 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualGate-Net: A Prior-Gated Dual-Encoder Framework for Histopathology Cell Detection
Jun 05, 2026Cell detection in histopathology images strongly depends on surrounding tissue context, where visually similar cells may belong to different classes under different microenvironments. Recent tissue-aware methods incorporate contextual priors, but often rely on static fusion strategies that may propagate noisy information. In this work, we propose DualGate-Net, a prior-aware dual-encoder framework that combines a ConvNeXtV2-based local encoder and a SegFormer-based global encoder through a learnable prior-gated fusion mechanism. The proposed module adaptively regulates the influence of tissue priors across spatial locations, while an auxiliary foreground reconstruction branch preserves high-frequency cellular structures during training. In addition, auxiliary cellness-guided cues are incorporated to further improve localization robustness. Experiments on the OCELOT benchmark demonstrate consistent improvements, achieving macro F1-scores of 0.7722 on the validation set and 0.7345 on the test set, highlighting the effectiveness of adaptive prior integration for robust histopathology cell detection.
Noise-Aware Visual Representation Learning for Medical Visual Question Answering
Jun 04, 2026Medical visual question answering (Med-VQA) has strong potential for clinical decision support by enabling AI models to interpret medical images and answer clinically relevant queries. Recent approaches typically connect off-the-shelf vision encoders with large language models (LLMs) through lightweight mapping networks to reduce computational cost. However, these methods often overlook the importance of handling noise and small irrelevant changes in visual representations. To address these challenges, we propose a noise-aware Med-VQA framework that incorporates a denoising autoencoder before visual embeddings are mapped into the input space of an LLM. The denoising autoencoder is pretrained to reconstruct clean visual embeddings from corrupted inputs, encouraging the model to learn robust visual representations that are less sensitive to noise. The resulting embeddings are then projected into the language model embedding space using a multi-layer perceptron (MLP), forming visual prefix tokens that provide image information to the LLM. To enable efficient adaptation without full retraining, we employ parameter-efficient fine-tuning using low-rank adaptation (LoRA). The proposed method is evaluated on the SLAKE and PathVQA benchmarks. Experimental results show improved robustness to noisy input embeddings while maintaining competitive clean performance across multiple evaluation criteria. These findings suggest that learning more robust visual representations can enhance Med-VQA performance and robustness.
A Unified Solution to Diverse Heterogeneities in One-shot Federated Learning
