 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Embedding Based Semi-supervised Framework For Bird Vocalization Segmentation
Paper and Code
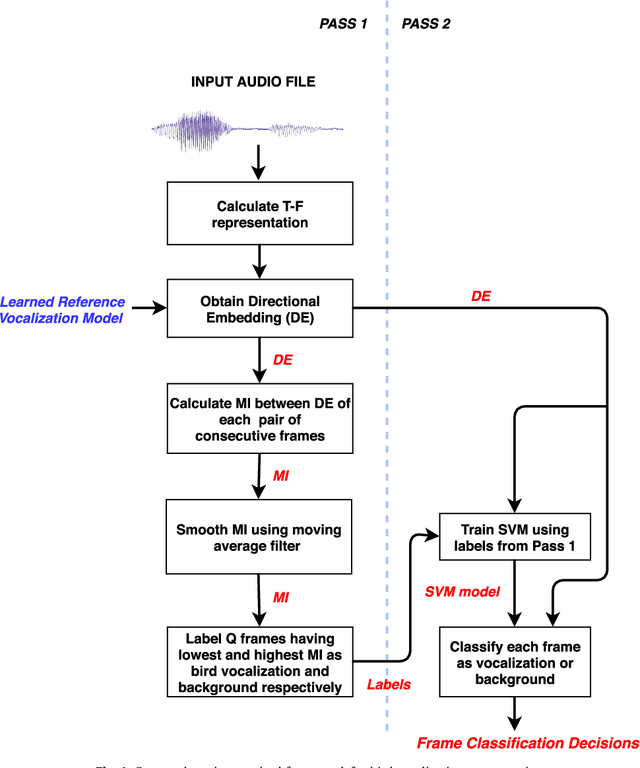
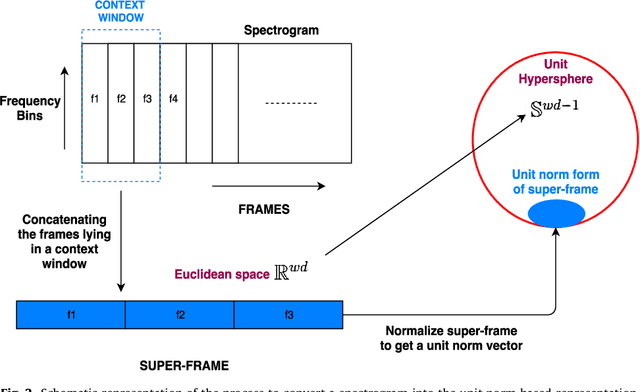
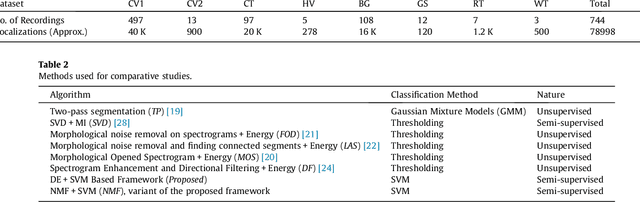
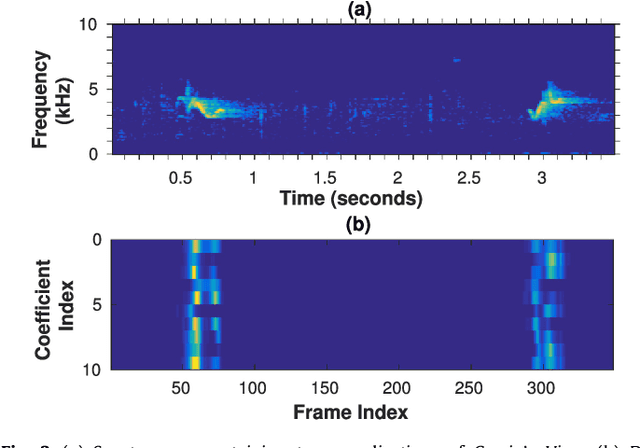
This paper proposes a data-efficient, semi-supervised, two-pass framework for segmenting bird vocalizations. The framework utilizes a binary classification model to categorize frames of an input audio recording into the background or bird vocalization. The first pass of the framework automatically generates training labels from the input recording itself, while model training and classification is done during the second pass. The proposed framework utilizes a reference directional model for obtaining a feature representation called directional embeddings (DE). This reference directional model acts as an acoustic model for bird vocalizations and is obtained using the mixtures of Von-Mises Fisher distribution (moVMF). The proposed DE space only contains information about bird vocalizations, while no information about the background disturbances is reflected. The framework employs supervised information only for obtaining the reference directional model and avoids the background modeling. Hence, it can be regarded as semi-supervised in nature. The proposed framework is tested on approximately 79000 vocalizations of seven different bird species. The performance of the framework is also analyzed in the presence of noise at different SNRs. Experimental results convey that the proposed framework performs better than the existing bird vocalization segmentation methods.