 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Forks to Forceps: A New Framework for Instance Segmentation of Surgical Instruments
Nov 26, 2022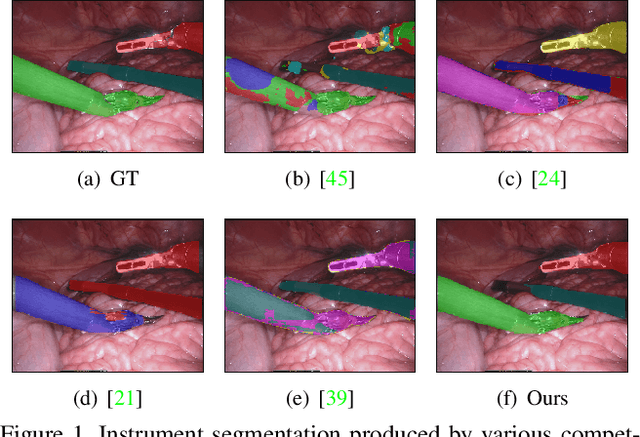
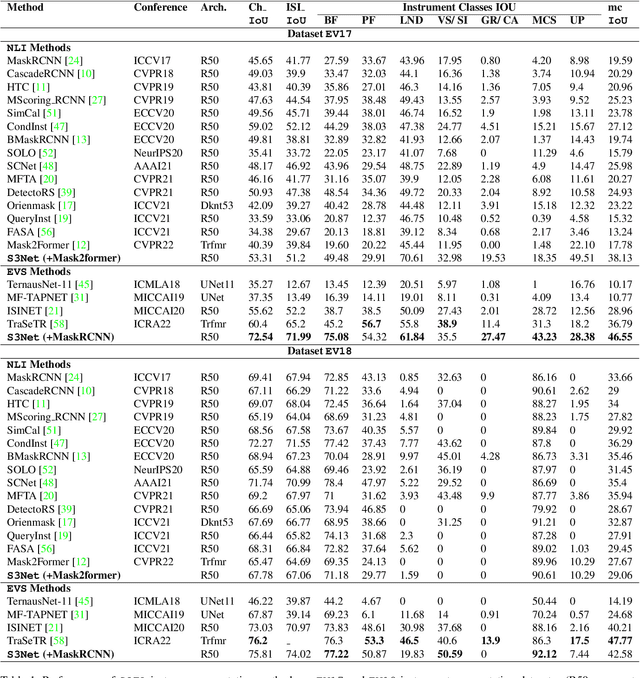
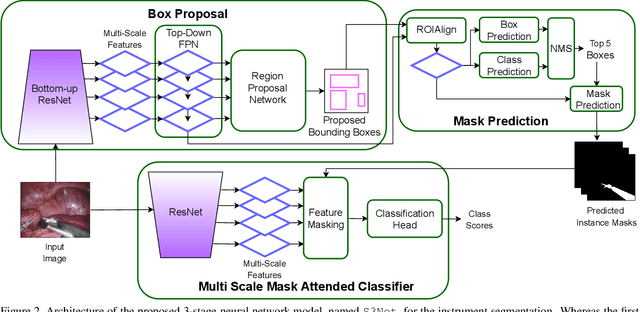

Minimally invasive surgeries and related applications demand surgical tool classification and segmentation at the instance level. Surgical tools are similar in appearance and are long, thin, and handled at an angle. The fine-tuning of state-of-the-art (SOTA) instance segmentation models trained on natural images for instrument segmentation has difficulty discriminating instrument classes. Our research demonstrates that while the bounding box and segmentation mask are often accurate, the classification head mis-classifies the class label of the surgical instrument. We present a new neural network framework that adds a classification module as a new stage to existing instance segmentation models. This module specializes in improving the classification of instrument masks generated by the existing model. The module comprises multi-scale mask attention, which attends to the instrument region and masks the distracting background features. We propose training our classifier module using metric learning with arc loss to handle low inter-class variance of surgical instruments. We conduct exhaustive experiments on the benchmark datasets EndoVis2017 and EndoVis2018. We demonstrate that our method outperforms all (more than 18) SOTA methods compared with, and improves the SOTA performance by at least 12 points (20%) on the EndoVis2017 benchmark challenge and generalizes effectively across the datasets.
