 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
MUNCH: Modelling Unique 'N Controllable Heads
Oct 04, 2023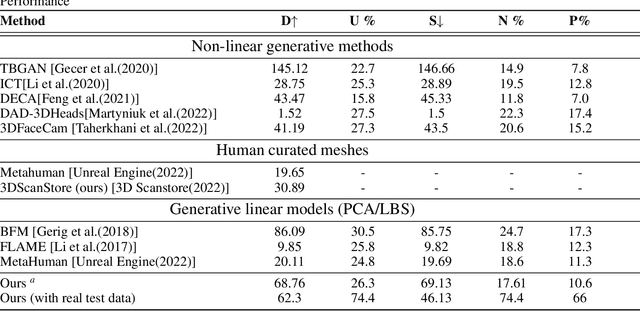
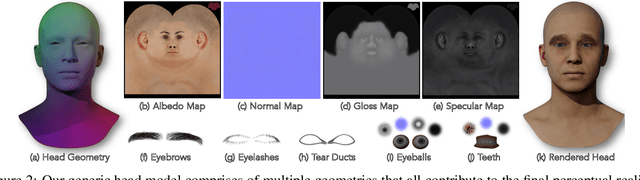
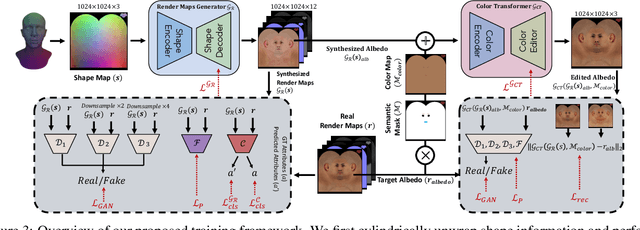

The automated generation of 3D human heads has been an intriguing and challenging task for computer vision researchers. Prevailing methods synthesize realistic avatars but with limited control over the diversity and quality of rendered outputs and suffer from limited correlation between shape and texture of the character. We propose a method that offers quality, diversity, control, and realism along with explainable network design, all desirable features to game-design artists in the domain. First, our proposed Geometry Generator identifies disentangled latent directions and generate novel and diverse samples. A Render Map Generator then learns to synthesize multiply high-fidelty physically-based render maps including Albedo, Glossiness, Specular, and Normals. For artists preferring fine-grained control over the output, we introduce a novel Color Transformer Model that allows semantic color control over generated maps. We also introduce quantifiable metrics called Uniqueness and Novelty and a combined metric to test the overall performance of our model. Demo for both shapes and textures can be found: https://munch-seven.vercel.app/. We will release our model along with the synthetic dataset.
AdvBiom: Adversarial Attacks on Biometric Matchers
Jan 10, 2023With the advent of deep learning models, face recognition systems have achieved impressive recognition rates. The workhorses behind this success are Convolutional Neural Networks (CNNs) and the availability of large training datasets. However, we show that small human-imperceptible changes to face samples can evade most prevailing face recognition systems. Even more alarming is the fact that the same generator can be extended to other traits in the future. In this work, we present how such a generator can be trained and also extended to other biometric modalities, such as fingerprint recognition systems.
Robustness-via-Synthesis: Robust Training with Generative Adversarial Perturbations
Aug 22, 2021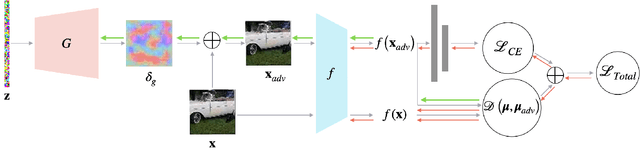
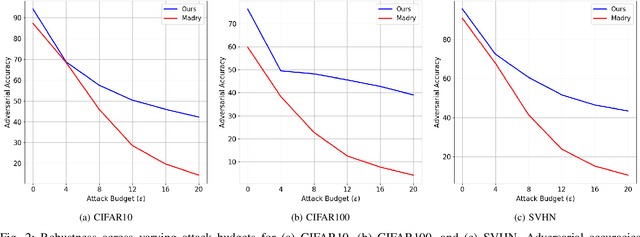
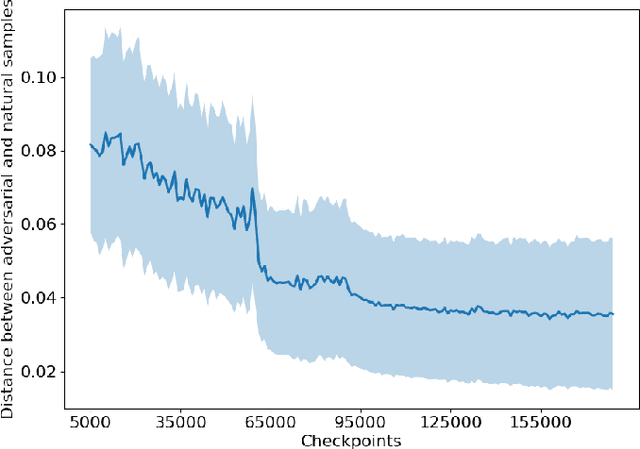
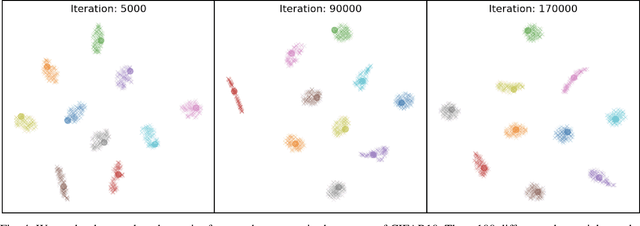
