 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Conversion from Mild Cognitive Impairment to Alzheimer's Disease using Latent Space Manipulation
Nov 16, 2021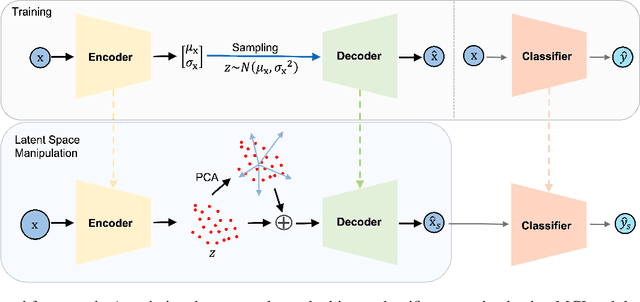
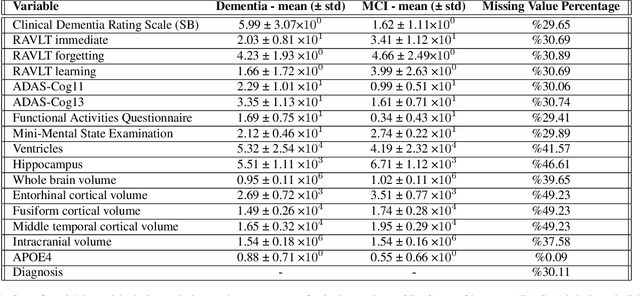
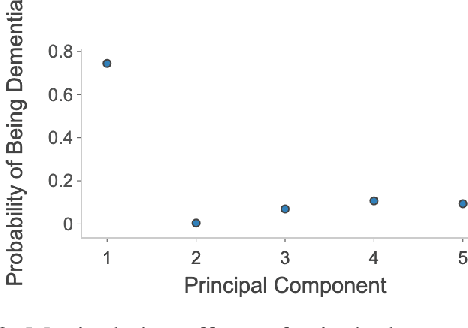
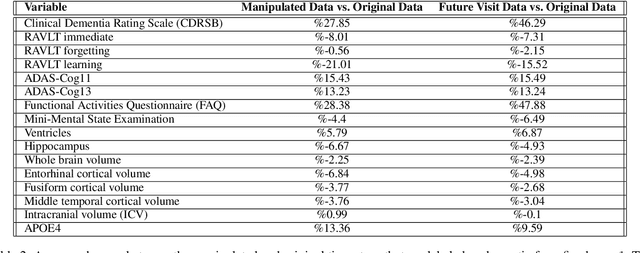
Alzheimer's disease is the most common cause of dementia that affects millions of lives worldwide. Investigating the underlying causes and risk factors of Alzheimer's disease is essential to prevent its progression. Mild Cognitive Impairment (MCI) is considered an intermediate stage before Alzheimer's disease. Early prediction of the conversion from the MCI to Alzheimer's is crucial to take necessary precautions for decelerating the progression and developing suitable treatments. In this study, we propose a deep learning framework to discover the variables which are identifiers of the conversion from MCI to Alzheimer's disease. In particular, the latent space of a variational auto-encoder network trained with the MCI and Alzheimer's patients is manipulated to obtain the significant attributes and decipher their behavior that leads to the conversion from MCI to Alzheimer's disease. By utilizing a generative decoder and the dimensions that lead to the Alzheimer's diagnosis, we generate synthetic dementia patients from MCI patients in the dataset. Experimental results show promising quantitative and qualitative results on one of the most extensive and commonly used Alzheimer's disease neuroimaging datasets in literature.
Robustness-via-Synthesis: Robust Training with Generative Adversarial Perturbations
Aug 22, 2021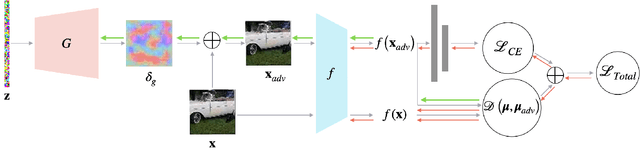
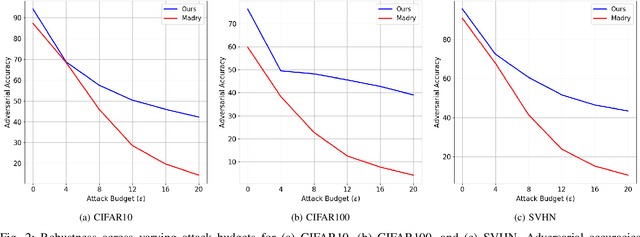
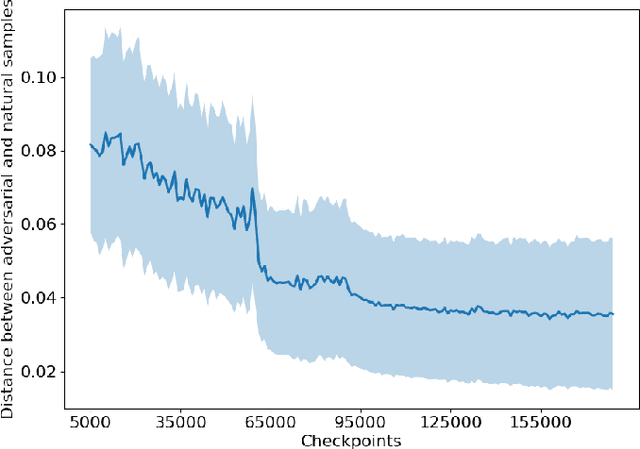
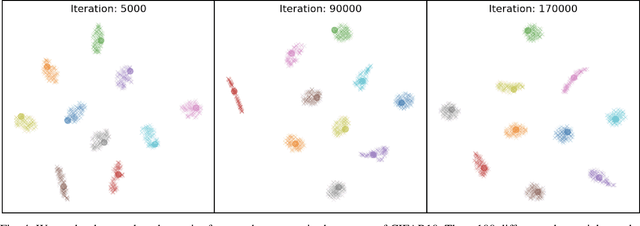
Upon the discovery of adversarial attacks, robust models have become obligatory for deep learning-based systems. Adversarial training with first-order attacks has been one of the most effective defenses against adversarial perturbations to this day. The majority of the adversarial training approaches focus on iteratively perturbing each pixel with the gradient of the loss function with respect to the input image. However, the adversarial training with gradient-based attacks lacks diversity and does not generalize well to natural images and various attacks. This study presents a robust training algorithm where