 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperFake: Hyperspectral Reconstruction and Attention-Guided Analysis for Advanced Deepfake Detection
May 24, 2025Deepfakes pose a significant threat to digital media security, with current detection methods struggling to generalize across different manipulation techniques and datasets. While recent approaches combine CNN-based architectures with Vision Transformers or leverage multi-modal learning, they remain limited by the inherent constraints of RGB data. We introduce HyperFake, a novel deepfake detection pipeline that reconstructs 31-channel hyperspectral data from standard RGB videos, revealing hidden manipulation traces invisible to conventional methods. Using an improved MST++ architecture, HyperFake enhances hyperspectral reconstruction, while a spectral attention mechanism selects the most critical spectral features for deepfake detection. The refined spectral data is then processed by an EfficientNet-based classifier optimized for spectral analysis, enabling more accurate and generalizable detection across different deepfake styles and datasets, all without the need for expensive hyperspectral cameras. To the best of our knowledge, this is the first approach to leverage hyperspectral imaging reconstruction for deepfake detection, opening new possibilities for detecting increasingly sophisticated manipulations.
Automated Bleeding Detection and Classification in Wireless Capsule Endoscopy with YOLOv8-X
Dec 21, 2024Gastrointestinal (GI) bleeding, a critical indicator of digestive system disorders, re quires efficient and accurate detection methods. This paper presents our solution to the Auto-WCEBleedGen Version V1 Challenge, where we achieved the consolation position. We developed a unified YOLOv8-X model for both detection and classification of bleeding regions in Wireless Capsule Endoscopy (WCE) images. Our approach achieved 96.10% classification accuracy and 76.8% mean Average Precision (mAP) at 0.5 IoU on the val idation dataset. Through careful dataset curation and annotation, we assembled and trained on 6,345 diverse images to ensure robust model performance. Our implementa tion code and trained models are publicly available at https://github.com/pavan98765/Auto-WCEBleedGen.
Novel entropy difference-based EEG channel selection technique for automated detection of ADHD
Apr 15, 2024Attention deficit hyperactivity disorder (ADHD) is one of the common neurodevelopmental disorders in children. This paper presents an automated approach for ADHD detection using the proposed entropy difference (EnD)- based encephalogram (EEG) channel selection approach. In the proposed approach, we selected the most significant EEG channels for the accurate identification of ADHD using an EnD-based channel selection approach. Secondly, a set of features is extracted from the selected channels and fed to a classifier. To verify the effectiveness of the channels selected, we explored three sets of features and classifiers. More specifically, we explored discrete wavelet transform (DWT), empirical mode decomposition (EMD) and symmetrically-weighted local binary pattern (SLBP)-based features. To perform automated classification, we have used k-nearest neighbor (k-NN), Ensemble classifier, and support vectors machine (SVM) classifiers. Our proposed approach yielded the highest accuracy of 99.29% using the public database. In addition, the proposed EnD-based channel selection has consistently provided better classification accuracies than the entropy-based channel selection approach. Also, the developed method
CrowdFormer: Weakly-supervised Crowd counting with Improved Generalizability
Mar 07, 2022
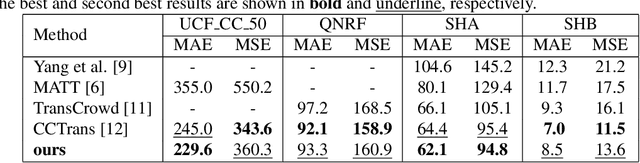
Convolutional neural networks (CNNs) have dominated the field of computer vision for nearly a decade due to their strong ability to learn local features. However, due to their limited receptive field, CNNs fail to model the global context. On the other hand, transformer, an attention-based architecture can model the global context easily. Despite this, there are limited studies that investigate the effectiveness of transformers in crowd counting. In addition, the majority of the existing crowd counting methods are based on the regression of density maps which requires point-level annotation of each person present in the scene. This annotation task is laborious and also error-prone. This has led to increased focus on weakly-supervised crowd counting methods which require only the count-level annotations. In this paper, we propose a weakly-supervised method for crowd counting using a pyramid vision transformer. We have conducted extensive evaluations to validate the effectiveness of the proposed method. Our method is comparable to the state-of-the-art on the benchmark crowd datasets. More importantly, it shows remarkable generalizability.
