 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdFormer: Weakly-supervised Crowd counting with Improved Generalizability
Mar 07, 2022
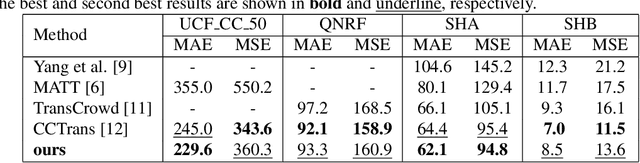
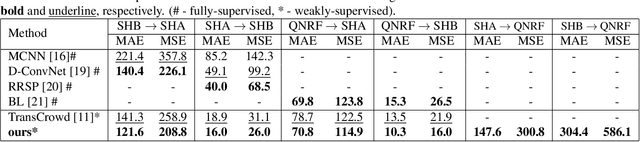
Convolutional neural networks (CNNs) have dominated the field of computer vision for nearly a decade due to their strong ability to learn local features. However, due to their limited receptive field, CNNs fail to model the global context. On the other hand, transformer, an attention-based architecture can model the global context easily. Despite this, there are limited studies that investigate the effectiveness of transformers in crowd counting. In addition, the majority of the existing crowd counting methods are based on the regression of density maps which requires point-level annotation of each person present in the scene. This annotation task is laborious and also error-prone. This has led to increased focus on weakly-supervised crowd counting methods which require only the count-level annotations. In this paper, we propose a weakly-supervised method for crowd counting using a pyramid vision transformer. We have conducted extensive evaluations to validate the effectiveness of the proposed method. Our method is comparable to the state-of-the-art on the benchmark crowd datasets. More importantly, it shows remarkable generalizability.