Upon the discovery of adversarial attacks, robust models have become obligatory for deep learning-based systems. Adversarial training with first-order attacks has been one of the most effective defenses against adversarial perturbations to this day. The majority of the adversarial training approaches focus on iteratively perturbing each pixel with the gradient of the loss function with respect to the input image. However, the adversarial training with gradient-based attacks lacks diversity and does not generalize well to natural images and various attacks. This study presents a robust training algorithm where the adversarial perturbations are automatically synthesized from a random vector using a generator network. The classifier is trained with cross-entropy loss regularized with the optimal transport distance between the representations of the natural and synthesized adversarial samples. Unlike prevailing generative defenses, the proposed one-step attack generation framework synthesizes diverse perturbations without utilizing gradient of the classifier's loss. Experimental results show that the proposed approach attains comparable robustness with various gradient-based and generative robust training techniques on CIFAR10, CIFAR100, and SVHN datasets. In addition, compared to the baselines, the proposed robust training framework generalizes well to the natural samples. Code and trained models will be made publicly available.
Biometrics: Trust, but Verify
May 31, 2021
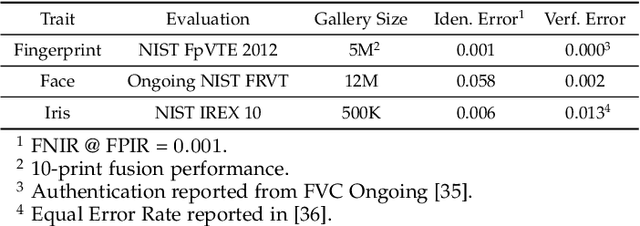
Over the past two decades, biometric recognition has exploded into a plethora of different applications around the globe. This proliferation can be attributed to the high levels of authentication accuracy and user convenience that biometric recognition systems afford end-users. However, in-spite of the success of biometric recognition systems, there are a number of outstanding problems and concerns pertaining to the various sub-modules of biometric recognition systems that create an element of mistrust in their use - both by the scientific community and also the public at large. Some of these problems include: i) questions related to system recognition performance, ii) security (spoof attacks, adversarial attacks, template reconstruction attacks and demographic information leakage), iii) uncertainty over the bias and fairness of the systems to all users, iv) explainability of the seemingly black-box decisions made by most recognition systems, and v) concerns over data centralization and user privacy. In this paper, we provide an overview of each of the aforementioned open-ended challenges. We survey work that has been conducted to address each of these concerns and highlight the issues requiring further attention. Finally, we provide insights into how the biometric community can address core biometric recognition systems design issues to better instill trust, fairness, and security for all.