PoshakNet: Framework for matching dresses from real-life photos using GAN and Siamese Network
Nov 11, 2019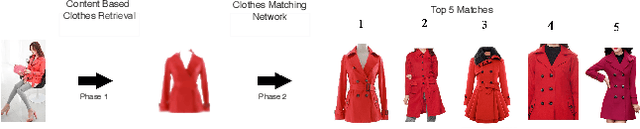
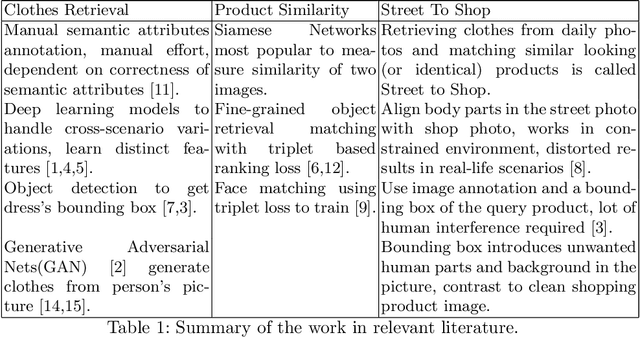

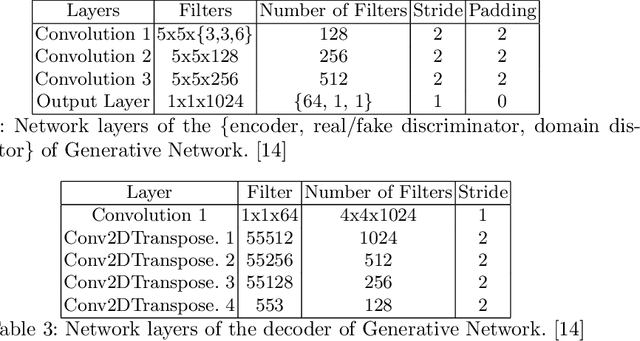
Online garment shopping has gained many customers in recent years. Describing a dress using keywords does not always yield the proper results, which in turn leads to dissatisfaction of customers. A visual search based system will be enormously beneficent to the industry. Hence, we propose a framework that can retrieve similar clothes that can be found in an image. The first task is to extract the garment from the input image (street photo). There are various challenges for that, including pose, illumination, and background clutter. We use a Generative Adversarial Network for the task of retrieving the garment that the person in the image was wearing. It has been shown that GAN can retrieve the garment very efficiently despite the challenges of street photos. Finally, a siamese based matching system takes the retrieved cloth image and matches it with the clothes in the dataset, giving us the top k matches. We take a pre-trained inception-ResNet v1 module as a siamese network (trained using triplet loss for face detection) and fine-tune it on the shopping dataset using center loss. The dataset has been collected inhouse. For training the GAN, we use the LookBook dataset, which is publically available.
