 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
Jan 12, 2025Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short-duration videos or moderately long videos up to dozens of minutes, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset specifically crafted for evaluating tasks on extremely long egocentric video recordings. Leveraging the advanced text processing capabilities of large language models (LLMs), X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs that mirror realistic daily activities in contextually rich scenarios. The video life-log durations span from 23 minutes to 16.4 hours. The evaluation of several baseline systems and multimodal large language models (MLLMs) reveals their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding and underscoring the need for more advanced models.
IREE Oriented Active RIS-Assisted Green communication System with Outdated CSI
Nov 17, 2024



The rapid evolution of communication technologies has spurred a growing demand for energy-efficient network architectures and performance metrics. Active Reconfigurable Intelligent Surfaces (RIS) are emerging as a key component in green network architectures. Compared to passive RIS, active RIS are equipped with amplifiers on each reflecting element, allowing them to simultaneously reflect and amplify signals, thereby overcoming the double multiplicative fading in the phase response, and improving both system coverage and performance. Additionally, the Integrated Relative Energy Efficiency (IREE) metric, as introduced in [1], addresses the dynamic variations in traffic and capacity over time and space, enabling more energy-efficient wireless systems. Building on these advancements, this paper investigates the problem of maximizing IREE in active RIS-assisted green communication systems. However, acquiring perfect Channel State Information (CSI) in practical systems poses significant challenges and costs. To address this, we derive the average achievable rate based on outdated CSI and formulated the corresponding IREE maximization problem, which is solved by jointly optimizing beamforming at both the base station and RIS. Given the non-convex nature of the problem, we propose an Alternating Optimization Successive Approximation (AOSO) algorithm. By applying quadratic transform and relaxation techniques, we simplify the original problem and alternately optimize the beamforming matrices at the base station and RIS. Furthermore, to handle the discrete constraints of the RIS reflection coefficients, we develop a successive approximation method. Experimental results validate our theoretical analysis of the algorithm's convergence , demonstrating the effectiveness of the proposed algorithm and highlighting the superiority of IREE in enhancing the performance of green communication networks.
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022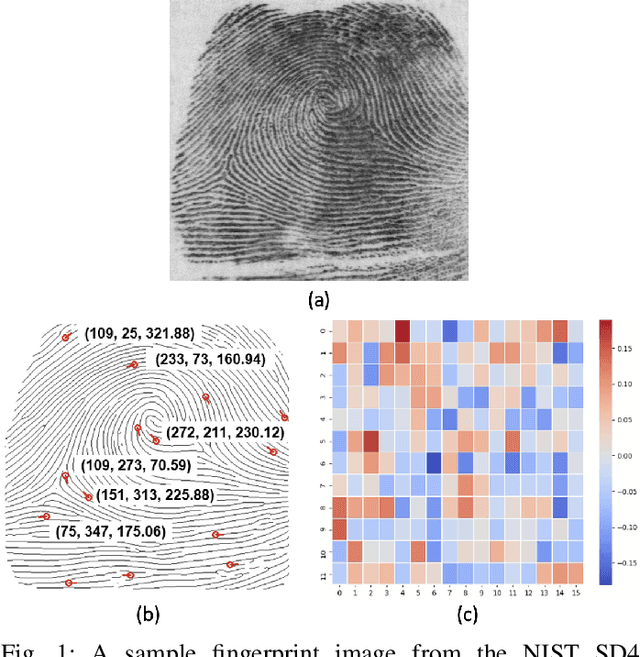

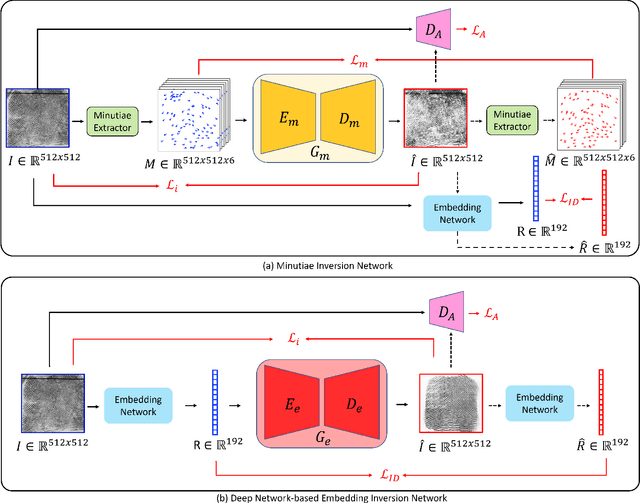

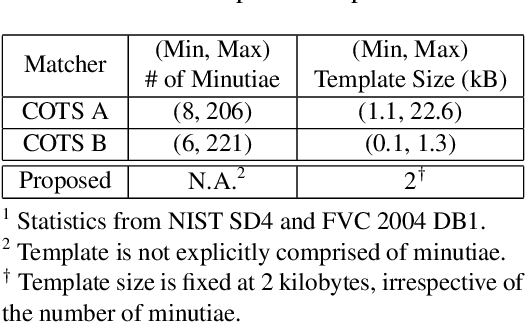
Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.