Oct 28, 2024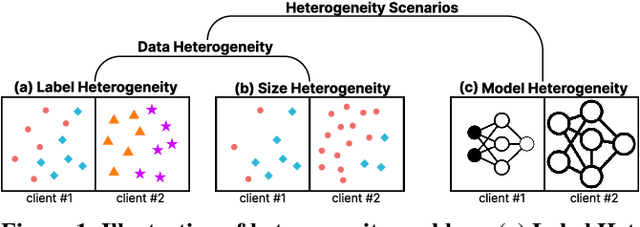

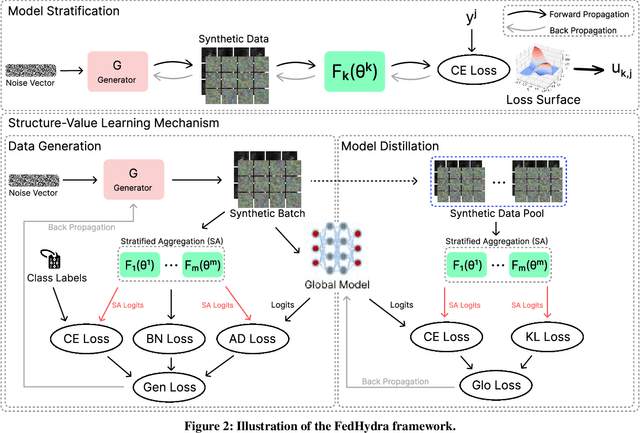
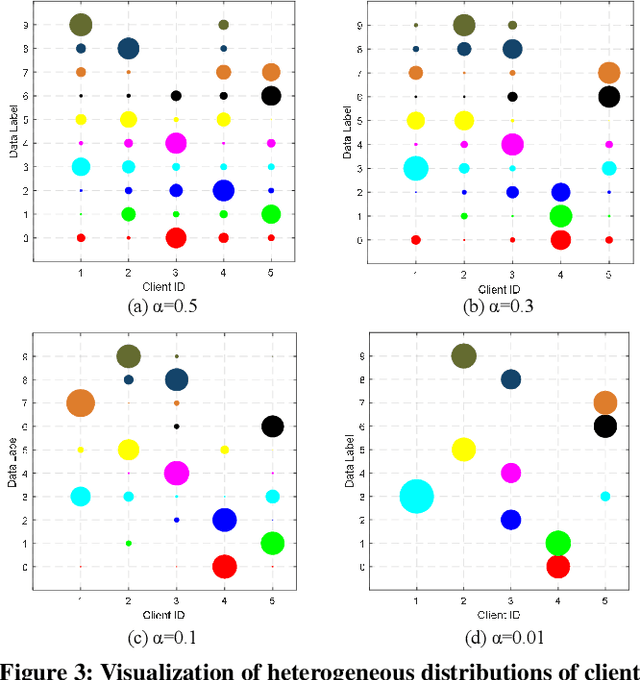
One-shot federated learning (FL) limits the communication between the server and clients to a single round, which largely decreases the privacy leakage risks in traditional FLs requiring multiple communications. However, we find existing one-shot FL frameworks are vulnerable to distributional heterogeneity due to their insufficient focus on data heterogeneity while concentrating predominantly on model heterogeneity. Filling this gap, we propose a unified, data-free, one-shot federated learning framework (FedHydra) that can effectively address both model and data heterogeneity. Rather than applying existing value-only learning mechanisms, a structure-value learning mechanism is proposed in FedHydra. Specifically, a new stratified learning structure is proposed to cover data heterogeneity, and the value of each item during computation reflects model heterogeneity. By this design, the data and model heterogeneity issues are simultaneously monitored from different aspects during learning. Consequently, FedHydra can effectively mitigate both issues by minimizing their inherent conflicts. We compared FedHydra with three SOTA baselines on four benchmark datasets. Experimental results show that our method outperforms the previous one-shot FL methods in both homogeneous and heterogeneous settings.
Hybrid Deep Learning Model using SPCAGAN Augmentation for Insider Threat Analysis
Mar 06, 2022

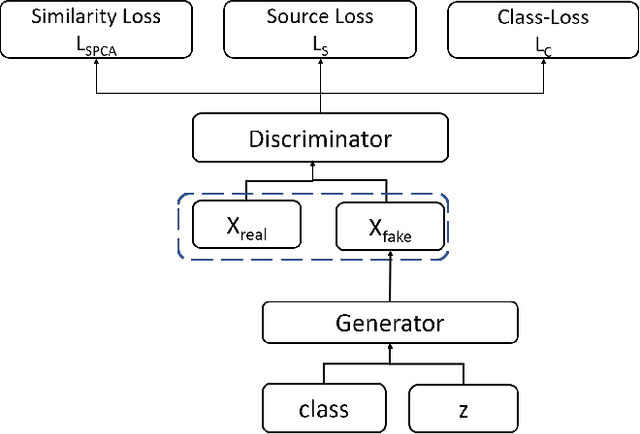
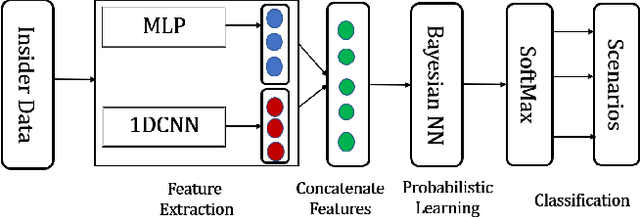
Cyberattacks from within an organization's trusted entities are known as insider threats. Anomaly detection using deep learning requires comprehensive data, but insider threat data is not readily available due to confidentiality concerns of organizations. Therefore, there arises demand to generate synthetic data to explore enhanced approaches for threat analysis. We propose a linear manifold learning-based generative adversarial network, SPCAGAN, that takes input from heterogeneous data sources and adds a novel loss function to train the generator to produce high-quality data that closely resembles the original data distribution. Furthermore, we introduce a deep learning-based hybrid model for insider threat analysis. We provide extensive experiments for data synthesis, anomaly detection, adversarial robustness, and synthetic data quality analysis using benchmark datasets. In this context, empirical comparisons show that GAN-based oversampling is competitive with numerous typical oversampling regimes. For synthetic data generation, our SPCAGAN model overcame the problem of mode collapse and converged faster than previous GAN models. Results demonstrate that our proposed approach has a lower error, is more accurate, and generates substantially superior synthetic insider threat data than previous models.