Unified Detection of Digital and Physical Face Attacks
Apr 05, 2021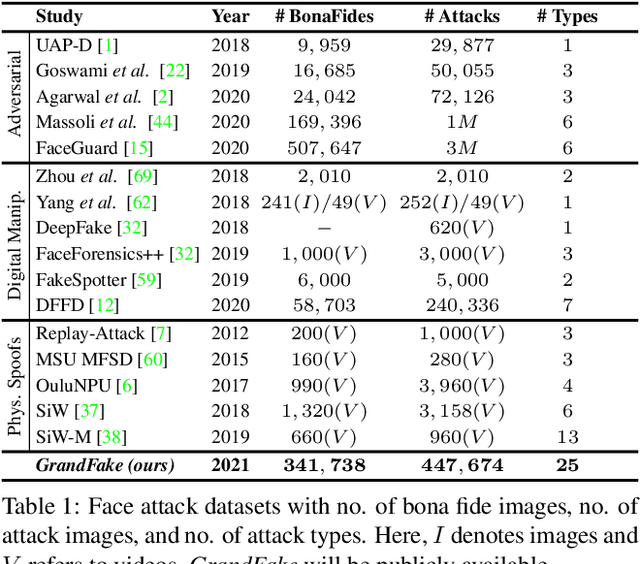
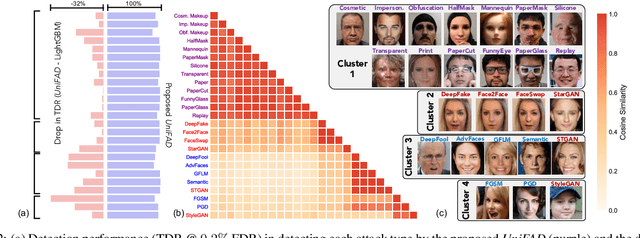
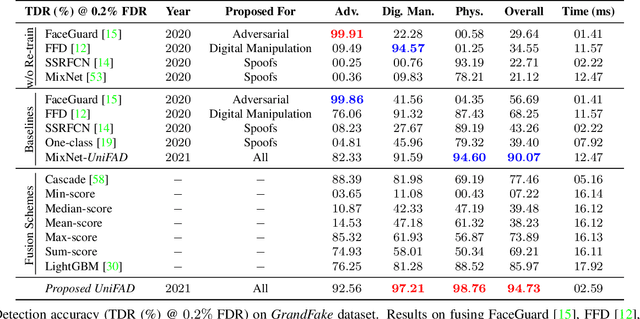
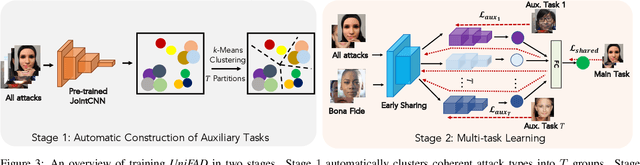
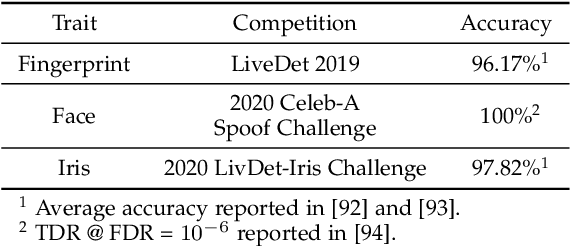
State-of-the-art defense mechanisms against face attacks achieve near perfect accuracies within one of three attack categories, namely adversarial, digital manipulation, or physical spoofs, however, they fail to generalize well when tested across all three categories. Poor generalization can be attributed to learning incoherent attacks jointly. To overcome this shortcoming, we propose a unified attack detection framework, namely UniFAD, that can automatically cluster 25 coherent attack types belonging to the three categories. Using a multi-task learning framework along with k-means clustering, UniFAD learns joint representations for coherent attacks, while uncorrelated attack types are learned separately. Proposed UniFAD outperforms prevailing defense methods and their fusion with an overall TDR = 94.73% @ 0.2% FDR on a large fake face dataset consisting of 341K bona fide images and 448K attack images of 25 types across all 3 categories. Proposed method can detect an attack within 3 milliseconds on a Nvidia 2080Ti. UniFAD can also identify the attack types and categories with 75.81% and 97.37% accuracies, respectively.