FKIMNet: A Finger Dorsal Image Matching Network Comparing Component (Major, Minor and Nail) Matching with Holistic (Finger Dorsal) Matching
Apr 02, 2019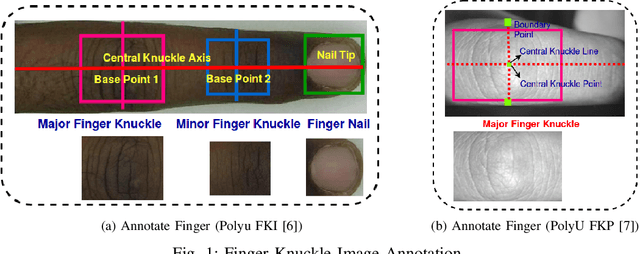
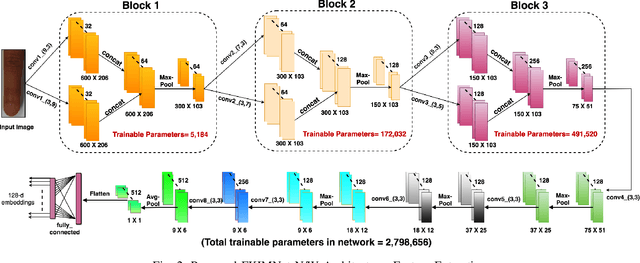
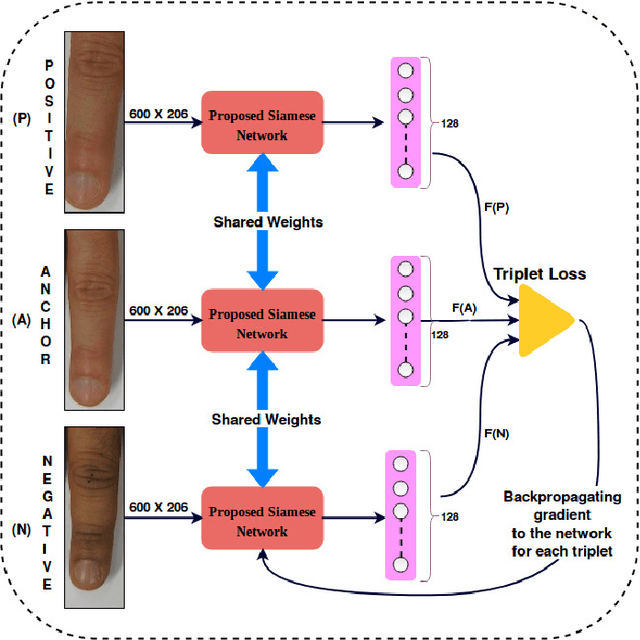
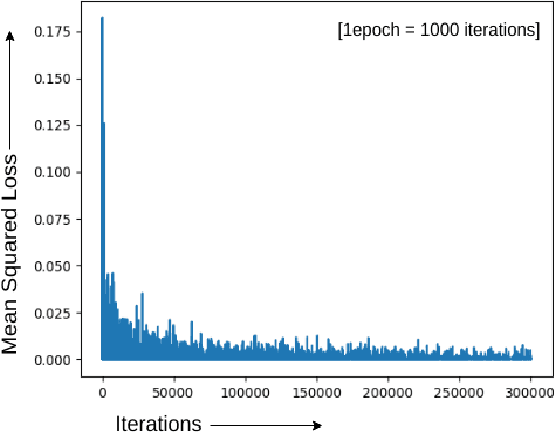
Current finger knuckle image recognition systems, often require users to place fingers' major or minor joints flatly towards the capturing sensor. To extend these systems for user non-intrusive application scenarios, such as consumer electronics, forensic, defence etc, we suggest matching the full dorsal fingers, rather than the major/ minor region of interest (ROI) alone. In particular, this paper makes a comprehensive study on the comparisons between full finger and fusion of finger ROI's for finger knuckle image recognition. These experiments suggest that using full-finger, provides a more elegant solution. Addressing the finger matching problem, we propose a CNN (convolutional neural network) which creates a $128$-D feature embedding of an image. It is trained via. triplet loss function, which enforces the L2 distance between the embeddings of the same subject to be approaching zero, whereas the distance between any 2 embeddings of different subjects to be at least a margin. For precise training of the network, we use dynamic adaptive margin, data augmentation, and hard negative mining. In distinguished experiments, the individual performance of finger, as well as weighted sum score level fusion of major knuckle, minor knuckle, and nail modalities have been computed, justifying our assumption to consider full finger as biometrics instead of its counterparts. The proposed method is evaluated using two publicly available finger knuckle image datasets i.e., PolyU FKP dataset and PolyU Contactless FKI Datasets.