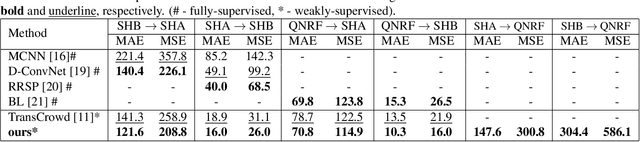
A Contactless Fingerprint Recognition System
Aug 20, 2021


Fingerprints are one of the most widely explored biometric traits. Specifically, contact-based fingerprint recognition systems reign supreme due to their robustness, portability and the extensive research work done in the field. However, these systems suffer from issues such as hygiene, sensor degradation due to constant physical contact, and latent fingerprint threats. In this paper, we propose an approach for developing a contactless fingerprint recognition system that captures finger photo from a distance using an image sensor in a suitable environment. The captured finger photos are then processed further to obtain global and local (minutiae-based) features. Specifically, a Siamese convolutional neural network (CNN) is designed to extract global features from a given finger photo. The proposed system computes matching scores from CNN-based features and minutiae-based features. Finally, the two scores are fused to obtain the final matching score between the probe and reference fingerprint templates. Most importantly, the proposed system is developed using the Nvidia Jetson Nano development kit, which allows us to perform contactless fingerprint recognition in real-time with minimum latency and acceptable matching accuracy. The performance of the proposed system is evaluated on an in-house IITI contactless fingerprint dataset (IITI-CFD) containing 105train and 100 test subjects. The proposed system achieves an equal-error-rate of 2.19% on IITI-CFD.
Cross-sensor Pore Detection in High-resolution Fingerprint Images using Unsupervised Domain Adaptation
Aug 28, 2019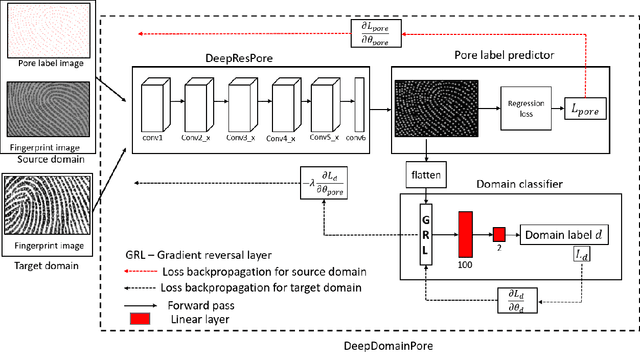


With the emergence of the high-resolution fingerprint sensors, the research community has focused on level-3 fingerprint features especially, pores for providing the next generation automated fingerprint recognition system (AFRS). Following the recent success of the deep learning approaches in various computer vision tasks, researchers have explored learning-based approaches for pore detection in high-resolution fingerprint images. These learning-based approaches provide better performance than the hand-crafted feature-based approaches. However, domain adaptability of existing learning-based pore detection methods has not been examined in the past. In this paper, we present the first study of domain adaptability of existing learning-based pore detection methods. For this purpose, we have generated an in-house ground truth dataset referred to as IITI-HRF-GT by using 1000 dpi fingerprint sensor and evaluated the performance of the existing learning-based pore detection approaches on it. Further, we have also proposed an approach for detecting pores in a cross sensor scenario referred to as DeepDomainPore using unsupervised domain adaptation technique. Specifically, DeepDomainPore is a combination of a convolutional neural network (CNN) based pore detection approach DeepResPore and an unsupervised domain adaptation approach included during the training process. The domain adaptation in the DeepDomainPore is achieved by embedding a gradient reversal layer between the DeepResPore and a domain classifier network. The results of all the existing and the proposed learning-based pore detection approaches are evaluated on IITI-HRF-GT. The DeepDomainPore provides a true detection rate of 88.09%and an F-score of 83.94% on IITI-HRF-GT. Most importantly, the proposed approach achieves state-of-the-art performance on the cross sensor dataset.
