 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedFace: Collaborative Learning of Face Recognition Model
Apr 07, 2021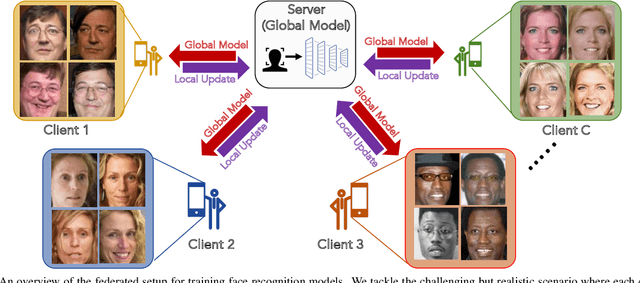
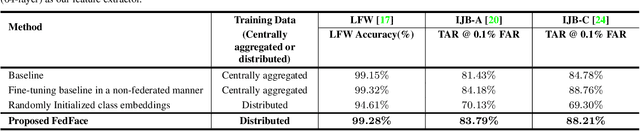
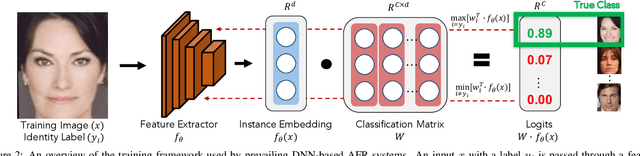

DNN-based face recognition models require large centrally aggregated face datasets for training. However, due to the growing data privacy concerns and legal restrictions, accessing and sharing face datasets has become exceedingly difficult. We propose FedFace, a federated learning (FL) framework for collaborative learning of face recognition models in a privacy preserving manner. FedFace utilizes the face images available on multiple clients to learn an accurate and generalizable face recognition model where the face images stored at each client are neither shared with other clients nor the central host. We tackle the a challenging and yet realistic scenario where each client is a mobile device containing face images pertaining to only the owner of the device (one identity per client). Conventional FL algorithms such as FedAvg are not suitable for this setting because they lead to a trivial solution where all the face features collapse into a single point in the embedding space. Our experiments show that FedFace can utilize face images available on 1,000 mobile devices to enhance the performance of a pre-trained face recognition model, CosFace, from a TAR of 81.43% to 83.79% on IJB-A (@ 0.1% FAR). For LFW, the recognition accuracy under the LFW protocol is increased from 99.15% to 99.28%. FedFace is able to do this while ensuring that the face images are never shared between devices or between the device and the server. Our code and pre-trained models will be publicly available.
Lifting 2D StyleGAN for 3D-Aware Face Generation
Nov 26, 2020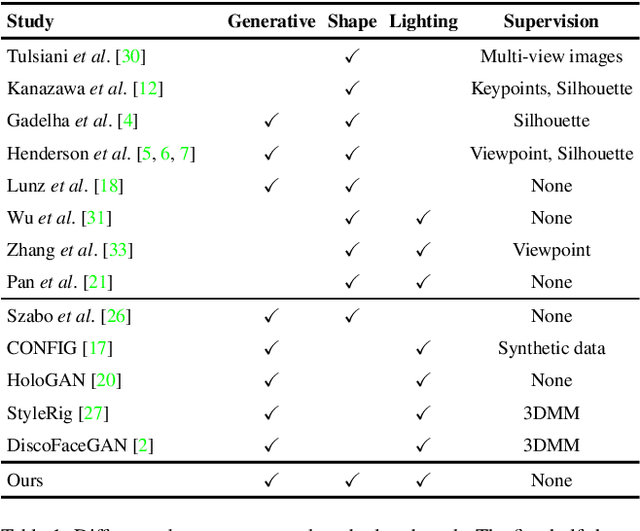
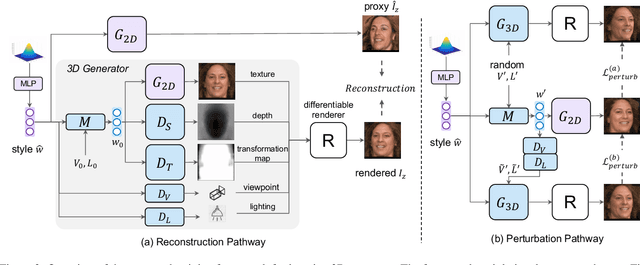
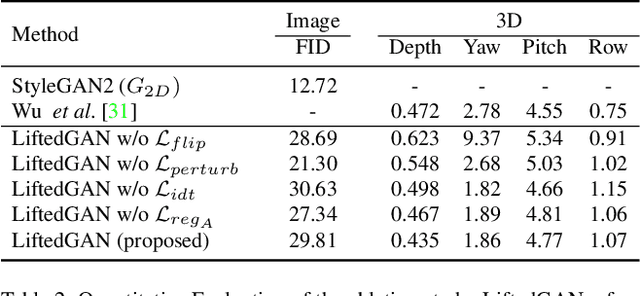