Multi-class Classification Based Anomaly Detection of Insider Activities
Feb 15, 2021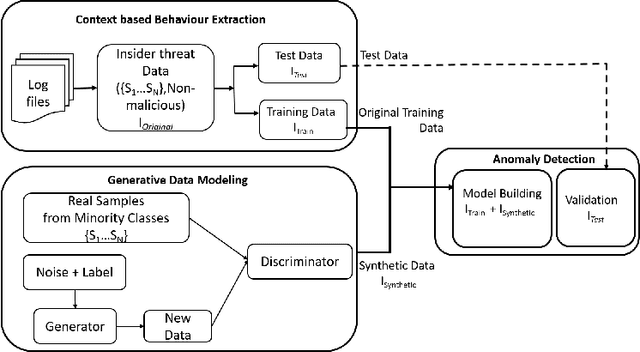
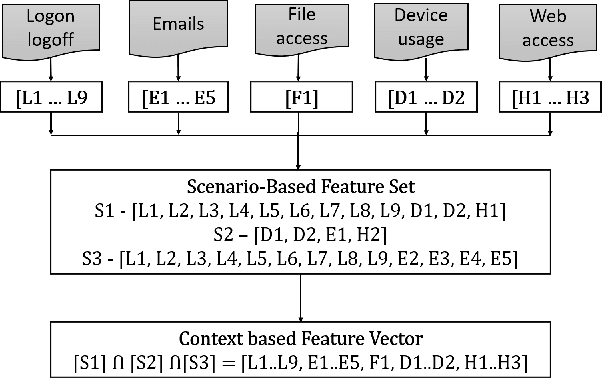
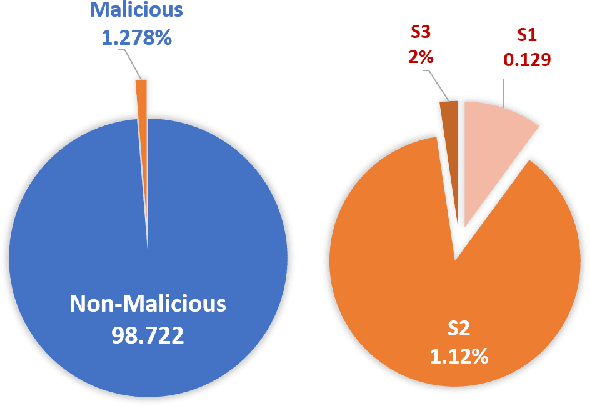
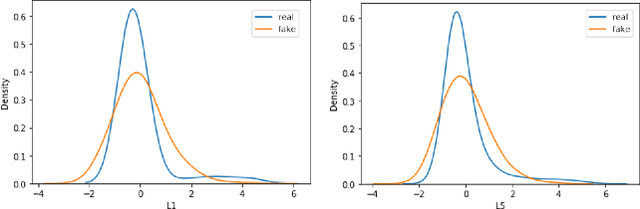
Insider threats are the cyber attacks from within the trusted entities of an organization. Lack of real-world data and issue of data imbalance leave insider threat analysis an understudied research area. To mitigate the effect of skewed class distribution and prove the potential of multinomial classification algorithms for insider threat detection, we propose an approach that combines generative model with supervised learning to perform multi-class classification using deep learning. The generative adversarial network (GAN) based insider detection model introduces Conditional Generative Adversarial Network (CGAN) to enrich minority class samples to provide data for multi-class anomaly detection. The comprehensive experiments performed on the benchmark dataset demonstrates the effectiveness of introducing GAN derived synthetic data and the capability of multi-class anomaly detection in insider activity analysis. Moreover, the method is compared with other existing methods against different parameters and performance metrics.