PoreNet: CNN-based Pore Descriptor for High-resolution Fingerprint Recognition
May 16, 2019
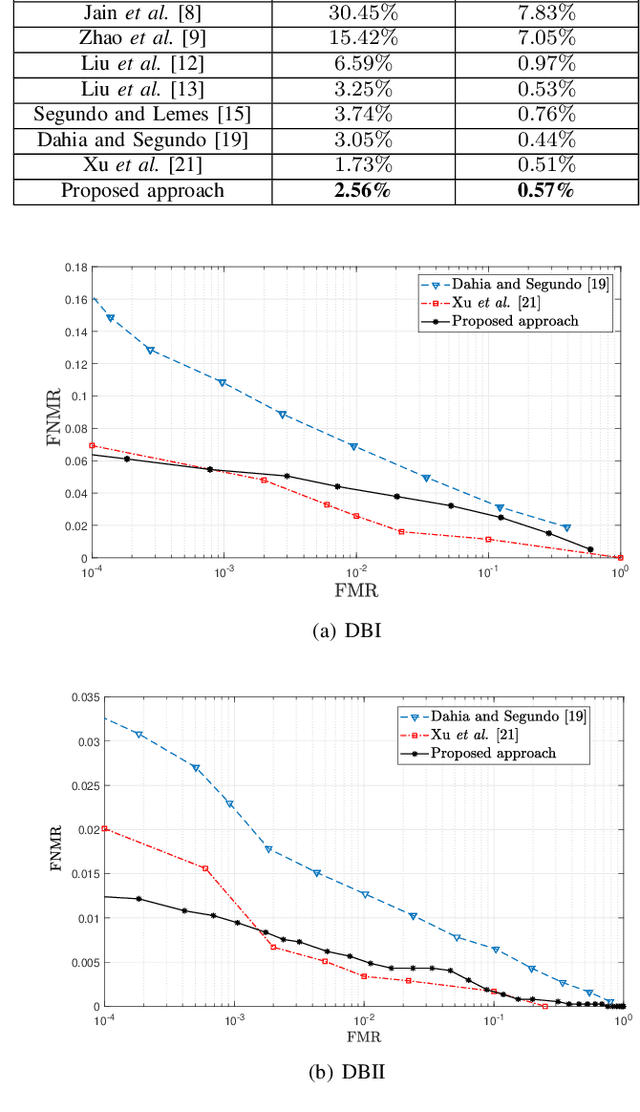
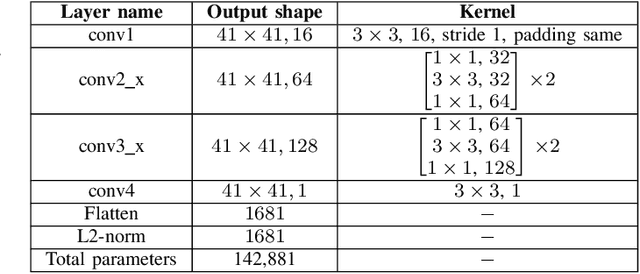
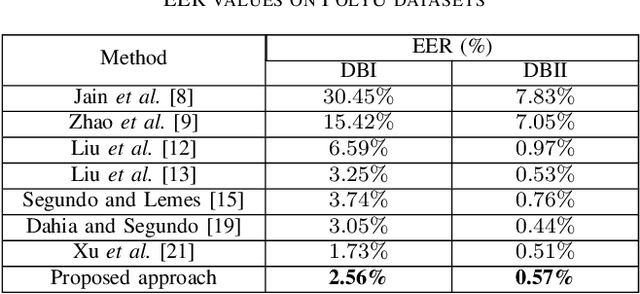
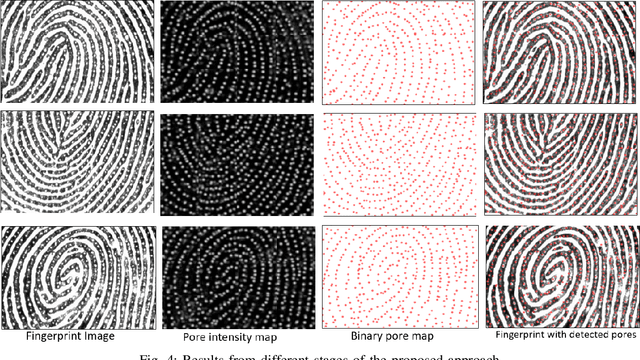
With the development of high-resolution fingerprint scanners, high-resolution fingerprint-based biometric recognition has received increasing attention in recent years. This letter presents a pore feature-based approach for biometric recognition. Our approach employs a convolutional neural network (CNN) model, DeepResPore, to detect pores in the input fingerprint image. Thereafter, a CNN-based descriptor is computed for a patch around each detected pore. Specifically, we have designed a residual learning-based CNN, referred to as PoreNet that learns distinctive feature representation from pore patches. For verification, the match score is generated by comparing pore descriptors obtained from a pair of fingerprint images in bi-directional manner using the Euclidean distance. The proposed approach for high-resolution fingerprint recognition achieves 2.56% and 0.57% equal error rates (EERs) on partial (DBI) and complete (DBII) fingerprints of the benchmark PolyU HRF dataset. Most importantly, it achieves lower FMR1000 and FMR10000 values than the current state-of-the-art approach on both the datasets.