We propose a framework, called LiftedGAN, that disentangles and lifts a pre-trained StyleGAN2 for 3D-aware face generation. Our model is "3D-aware" in the sense that it is able to (1) disentangle the latent space of StyleGAN2 into texture, shape, viewpoint, lighting and (2) generate 3D components for rendering synthetic images. Unlike most previous methods, our method is completely self-supervised, i.e. it neither requires any manual annotation nor 3DMM model for training. Instead, it learns to generate images as well as their 3D components by distilling the prior knowledge in StyleGAN2 with a differentiable renderer. The proposed model is able to output both the 3D shape and texture, allowing explicit pose and lighting control over generated images. Qualitative and quantitative results show the superiority of our approach over existing methods on 3D-controllable GANs in content controllability while generating realistic high quality images.
Child Face Age-Progression via Deep Feature Aging
Mar 17, 2020

Given a gallery of face images of missing children, state-of-the-art face recognition systems fall short in identifying a child (probe) recovered at a later age. We propose a feature aging module that can age-progress deep face features output by a face matcher. In addition, the feature aging module guides age-progression in the image space such that synthesized aged faces can be utilized to enhance longitudinal face recognition performance of any face matcher without requiring any explicit training. For time lapses larger than 10 years (the missing child is found after 10 or more years), the proposed age-progression module improves the closed-set identification accuracy of FaceNet from 16.53% to 21.44% and CosFace from 60.72% to 66.12% on a child celebrity dataset, namely ITWCC. The proposed method also outperforms state-of-the-art approaches with a rank-1 identification rate of 95.91%, compared to 94.91%, on a public aging dataset, FG-NET, and 99.58%, compared to 99.50%, on CACD-VS. These results suggest that aging face features enhances the ability to identify young children who are possible victims of child trafficking or abduction.
Finding Missing Children: Aging Deep Face Features
Nov 19, 2019


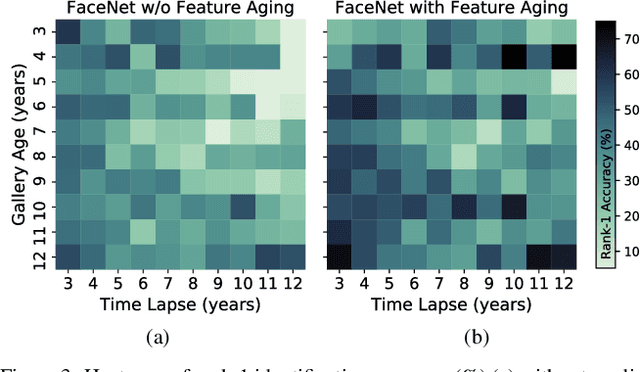
Given a gallery of face images of missing children, state-of-the-art face recognition systems fall short in identifying a child (probe) recovered at a later age. We propose an age-progression module that can age-progress deep face features output by any commodity face matcher. For time lapses larger than 10 years (the missing child is found after 10 or more years), the proposed age-progression module improves the closed-set identification accuracy of FaceNet from 40% to 49.56% and CosFace from 56.88% to 61.25% on a child celebrity dataset, namely ITWCC. The proposed method also outperforms state-of-the-art approaches with a rank-1 identification rate from 94.91% to 95.91% on a public aging dataset, FG-NET, and from 99.50% to 99.58% on CACD-VS. These results suggest that aging face features enhances the ability to identify young children who are possible victims of child trafficking or abduction.
Learning Style Compatibility for Furniture
Dec 09, 2018