the adversarial perturbations are automatically synthesized from a random vector using a generator network. The classifier is trained with cross-entropy loss regularized with the optimal transport distance between the representations of the natural and synthesized adversarial samples. Unlike prevailing generative defenses, the proposed one-step attack generation framework synthesizes diverse perturbations without utilizing gradient of the classifier's loss. Experimental results show that the proposed approach attains comparable robustness with various gradient-based and generative robust training techniques on CIFAR10, CIFAR100, and SVHN datasets. In addition, compared to the baselines, the proposed robust training framework generalizes well to the natural samples. Code and trained models will be made publicly available.
Subspace Network: Deep Multi-Task Censored Regression for Modeling Neurodegenerative Diseases
Mar 01, 2018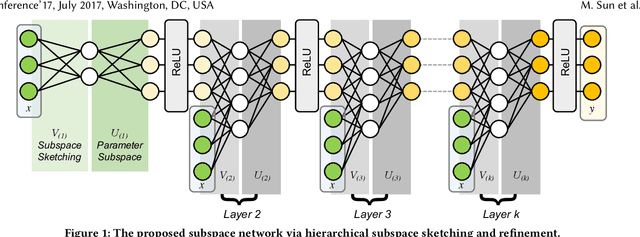

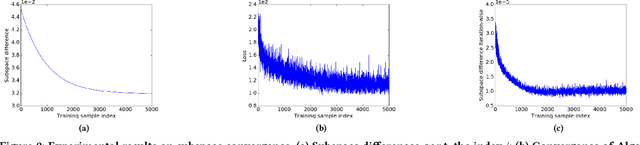
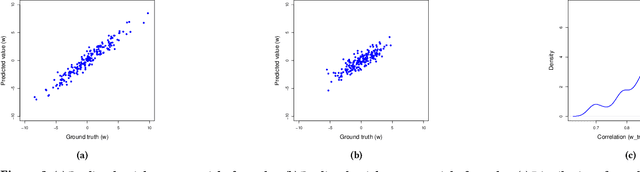
Over the past decade a wide spectrum of machine learning models have been developed to model the neurodegenerative diseases, associating biomarkers, especially non-intrusive neuroimaging markers, with key clinical scores measuring the cognitive status of patients. Multi-task learning (MTL) has been commonly utilized by these studies to address high dimensionality and small cohort size challenges. However, most existing MTL approaches are based on linear models and suffer from two major limitations: 1) they cannot explicitly consider upper/lower bounds in these clinical scores; 2) they lack the capability to capture complicated non-linear interactions among the variables. In this paper, we propose Subspace Network, an efficient deep modeling approach for non-linear multi-task censored regression. Each layer of the subspace network performs a multi-task censored regression to improve upon the predictions from the last layer via sketching a low-dimensional subspace to perform knowledge transfer among learning tasks. Under mild assumptions, for each layer the parametric subspace can be recovered using only one pass of training data. Empirical results demonstrate that the proposed subspace network quickly picks up the correct parameter subspaces, and outperforms state-of-the-arts in predicting neurodegenerative clinical scores using information in brain imaging.