Multiscale CNN based Deep Metric Learning for Bioacoustic Classification: Overcoming Training Data Scarcity Using Dynamic Triplet Loss
Mar 27, 2019
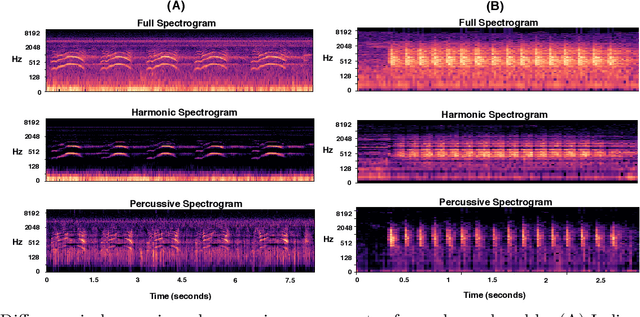

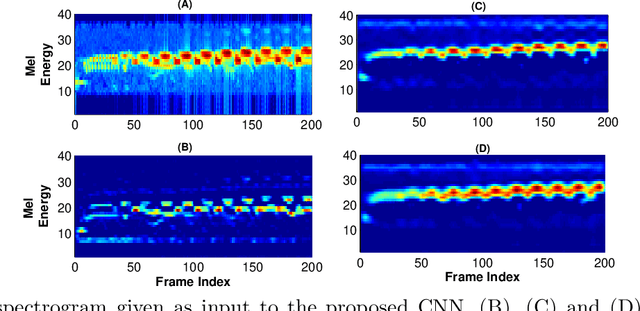
This paper proposes multiscale convolutional neural network (CNN)-based deep metric learning for bioacoustic classification, under low training data conditions. The proposed CNN is characterized by the utilization of four different filter sizes at each level to analyze input feature maps. This multiscale nature helps in describing different bioacoustic events effectively: smaller filters help in learning the finer details of bioacoustic events, whereas, larger filters help in analyzing a larger context leading to global details. A dynamic triplet loss is employed in the proposed CNN architecture to learn a transformation from the input space to the embedding space, where classification is performed. The triplet loss helps in learning this transformation by analyzing three examples, referred to as triplets, at a time where intra-class distance is minimized while maximizing the inter-class separation by a dynamically increasing margin. The number of possible triplets increases cubically with the dataset size, making triplet loss more suitable than the softmax cross-entropy loss in low training data conditions. Experiments on three different publicly available datasets show that the proposed framework performs better than existing bioacoustic classification frameworks. Experimental results also confirm the superiority of the triplet loss over the cross-entropy loss in low training data conditions
PVSNet: Palm Vein Authentication Siamese Network Trained using Triplet Loss and Adaptive Hard Mining by Learning Enforced Domain Specific Features
Dec 15, 2018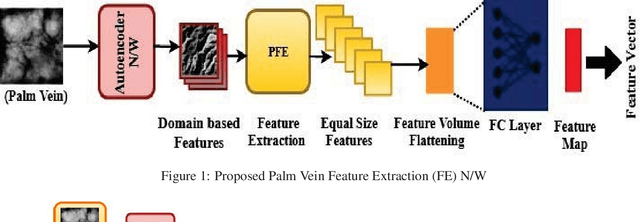
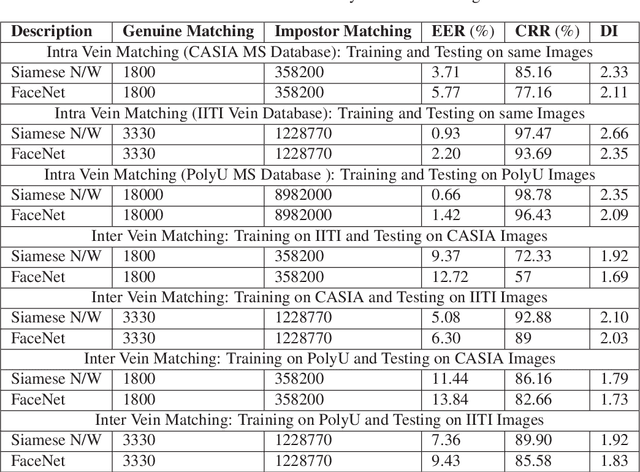
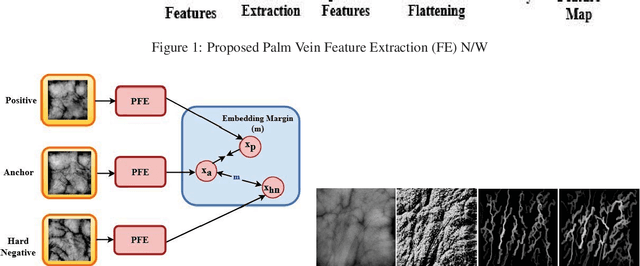