FaceGuard: A Self-Supervised Defense Against Adversarial Face Images
Nov 28, 2020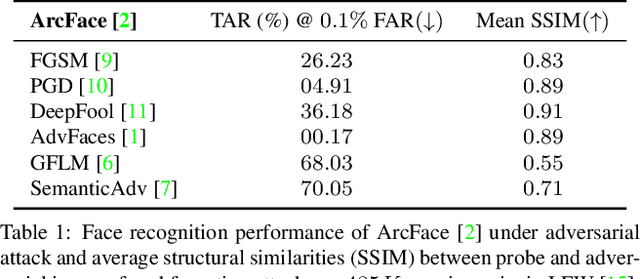

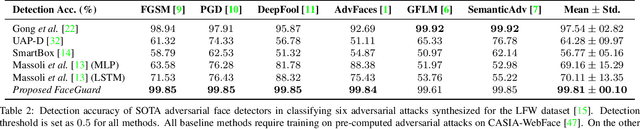
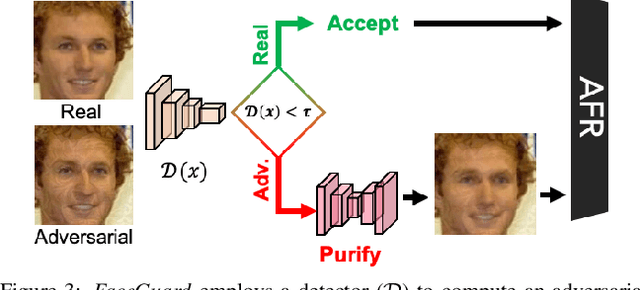
Prevailing defense mechanisms against adversarial face images tend to overfit to the adversarial perturbations in the training set and fail to generalize to unseen adversarial attacks. We propose a new self-supervised adversarial defense framework, namely FaceGuard, that can automatically detect, localize, and purify a wide variety of adversarial faces without utilizing pre-computed adversarial training samples. During training, FaceGuard automatically synthesizes challenging and diverse adversarial attacks, enabling a classifier to learn to distinguish them from real faces and a purifier attempts to remove the adversarial perturbations in the image space. Experimental results on LFW dataset show that FaceGuard can achieve 99.81% detection accuracy on six unseen adversarial attack types. In addition, the proposed method can enhance the face recognition performance of ArcFace from 34.27% TAR @ 0.1% FAR under no defense to 77.46% TAR @ 0.1% FAR.
Infant-ID: Fingerprints for Global Good
Oct 07, 2020
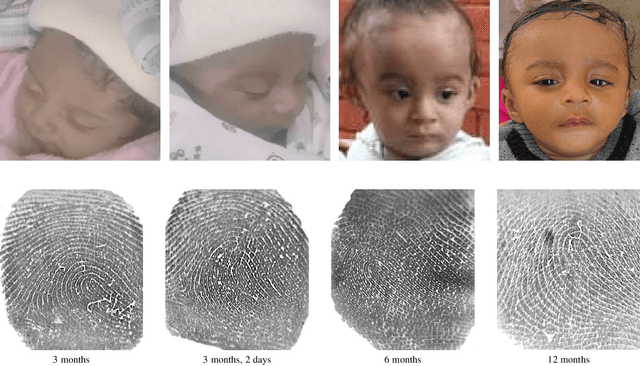
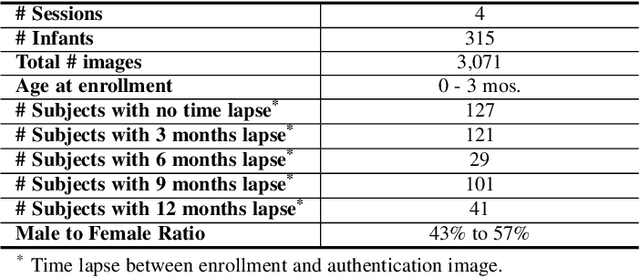
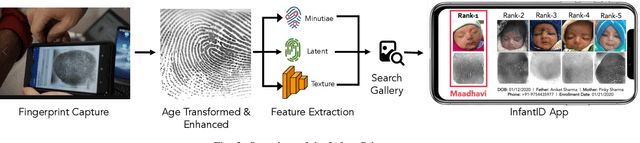
In many of the least developed and developing countries, a multitude of infants continue to suffer and die from vaccine-preventable diseases and malnutrition. Lamentably, the lack of official identification documentation makes it exceedingly difficult to track which infants have been vaccinated and which infants have received nutritional supplements. Answering these questions could prevent this infant suffering and premature death around the world. To that end, we propose Infant-Prints, an end-to-end, low-cost, infant fingerprint recognition system. Infant-Prints is comprised of our (i) custom built, compact, low-cost (85 USD), high-resolution (1,900 ppi), ergonomic fingerprint reader, and (ii) high-resolution infant fingerprint matcher. To evaluate the efficacy of Infant-Prints, we collected a longitudinal infant fingerprint database captured in 4 different sessions over a 12-month time span (December 2018 to January 2020), from 315 infants at the Saran Ashram Hospital, a charitable hospital in Dayalbagh, Agra, India. Our experimental results demonstrate, for the first time, that Infant-Prints can deliver accurate and reliable recognition (over time) of infants enrolled between the ages of 2-3 months, in time for effective delivery of vaccinations, healthcare, and nutritional supplements (TAR=95.2% @ FAR = 1.0% for infants aged 8-16 weeks at enrollment and authenticated 3 months later).