PVSNet: Palm Vein Authentication Siamese Network Trained using Triplet Loss and Adaptive Hard Mining by Learning Enforced Domain Specific Features
Dec 15, 2018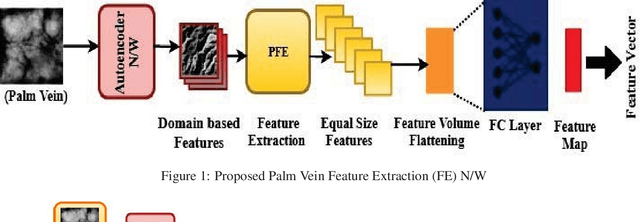
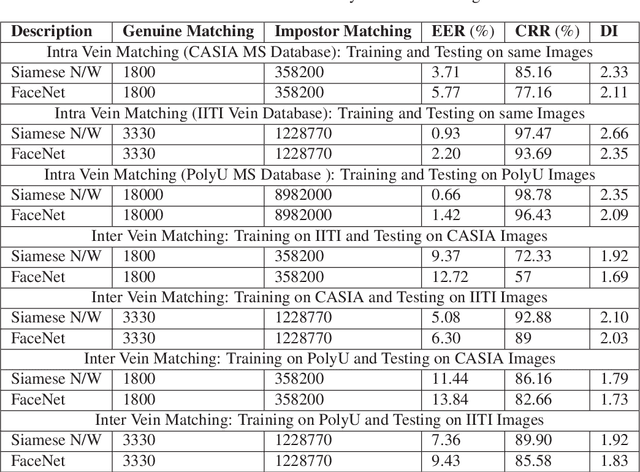
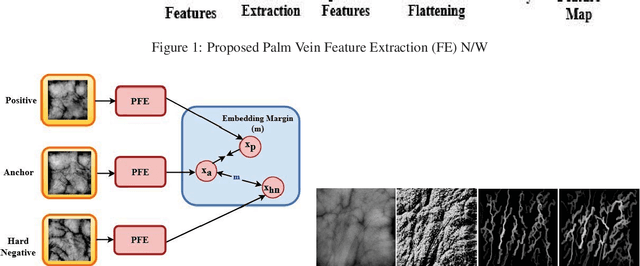

Designing an end-to-end deep learning network to match the biometric features with limited training samples is an extremely challenging task. To address this problem, we propose a new way to design an end-to-end deep CNN framework i.e., PVSNet that works in two major steps: first, an encoder-decoder network is used to learn generative domain-specific features followed by a Siamese network in which convolutional layers are pre-trained in an unsupervised fashion as an autoencoder. The proposed model is trained via triplet loss function that is adjusted for learning feature embeddings in a way that minimizes the distance between embedding-pairs from the same subject and maximizes the distance with those from different subjects, with a margin. In particular, a triplet Siamese matching network using an adaptive margin based hard negative mining has been suggested. The hyper-parameters associated with the training strategy, like the adaptive margin, have been tuned to make the learning more effective on biometric datasets. In extensive experimentation, the proposed network outperforms most of the existing deep learning solutions on three type of typical vein datasets which clearly demonstrates the effectiveness of our proposed method.