Designing an end-to-end deep learning network to match the biometric features with limited training samples is an extremely challenging task. To address this problem, we propose a new way to design an end-to-end deep CNN framework i.e., PVSNet that works in two major steps: first, an encoder-decoder network is used to learn generative domain-specific features followed by a Siamese network in which convolutional layers are pre-trained in an unsupervised fashion as an autoencoder. The proposed model is trained via triplet loss function that is adjusted for learning feature embeddings in a way that minimizes the distance between embedding-pairs from the same subject and maximizes the distance with those from different subjects, with a margin. In particular, a triplet Siamese matching network using an adaptive margin based hard negative mining has been suggested. The hyper-parameters associated with the training strategy, like the adaptive margin, have been tuned to make the learning more effective on biometric datasets. In extensive experimentation, the proposed network outperforms most of the existing deep learning solutions on three type of typical vein datasets which clearly demonstrates the effectiveness of our proposed method.
BrainSegNet : A Segmentation Network for Human Brain Fiber Tractography Data into Anatomically Meaningful Clusters
Oct 14, 2017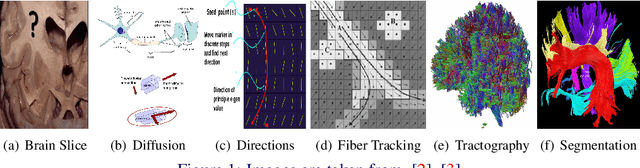

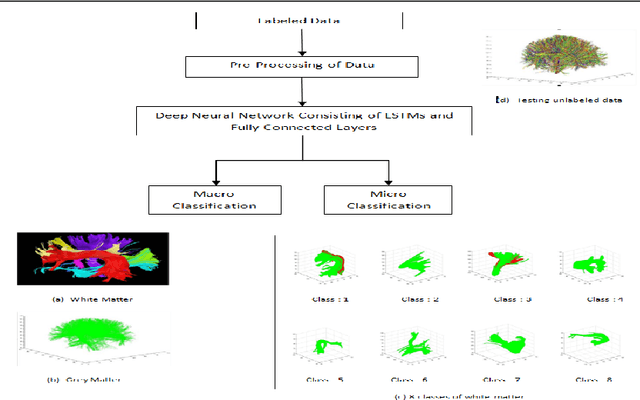
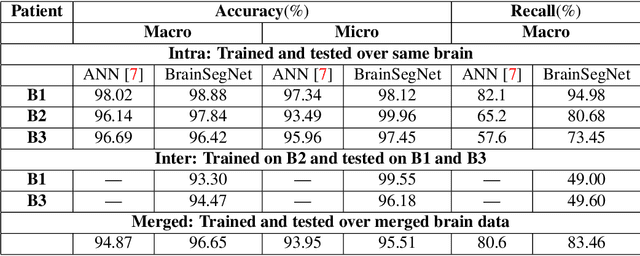
The segregation of brain fiber tractography data into distinct and anatomically meaningful clusters can help to comprehend the complex brain structure and early investigation and management of various neural disorders. We propose a novel stacked bidirectional long short-term memory(LSTM) based segmentation network, (BrainSegNet) for human brain fiber tractography data classification. We perform a two-level hierarchical classification a) White vs Grey matter (Macro) and b) White matter clusters (Micro). BrainSegNet is trained over three brain tractography data having over 250,000 fibers each. Our experimental evaluation shows that our model achieves state-of-the-art results. We have performed inter as well as intra class testing over three patient's brain tractography data and achieved a high classification accuracy for both macro and micro levels both under intra as well as inter brain testing scenario.