Look Locally Infer Globally: A Generalizable Face Anti-Spoofing Approach
Jun 15, 2020
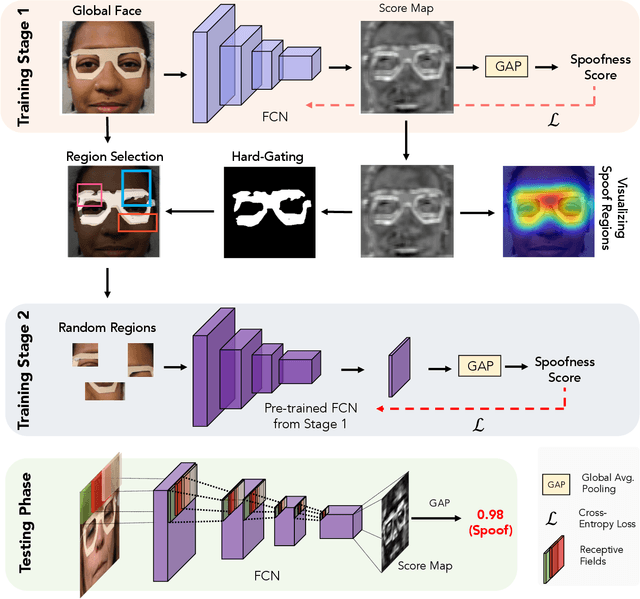
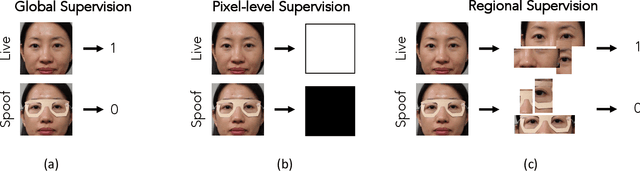

State-of-the-art spoof detection methods tend to overfit to the spoof types seen during training and fail to generalize to unknown spoof types. Given that face anti-spoofing is inherently a local task, we propose a face anti-spoofing framework, namely Self-Supervised Regional Fully Convolutional Network (SSR-FCN), that is trained to learn local discriminative cues from a face image in a self-supervised manner. The proposed framework improves generalizability while maintaining the computational efficiency of holistic face anti-spoofing approaches (< 4 ms on a Nvidia GTX 1080Ti GPU). The proposed method is interpretable since it localizes which parts of the face are labeled as spoofs. Experimental results show that SSR-FCN can achieve TDR = 65% @ 2.0% FDR when evaluated on a dataset comprising of 13 different spoof types under unknown attacks while achieving competitive performances under standard benchmark datasets (Oulu-NPU, CASIA-MFSD, and Replay-Attack).
Child Face Age-Progression via Deep Feature Aging
Mar 17, 2020
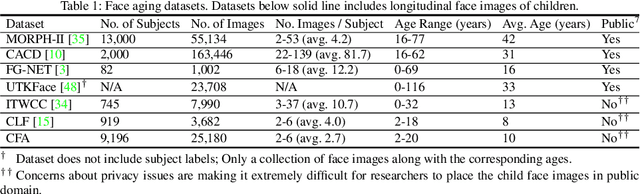

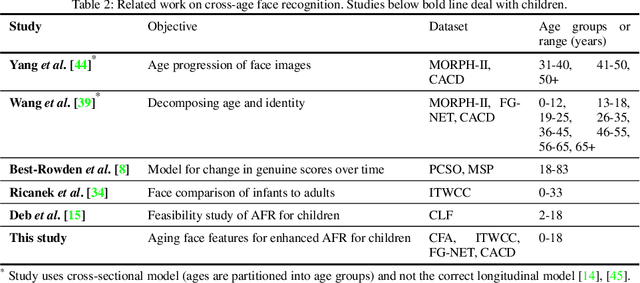
Given a gallery of face images of missing children, state-of-the-art face recognition systems fall short in identifying a child (probe) recovered at a later age. We propose a feature aging module that can age-progress deep face features output by a face matcher. In addition, the feature aging module guides age-progression in the image space such that synthesized aged faces can be utilized to enhance longitudinal face recognition performance of any face matcher without requiring any explicit training. For time lapses larger than 10 years (the missing child is found after 10 or more years), the proposed age-progression module improves the closed-set identification accuracy of FaceNet from 16.53% to 21.44% and CosFace from 60.72% to 66.12% on a child celebrity dataset, namely ITWCC. The proposed method also outperforms state-of-the-art approaches with a rank-1 identification rate of 95.91%, compared to 94.91%, on a public aging dataset, FG-NET, and 99.58%, compared to 99.50%, on CACD-VS. These results suggest that aging face features enhances the ability to identify young children who are possible victims of child trafficking or abduction.