 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth Monitoring of Industrial machines using Scene-Aware Threshold Selection
Nov 21, 2021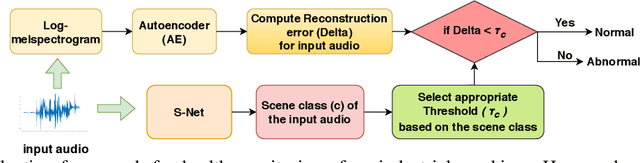
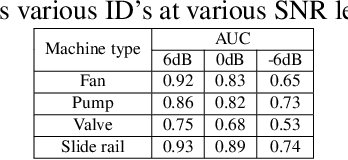
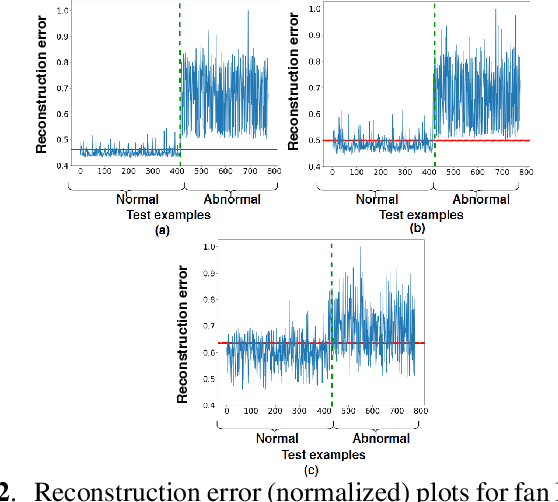
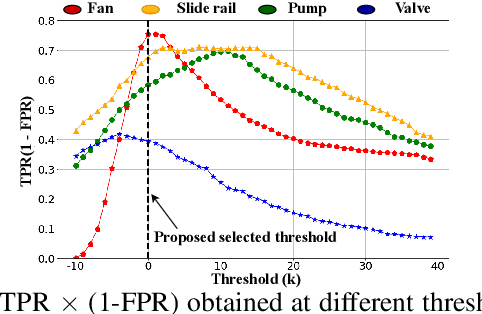
This paper presents an autoencoder based unsupervised approach to identify anomaly in an industrial machine using sounds produced by the machine. The proposed framework is trained using log-melspectrogram representations of the sound signal. In classification, our hypothesis is that the reconstruction error computed for an abnormal machine is larger than that of the a normal machine, since only normal machine sounds are being used to train the autoencoder. A threshold is chosen to discriminate between normal and abnormal machines. However, the threshold changes as surrounding conditions vary. To select an appropriate threshold irrespective of the surrounding, we propose a scene classification framework, which can classify the underlying surrounding. Hence, the threshold can be selected adaptively irrespective of the surrounding. The experiment evaluation is performed on MIMII dataset for industrial machines namely fan, pump, valve and slide rail. Our experiment analysis shows that utilizing adaptive threshold, the performance improves significantly as that obtained using the fixed threshold computed for a given surrounding only.