Asynchronous Multi-Task Learning
Sep 30, 2016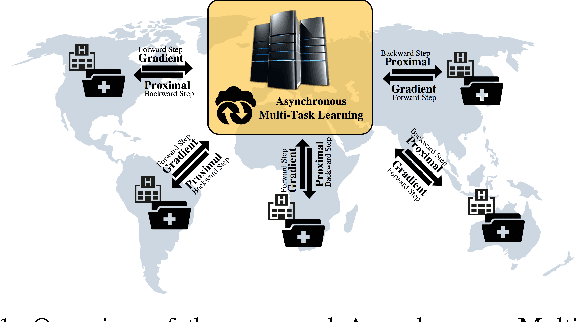
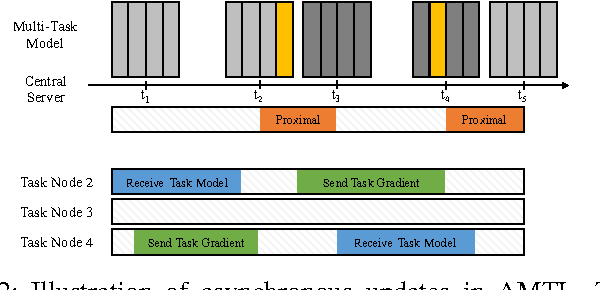
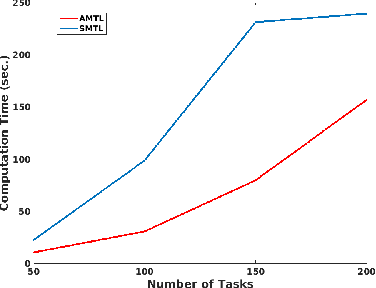
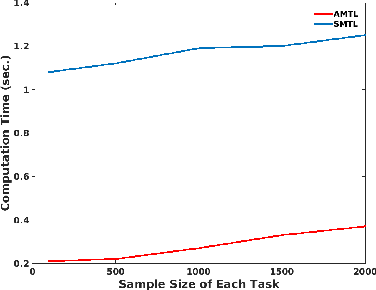
Many real-world machine learning applications involve several learning tasks which are inter-related. For example, in healthcare domain, we need to learn a predictive model of a certain disease for many hospitals. The models for each hospital may be different because of the inherent differences in the distributions of the patient populations. However, the models are also closely related because of the nature of the learning tasks modeling the same disease. By simultaneously learning all the tasks, multi-task learning (MTL) paradigm performs inductive knowledge transfer among tasks to improve the generalization performance. When datasets for the learning tasks are stored at different locations, it may not always be feasible to transfer the data to provide a data-centralized computing environment due to various practical issues such as high data volume and privacy. In this paper, we propose a principled MTL framework for distributed and asynchronous optimization to address the aforementioned challenges. In our framework, gradient update does not wait for collecting the gradient information from all the tasks. Therefore, the proposed method is very efficient when the communication delay is too high for some task nodes. We show that many regularized MTL formulations can benefit from this framework, including the low-rank MTL for shared subspace learning. Empirical studies on both synthetic and real-world datasets demonstrate the efficiency and effectiveness of the proposed framework.
Similarity Learning via Adaptive Regression and Its Application to Image Retrieval
Dec 06, 2015
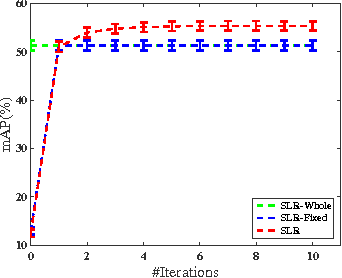
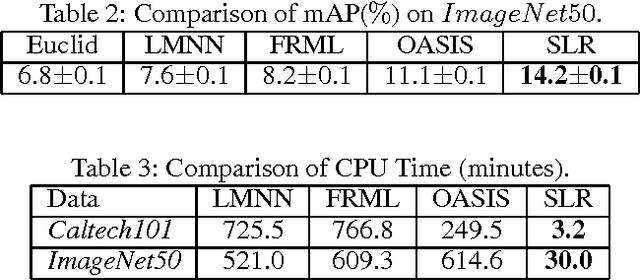
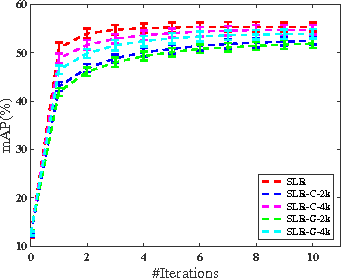
We study the problem of similarity learning and its application to image retrieval with large-scale data. The similarity between pairs of images can be measured by the distances between their high dimensional representations, and the problem of learning the appropriate similarity is often addressed by distance metric learning. However, distance metric learning requires the learned metric to be a PSD matrix, which is computational expensive and not necessary for retrieval ranking problem. On the other hand, the bilinear model is shown to be more flexible for large-scale image retrieval task, hence, we adopt it to learn a matrix for estimating pairwise similarities under the regression framework. By adaptively updating the target matrix in regression, we can mimic the hinge loss, which is more appropriate for similarity learning problem. Although the regression problem can have the closed-form solution, the computational cost can be very expensive. The computational challenges come from two aspects: the number of images can be very large and image features have high dimensionality. We address the first challenge by compressing the data by a randomized algorithm with the theoretical guarantee. For the high dimensional issue, we address it by taking low rank assumption and applying alternating method to obtain the partial matrix, which has a global optimal solution. Empirical studies on real world image datasets (i.e., Caltech and ImageNet) demonstrate the effectiveness and efficiency of the proposed method.