3D Graph Anatomy Geometry-Integrated Network for Pancreatic Mass Segmentation, Diagnosis, and Quantitative Patient Management
Dec 08, 2020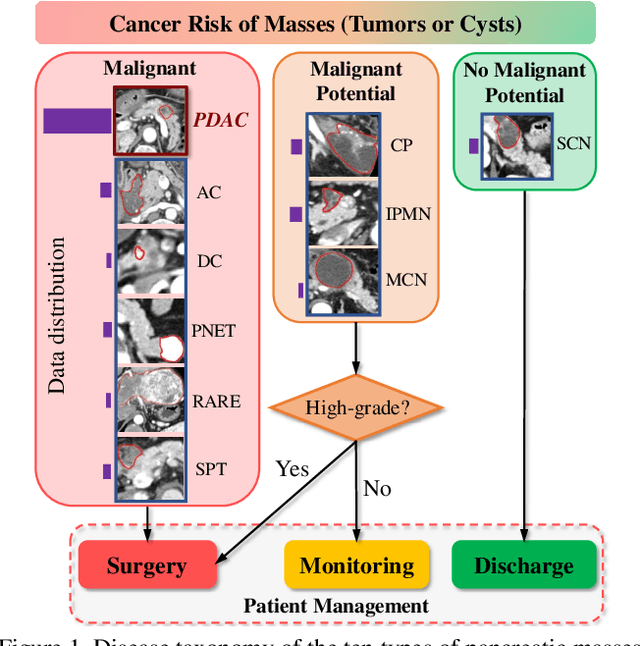

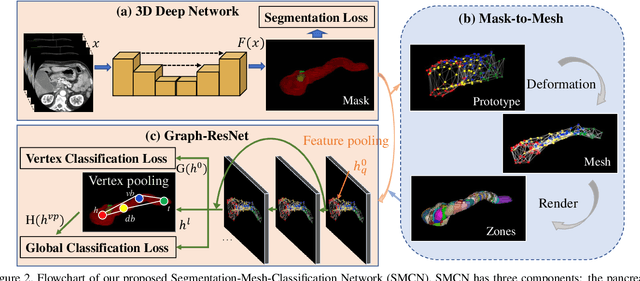

The pancreatic disease taxonomy includes ten types of masses (tumors or cysts)[20,8]. Previous work focuses on developing segmentation or classification methods only for certain mass types. Differential diagnosis of all mass types is clinically highly desirable [20] but has not been investigated using an automated image understanding approach. We exploit the feasibility to distinguish pancreatic ductal adenocarcinoma (PDAC) from the nine other nonPDAC masses using multi-phase CT imaging. Both image appearance and the 3D organ-mass geometry relationship are critical. We propose a holistic segmentation-mesh-classification network (SMCN) to provide patient-level diagnosis, by fully utilizing the geometry and location information, which is accomplished by combining the anatomical structure and the semantic detection-by-segmentation network. SMCN learns the pancreas and mass segmentation task and builds an anatomical correspondence-aware organ mesh model by progressively deforming a pancreas prototype on the raw segmentation mask (i.e., mask-to-mesh). A new graph-based residual convolutional network (Graph-ResNet), whose nodes fuse the information of the mesh model and feature vectors extracted from the segmentation network, is developed to produce the patient-level differential classification results. Extensive experiments on 661 patients' CT scans (five phases per patient) show that SMCN can improve the mass segmentation and detection accuracy compared to the strong baseline method nnUNet (e.g., for nonPDAC, Dice: 0.611 vs. 0.478; detection rate: 89% vs. 70%), achieve similar sensitivity and specificity in differentiating PDAC and nonPDAC as expert radiologists (i.e., 94% and 90%), and obtain results comparable to a multimodality test [20] that combines clinical, imaging, and molecular testing for clinical management of patients.
