 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT Unified: Joint Fingerprint Recognition and Presentation Attack Detection
May 12, 2023

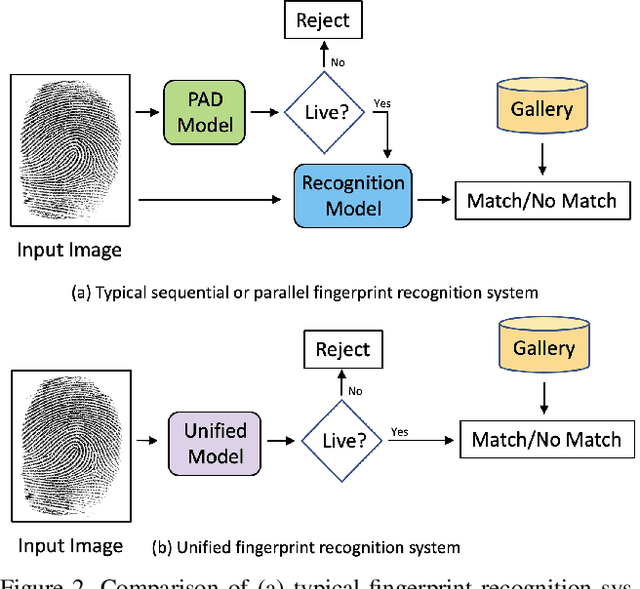

A secure fingerprint recognition system must contain both a presentation attack (i.e., spoof) detection and recognition module in order to protect users against unwanted access by malicious users. Traditionally, these tasks would be carried out by two independent systems; however, recent studies have demonstrated the potential to have one unified system architecture in order to reduce the computational burdens on the system, while maintaining high accuracy. In this work, we leverage a vision transformer architecture for joint spoof detection and matching and report competitive results with state-of-the-art (SOTA) models for both a sequential system (two ViT models operating independently) and a unified architecture (a single ViT model for both tasks). ViT models are particularly well suited for this task as the ViT's global embedding encodes features useful for recognition, whereas the individual, local embeddings are useful for spoof detection. We demonstrate the capability of our unified model to achieve an average integrated matching (IM) accuracy of 98.87% across LivDet 2013 and 2015 CrossMatch sensors. This is comparable to IM accuracy of 98.95% of our sequential dual-ViT system, but with ~50% of the parameters and ~58% of the latency.
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022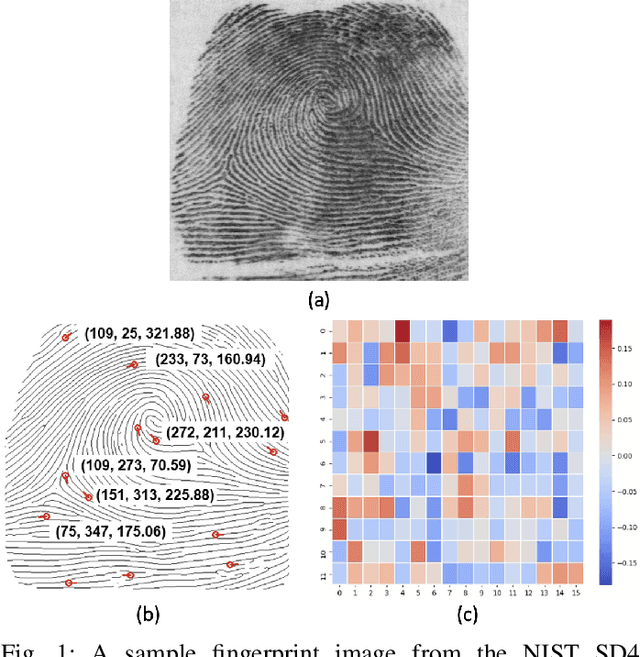

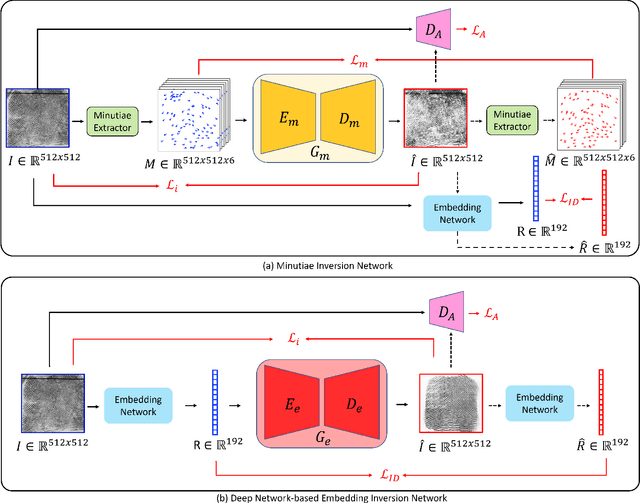

Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.