Multiscale CNN based Deep Metric Learning for Bioacoustic Classification: Overcoming Training Data Scarcity Using Dynamic Triplet Loss
Mar 27, 2019
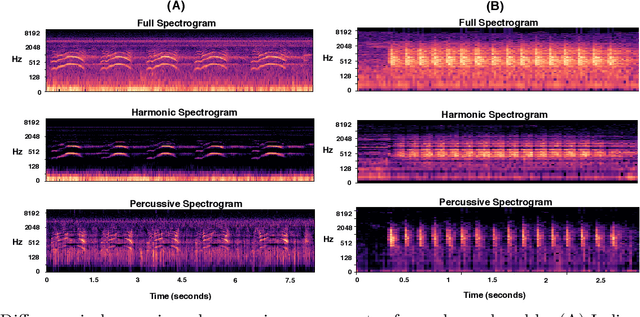

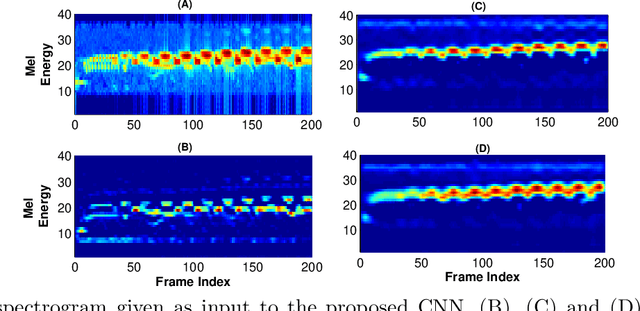
This paper proposes multiscale convolutional neural network (CNN)-based deep metric learning for bioacoustic classification, under low training data conditions. The proposed CNN is characterized by the utilization of four different filter sizes at each level to analyze input feature maps. This multiscale nature helps in describing different bioacoustic events effectively: smaller filters help in learning the finer details of bioacoustic events, whereas, larger filters help in analyzing a larger context leading to global details. A dynamic triplet loss is employed in the proposed CNN architecture to learn a transformation from the input space to the embedding space, where classification is performed. The triplet loss helps in learning this transformation by analyzing three examples, referred to as triplets, at a time where intra-class distance is minimized while maximizing the inter-class separation by a dynamically increasing margin. The number of possible triplets increases cubically with the dataset size, making triplet loss more suitable than the softmax cross-entropy loss in low training data conditions. Experiments on three different publicly available datasets show that the proposed framework performs better than existing bioacoustic classification frameworks. Experimental results also confirm the superiority of the triplet loss over the cross-entropy loss in low training data conditions
Directional Embedding Based Semi-supervised Framework For Bird Vocalization Segmentation
Feb 26, 2019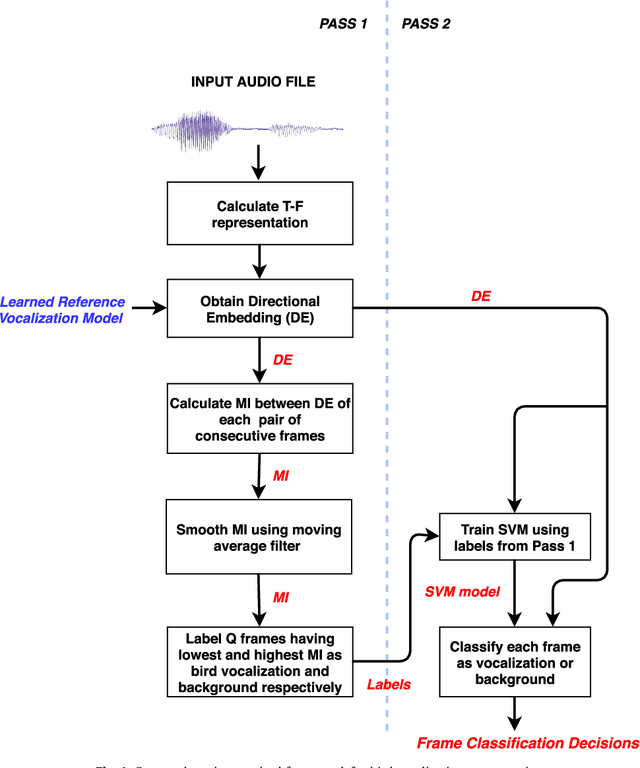
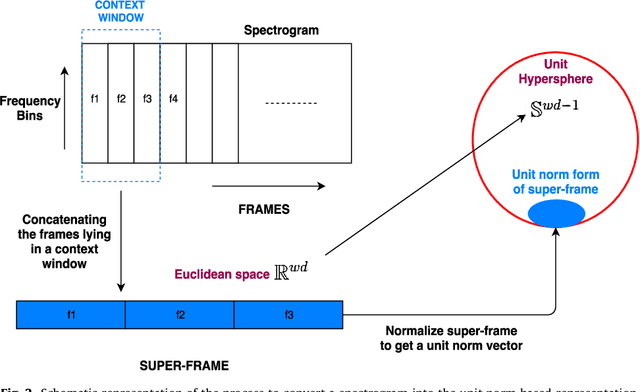
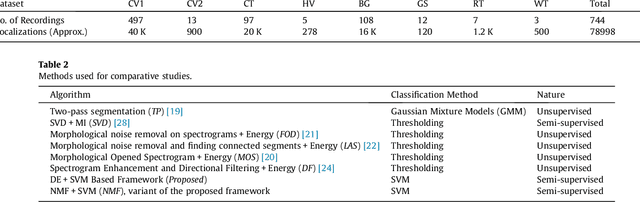
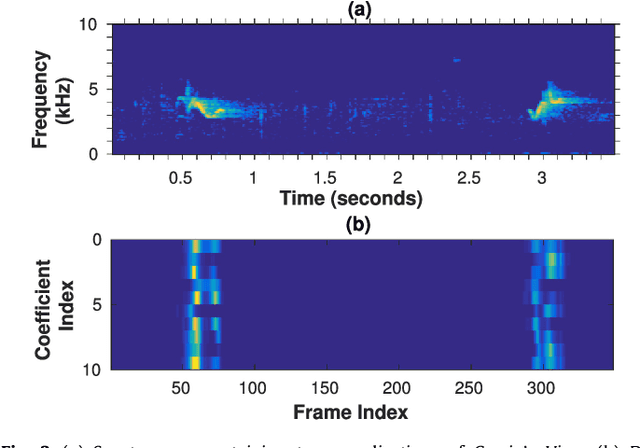
This paper proposes a data-efficient, semi-supervised, two-pass framework for segmenting bird vocalizations. The framework utilizes a binary classification model to categorize frames of an input audio recording into the background or bird vocalization. The first pass of the framework automatically generates training labels from the input recording itself, while model training and classification is done during the second pass. The proposed framework utilizes a reference