Infant-ID: Fingerprints for Global Good
Oct 07, 2020
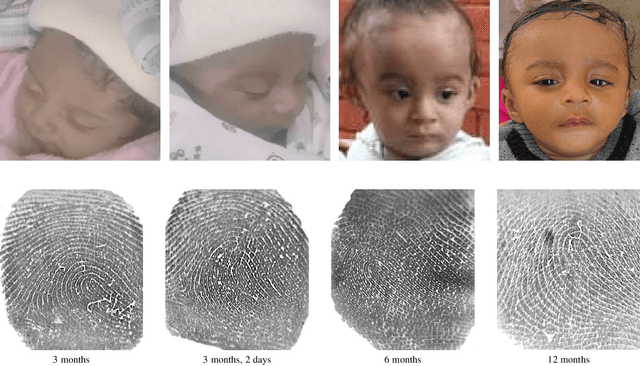
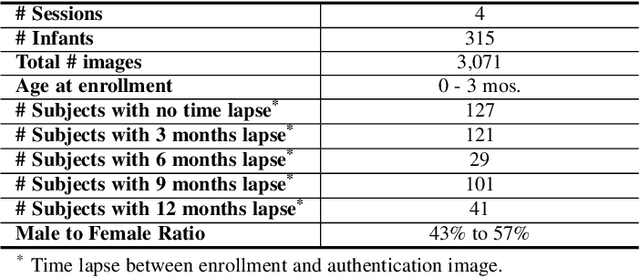
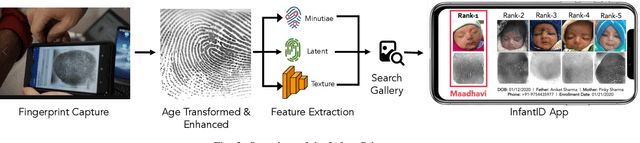
In many of the least developed and developing countries, a multitude of infants continue to suffer and die from vaccine-preventable diseases and malnutrition. Lamentably, the lack of official identification documentation makes it exceedingly difficult to track which infants have been vaccinated and which infants have received nutritional supplements. Answering these questions could prevent this infant suffering and premature death around the world. To that end, we propose Infant-Prints, an end-to-end, low-cost, infant fingerprint recognition system. Infant-Prints is comprised of our (i) custom built, compact, low-cost (85 USD), high-resolution (1,900 ppi), ergonomic fingerprint reader, and (ii) high-resolution infant fingerprint matcher. To evaluate the efficacy of Infant-Prints, we collected a longitudinal infant fingerprint database captured in 4 different sessions over a 12-month time span (December 2018 to January 2020), from 315 infants at the Saran Ashram Hospital, a charitable hospital in Dayalbagh, Agra, India. Our experimental results demonstrate, for the first time, that Infant-Prints can deliver accurate and reliable recognition (over time) of infants enrolled between the ages of 2-3 months, in time for effective delivery of vaccinations, healthcare, and nutritional supplements (TAR=95.2% @ FAR = 1.0% for infants aged 8-16 weeks at enrollment and authenticated 3 months later).