VGR-Net: A View Invariant Gait Recognition Network
Oct 13, 2017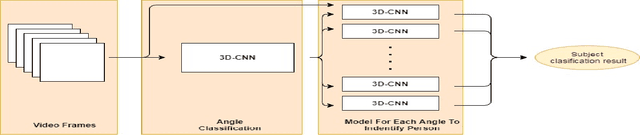
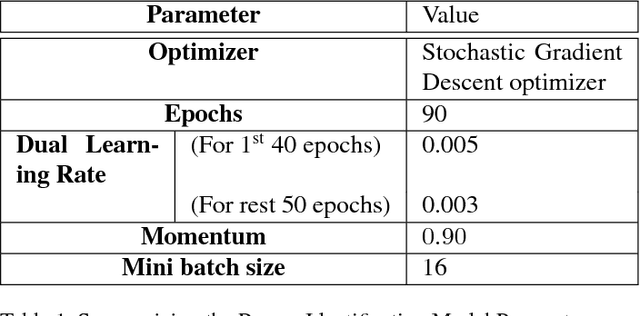
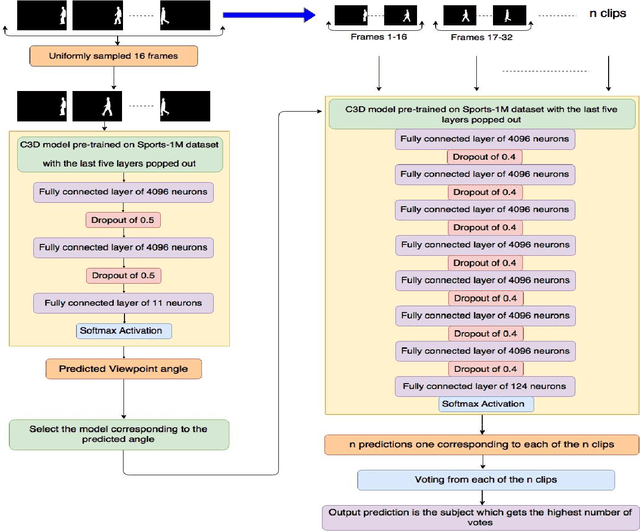
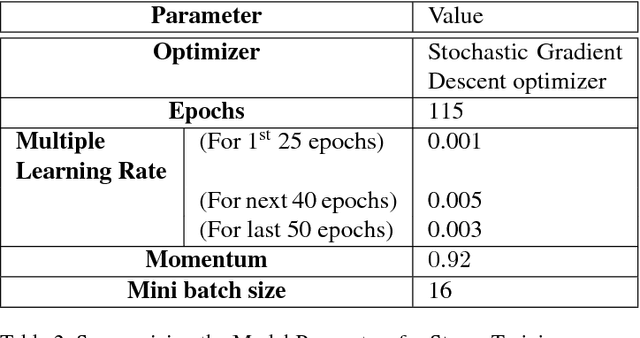
Biometric identification systems have become immensely popular and important because of their high reliability and efficiency. However person identification at a distance, still remains a challenging problem. Gait can be seen as an essential biometric feature for human recognition and identification. It can be easily acquired from a distance and does not require any user cooperation thus making it suitable for surveillance. But the task of recognizing an individual using gait can be adversely affected by varying view points making this task more and more challenging. Our proposed approach tackles this problem by identifying spatio-temporal features and performing extensive experimentation and training mechanism. In this paper, we propose a 3-D Convolution Deep Neural Network for person identification using gait under multiple view. It is a 2-stage network, in which we have a classification network that initially identifies the viewing point angle. After that another set of networks (one for each angle) has been trained to identify the person under a particular viewing angle. We have tested this network over CASIA-B publicly available database and have achieved state-of-the-art results. The proposed system is much more efficient in terms of time and space and performing better for almost all angles.