directional model for obtaining a feature representation called directional embeddings (DE). This reference directional model acts as an acoustic model for bird vocalizations and is obtained using the mixtures of Von-Mises Fisher distribution (moVMF). The proposed DE space only contains information about bird vocalizations, while no information about the background disturbances is reflected. The framework employs supervised information only for obtaining the reference directional model and avoids the background modeling. Hence, it can be regarded as semi-supervised in nature. The proposed framework is tested on approximately 79000 vocalizations of seven different bird species. The performance of the framework is also analyzed in the presence of noise at different SNRs. Experimental results convey that the proposed framework performs better than the existing bird vocalization segmentation methods.
Conv-codes: Audio Hashing For Bird Species Classification
Feb 07, 2019
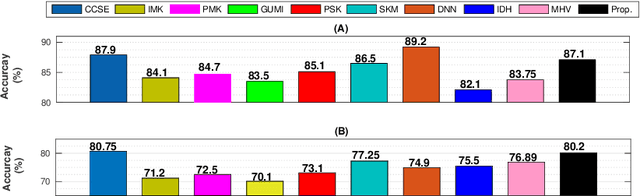
In this work, we propose a supervised, convex representation based audio hashing framework for bird species classification. The proposed framework utilizes archetypal analysis, a matrix factorization technique, to obtain convex-sparse representations of a bird vocalization. These convex representations are hashed using Bloom filters with non-cryptographic hash functions to obtain compact binary codes, designated as conv-codes. The conv-codes extracted from the training examples are clustered using class-specific k-medoids clustering with Jaccard coefficient as the similarity metric. A hash table is populated using the cluster centers as keys while hash values/slots are pointers to the species identification information. During testing, the hash table is searched to find the species information corresponding to a cluster center that exhibits maximum similarity with the test conv-code. Hence, the proposed framework classifies a bird vocalization in the conv-code space and requires no explicit classifier or reconstruction error calculations. Apart from that, based on min-hash and direct addressing, we also propose a variant of the proposed framework that provides faster and effective classification. The performances of both these frameworks are compared with existing bird species classification frameworks on the audio recordings of 50 different bird species.