Robust Pancreatic Ductal Adenocarcinoma Segmentation with Multi-Institutional Multi-Phase Partially-Annotated CT Scans
Aug 24, 2020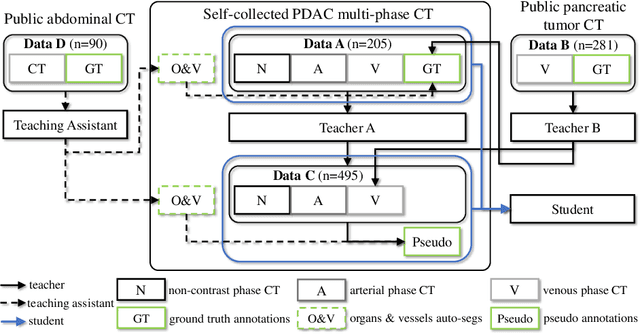
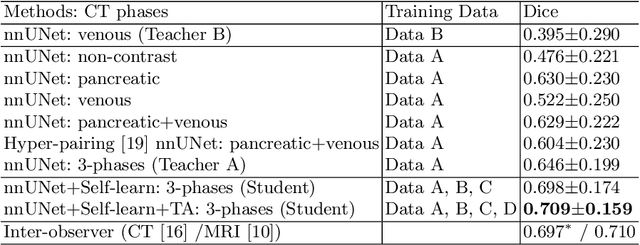
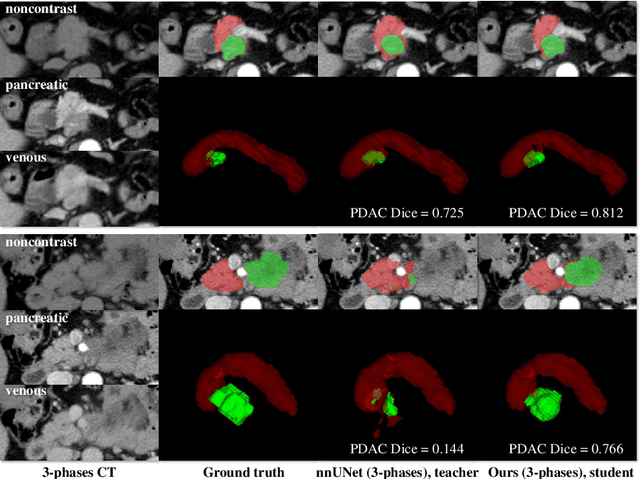
Accurate and automated tumor segmentation is highly desired since it has the great potential to increase the efficiency and reproducibility of computing more complete tumor measurements and imaging biomarkers, comparing to (often partial) human measurements. This is probably the only viable means to enable the large-scale clinical oncology patient studies that utilize medical imaging. Deep learning approaches have shown robust segmentation performances for certain types of tumors, e.g., brain tumors in MRI imaging, when a training dataset with plenty of pixel-level fully-annotated tumor images is available. However, more than often, we are facing the challenge that only (very) limited annotations are feasible to acquire, especially for hard tumors. Pancreatic ductal adenocarcinoma (PDAC) segmentation is one of the most challenging tumor segmentation tasks, yet critically important for clinical needs. Previous work on PDAC segmentation is limited to the moderate amounts of annotated patient images (n<300) from venous or venous+arterial phase CT scans. Based on a new self-learning framework, we propose to train the PDAC segmentation model using a much larger quantity of patients (n~=1,000), with a mix of annotated and un-annotated venous or multi-phase CT images. Pseudo annotations are generated by combining two teacher models with different PDAC segmentation specialties on unannotated images, and can be further refined by a teaching assistant model that identifies associated vessels around the pancreas. A student model is trained on both manual and pseudo annotated multi-phase images. Experiment results show that our proposed method provides an absolute improvement of 6.3% Dice score over the strong baseline of nnUNet trained on annotated images, achieving the performance (Dice = 0.71) similar to the inter-observer variability between radiologists.
