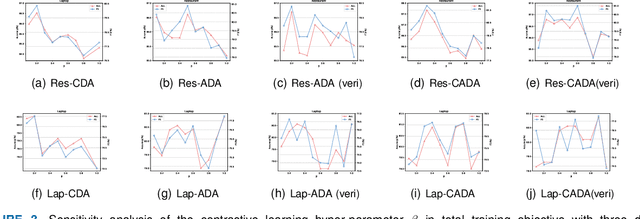
Aspect-based sentiment analysis (ABSA) involves identifying sentiment towards specific aspect terms in a sentence and allows us to uncover nuanced perspectives and attitudes on particular aspects of a product, service, or topic. However, the scarcity of labeled data poses a significant challenge to training high-quality models. To address this issue, we explore the potential of data augmentation using ChatGPT, a well-performing large language model (LLM), to enhance the sentiment classification performance towards aspect terms. Specifically, we explore three data augmentation strategies based on ChatGPT: context-focused, aspect-focused, and context-aspect data augmentation techniques. Context-focused data augmentation focuses on changing the word expression of context words in the sentence while keeping aspect terms unchanged. In contrast, aspect-focused data augmentation aims to change aspect terms but keep context words unchanged. Context-Aspect data augmentation integrates the above two data augmentations to generate augmented samples. Furthermore, we incorporate contrastive learning into the ABSA tasks to improve performance. Extensive experiments show that all three data augmentation techniques lead to performance improvements, with the context-aspect data augmentation strategy performing best and surpassing the performance of the baseline models.
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment
Dec 19, 2023With the continuous growth in the number of parameters of transformer-based pretrained language models (PLMs), particularly the emergence of large language models (LLMs) with billions of parameters, many natural language processing (NLP) tasks have demonstrated remarkable success. However, the enormous size and computational demands of these models pose significant challenges for adapting them to specific downstream tasks, especially in environments with limited computational resources. Parameter Efficient Fine-Tuning (PEFT) offers an effective solution by reducing the number of fine-tuning parameters and memory usage while achieving comparable performance to full fine-tuning. The demands for fine-tuning PLMs, especially LLMs, have led to a surge in the development of PEFT methods, as depicted in Fig. 1. In this paper, we present a comprehensive and systematic review of PEFT methods for PLMs. We summarize these PEFT methods, discuss their applications, and outline future directions. Furthermore, we conduct experiments using several representative PEFT methods to better understand their effectiveness in parameter efficiency and memory efficiency. By offering insights into the latest advancements and practical applications, this survey serves as an invaluable resource for researchers and practitioners seeking to navigate the challenges and opportunities presented by PEFT in the context of PLMs.