 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting 2D StyleGAN for 3D-Aware Face Generation
Paper and Code
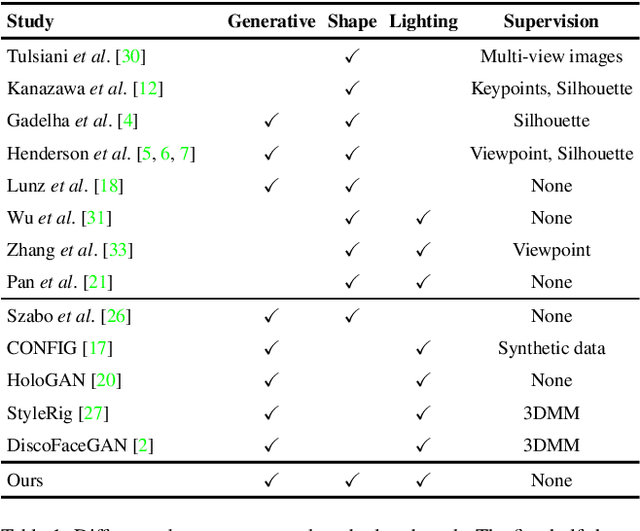
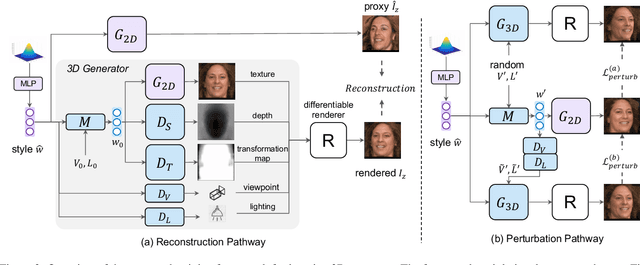
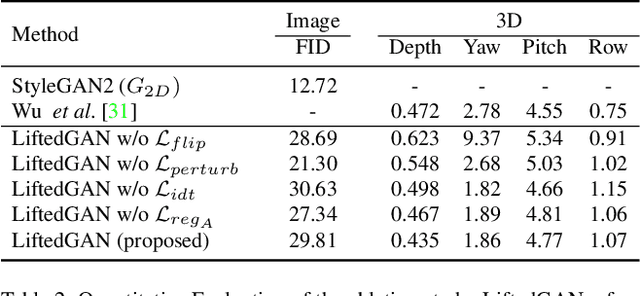

We propose a framework, called LiftedGAN, that disentangles and lifts a pre-trained StyleGAN2 for 3D-aware face generation. Our model is "3D-aware" in the sense that it is able to (1) disentangle the latent space of StyleGAN2 into texture, shape, viewpoint, lighting and (2) generate 3D components for rendering synthetic images. Unlike most previous methods, our method is completely self-supervised, i.e. it neither requires any manual annotation nor 3DMM model for training. Instead, it learns to generate images as well as their 3D components by distilling the prior knowledge in StyleGAN2 with a differentiable renderer. The proposed model is able to output both the 3D shape and texture, allowing explicit pose and lighting control over generated images. Qualitative and quantitative results show the superiority of our approach over existing methods on 3D-controllable GANs in content controllability while generating realistic high quality images.