When judging style, a key question that often arises is whether or not a pair of objects are compatible with each other. In this paper we investigate how Siamese networks can be used efficiently for assessing the style compatibility between images of furniture items. We show that the middle layers of pretrained CNNs can capture essential information about furniture style, which allows for efficient applications of such networks for this task. We also use a joint image-text embedding method that allows for the querying of stylistically compatible furniture items, along with additional attribute constraints based on text. To evaluate our methods, we collect and present a large scale dataset of images of furniture of different style categories accompanied by text attributes.
VGR-Net: A View Invariant Gait Recognition Network
Oct 13, 2017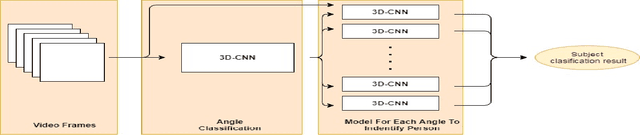
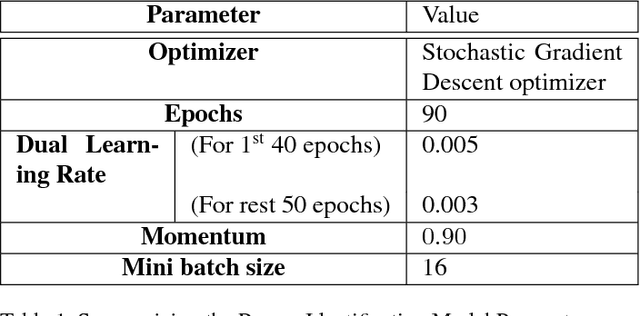
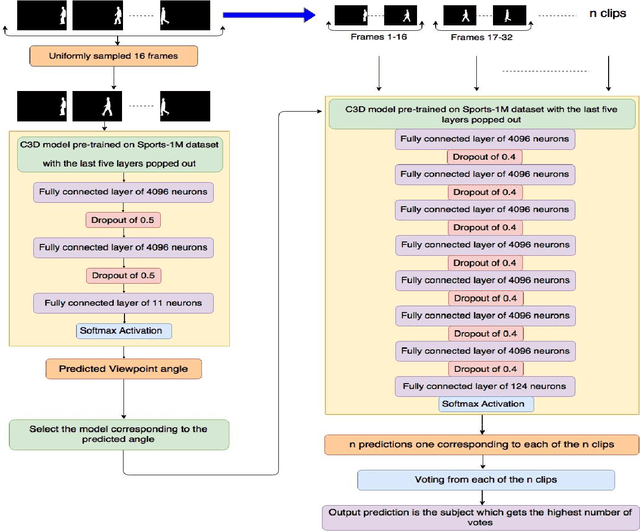
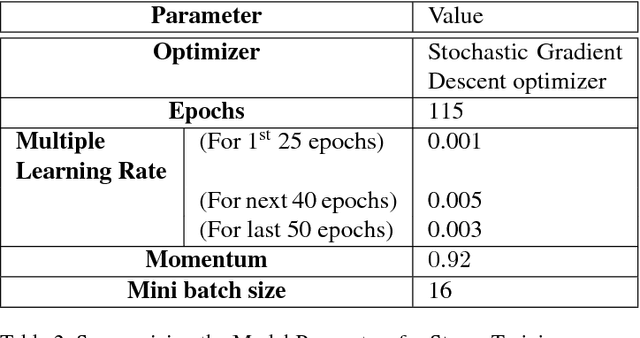
Biometric identification systems have become immensely popular and important because of their high reliability and efficiency. However person identification at a distance, still remains a challenging problem. Gait can be seen as an essential biometric feature for human recognition and identification. It can be easily acquired from a distance and does not require any user cooperation thus making it suitable for surveillance. But the task of recognizing an individual using gait can be adversely affected by varying view points making this task more and more challenging. Our proposed approach tackles this problem by identifying spatio-temporal features and performing extensive experimentation and training mechanism. In this paper, we propose a 3-D Convolution Deep Neural Network for person identification using gait under multiple view. It is a 2-stage network, in which we have a classification network that initially identifies the viewing point angle. After that another set of networks (one for each angle) has been trained to identify the person under a particular viewing angle. We have tested this network over CASIA-B publicly available database and have achieved state-of-the-art results. The proposed system is much more efficient in terms of time and space and performing better for almost all angles.