UBSegNet: Unified Biometric Region of Interest Segmentation Network
Sep 26, 2017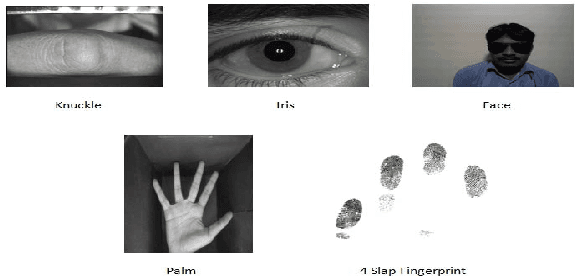
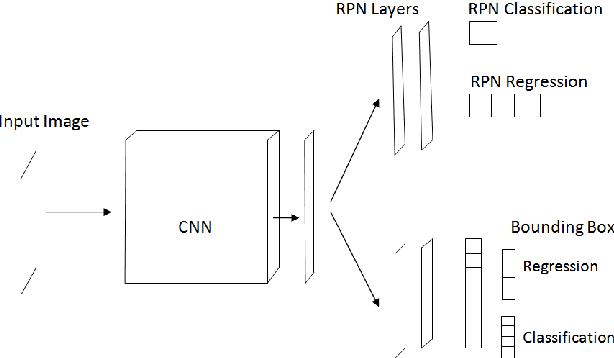
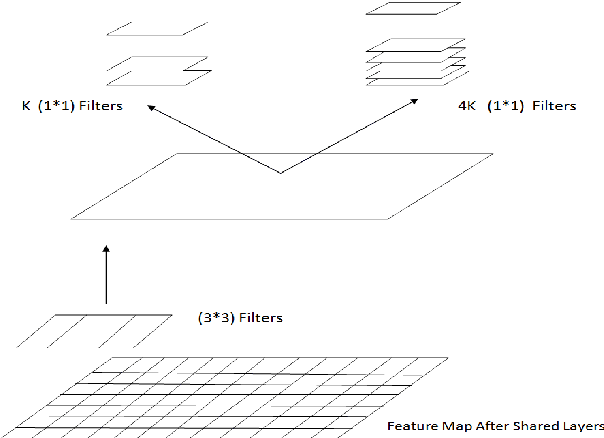
Digital human identity management, can now be seen as a social necessity, as it is essentially required in almost every public sector such as, financial inclusions, security, banking, social networking e.t.c. Hence, in today's rampantly emerging world with so many adversarial entities, relying on a single biometric trait is being too optimistic. In this paper, we have proposed a novel end-to-end, Unified Biometric ROI Segmentation Network (UBSegNet), for extracting region of interest from five different biometric traits viz. face, iris, palm, knuckle and 4-slap fingerprint. The architecture of the proposed UBSegNet consists of two stages: (i) Trait classification and (ii) Trait localization. For these stages, we have used a state of the art region based convolutional neural network (RCNN), comprising of three major parts namely convolutional layers, region proposal network (RPN) along with classification and regression heads. The model has been evaluated over various huge publicly available biometric databases. To the best of our knowledge this is the first unified architecture proposed, segmenting multiple biometric traits. It has been tested over around 5000 * 5 = 25,000 images (5000 images per trait) and produces very good results. Our work on unified biometric segmentation, opens up the vast opportunities in the field of multiple biometric traits based authentication systems.