Learning a Fixed-Length Fingerprint Representation
Sep 21, 2019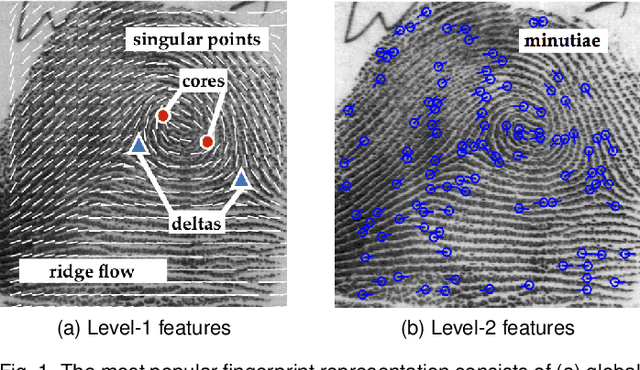


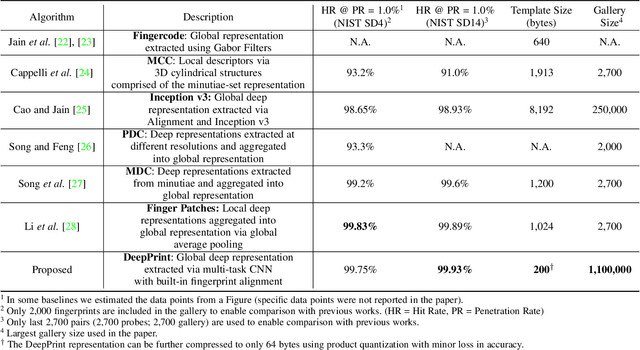
We present DeepPrint, a deep network, which learns to extract fixed-length fingerprint representations of only 200 bytes. DeepPrint incorporates fingerprint domain knowledge, including alignment and minutiae detection, into the deep network architecture to maximize the discriminative power of its representation. The compact, DeepPrint representation has several advantages over the prevailing variable length minutiae representation which (i) requires computationally expensive graph matching techniques, (ii) is difficult to secure using strong encryption schemes (e.g. homomorphic encryption), and (iii) has low discriminative power in poor quality fingerprints where minutiae extraction is unreliable. We benchmark DeepPrint against two top performing COTS SDKs (Verifinger and Innovatrics) from the NIST and FVC evaluations. Coupled with a re-ranking scheme, the DeepPrint rank-1 search accuracy on the NIST SD4 dataset against a gallery of 1.1 million fingerprints is comparable to the top COTS matcher, but it is significantly faster (DeepPrint: 98.80% in 0.3 seconds vs. COTS A: 98.85% in 27 seconds). To the best of our knowledge, the DeepPrint representation is the most compact and discriminative fixed-length fingerprint representation reported in the academic literature.