Image-Based Feature Representation for Insider Threat Classification
Nov 13, 2019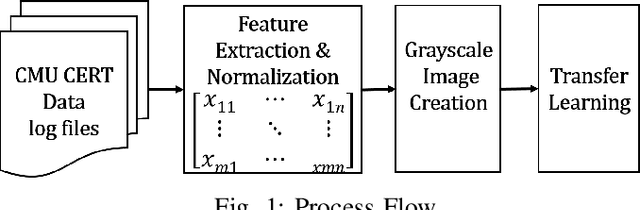
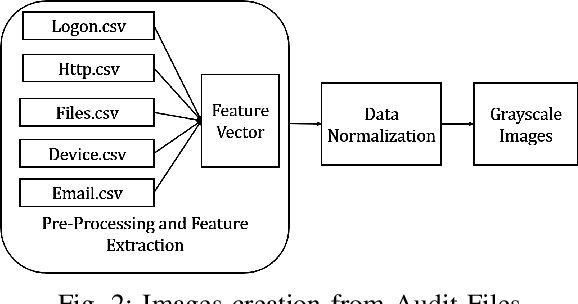

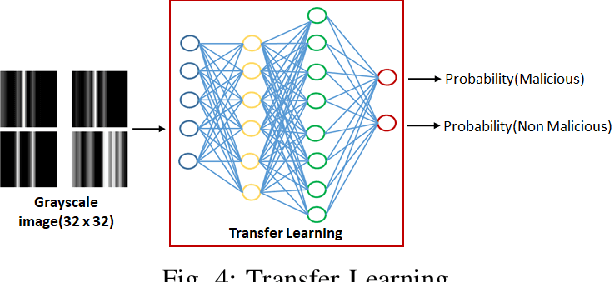
Insiders are the trusted entities in the organization, but poses threat to the with access to sensitive information network and resources. The insider threat detection is a well studied problem in security analytics. Identifying the features from data sources and using them with the right data analytics algorithms makes various kinds of threat analysis possible. The insider threat analysis is mainly done using the frequency based attributes extracted from the raw data available from data sources. In this paper, we propose an image-based feature representation of the daily resource usage pattern of users in the organization. The features extracted from the audit files of the organization are represented as gray scale images. Hence, these images are used to represent the resource access patterns and thereby the behavior of users. Classification models are applied to the representative images to detect anomalous behavior of insiders. The images are classified to malicious and non-malicious. The effectiveness of the proposed representation is evaluated using the CMU CERT data V4.2, and state-of-art image classification models like Mobilenet, VGG and ResNet. The experimental results showed improved accuracy. The comparison with existing works show a performance improvement in terms of high recall and precision values.
Our Practice Of Using Machine Learning To Recognize Species By Voice
Oct 22, 2018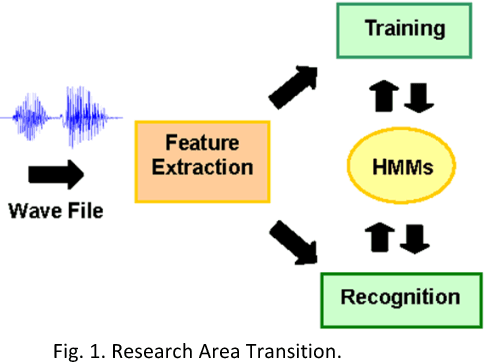
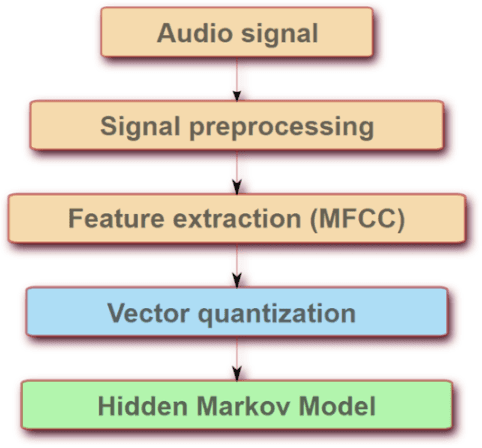
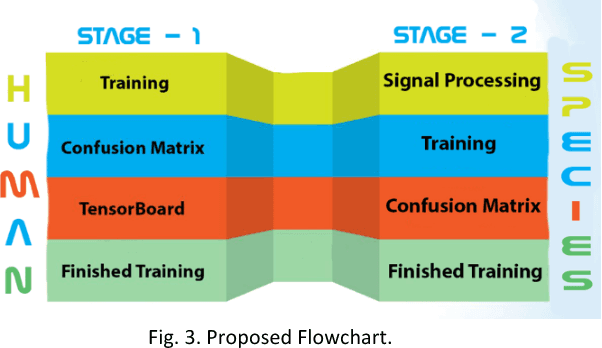
As the technology is advancing, audio recognition in machine learning is improved as well. Research in audio recognition has traditionally focused on speech. Living creatures (especially the small ones) are part of the whole ecosystem, monitoring as well as maintaining them are important tasks. Species such as animals and birds are tending to change their activities as well as their habitats due to the adverse effects on the environment or due to other natural or man-made calamities. For those in far deserted areas, we will not have any idea about their existence until we can continuously monitor them. Continuous monitoring will take a lot of hard work and labor. If there is no continuous monitoring, then there might be instances where endangered species may encounter dangerous situations. The best way to monitor those species are through audio recognition. Classifying sound can be a difficult task even for humans. Powerful audio signals and their processing techniques make it possible to detect audio of various species. There might be many ways wherein audio recognition can be done. We can train machines either by pre-recorded audio files or by recording them live and detecting them. The audio of species can be detected by removing all the background noise and echoes. Smallest sound is considered as a syllable. Extracting various syllables is the process we are focusing on which is known as audio recognition in terms of Machine Learning (ML).