Fingerprints: Fixed Length Representation via Deep Networks and Domain Knowledge
Apr 01, 2019

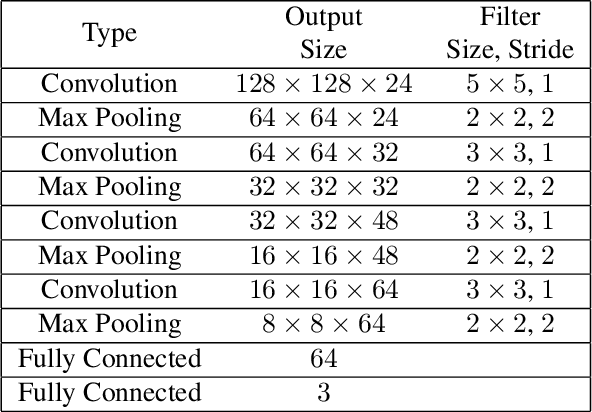
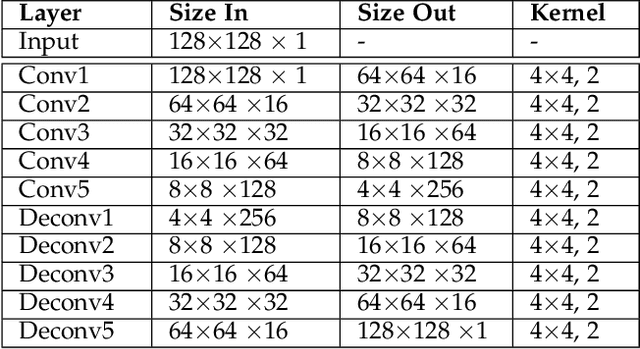
We learn a discriminative fixed length feature representation of fingerprints which stands in contrast to commonly used unordered, variable length sets of minutiae points. To arrive at this fixed length representation, we embed fingerprint domain knowledge into a multitask deep convolutional neural network architecture. Empirical results, on two public-domain fingerprint databases (NIST SD4 and FVC 2004 DB1) show that compared to minutiae representations, extracted by two state-of-the-art commercial matchers (Verifinger v6.3 and Innovatrics v2.0.3), our fixed-length representations provide (i) higher search accuracy: Rank-1 accuracy of 97.9% vs. 97.3% on NIST SD4 against a gallery size of 2000 and (ii) significantly faster, large scale search: 682,594 matches per second vs. 22 matches per second for commercial matchers on an i5 3.3 GHz processor with 8 GB of RAM.
End-to-End Latent Fingerprint Search
Dec 26, 2018
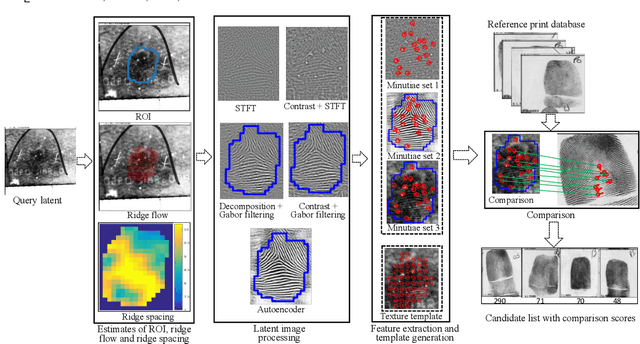
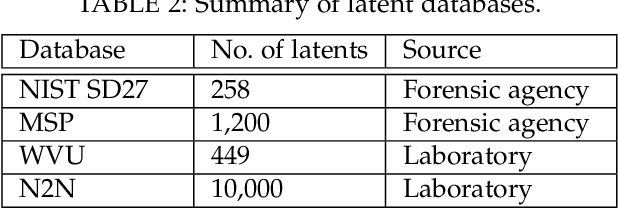
Latent fingerprints are one of the most important and widely used sources of evidence in law enforcement and forensic agencies. Yet the performance of the state-of-the-art latent recognition systems is far from satisfactory, and they often require manual markups to boost the latent search performance. Further, the COTS systems are proprietary and do not output the true comparison scores between a latent and reference prints to conduct quantitative evidential analysis. We present an end-to-end latent fingerprint search system, including automated region of interest (ROI) cropping, latent image preprocessing, feature extraction, feature comparison , and outputs a candidate list. Two separate minutiae extraction models provide complementary minutiae templates. To compensate for the small number of minutiae in small area and poor quality latents, a virtual minutiae set is generated to construct a texture template. A 96-dimensional descriptor is extracted for each minutia from its neighborhood. For computational efficiency, the descriptor length for virtual minutiae is further reduced to 16 using product quantization. Our end-to-end system is evaluated on three latent databases: NIST SD27 (258 latents); MSP (1,200 latents), WVU (449 latents) and N2N (10,000 latents) against a background set of 100K rolled prints, which includes the true rolled mates of the latents with rank-1 retrieval rates of 65.7%, 69.4%, 65.5%, and 7.6% respectively. A multi-core solution implemented on 24 cores obtains 1ms per latent to rolled comparison.