 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud Detection in Multispectral Satellite Images Using Support Vector Machines With Quantum Kernels
Jul 14, 2023


Support vector machines (SVMs) are a well-established classifier effectively deployed in an array of pattern recognition and classification tasks. In this work, we consider extending classic SVMs with quantum kernels and applying them to satellite data analysis. The design and implementation of SVMs with quantum kernels (hybrid SVMs) is presented. It consists of the Quantum Kernel Estimation (QKE) procedure combined with a classic SVM training routine. The pixel data are mapped to the Hilbert space using ZZ-feature maps acting on the parameterized ansatz state. The parameters are optimized to maximize the kernel target alignment. We approach the problem of cloud detection in satellite image data, which is one of the pivotal steps in both on-the-ground and on-board satellite image analysis processing chains. The experiments performed over the benchmark Landsat-8 multispectral dataset revealed that the simulated hybrid SVM successfully classifies satellite images with accuracy on par with classic SVMs.
Optimizing Kernel-Target Alignment for cloud detection in multispectral satellite images
Jun 26, 2023

The optimization of Kernel-Target Alignment (TA) has been recently proposed as a way to reduce the number of hardware resources in quantum classifiers. It allows to exchange highly expressive and costly circuits to moderate size, task oriented ones. In this work we propose a simple toy model to study the optimization landscape of the Kernel-Target Alignment. We find that for underparameterized circuits the optimization landscape possess either many local extrema or becomes flat with narrow global extremum. We find the dependence of the width of the global extremum peak on the amount of data introduced to the model. The experimental study was performed using multispectral satellite data, and we targeted the cloud detection task, being one of the most fundamental and important image analysis tasks in remote sensing.
Squeezing nnU-Nets with Knowledge Distillation for On-Board Cloud Detection
Jun 16, 2023

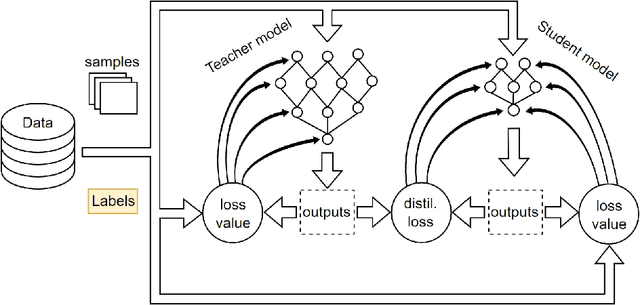

Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling. We approach this task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Unfortunately, such models are commonly memory-inefficient due to their (very) large architectures. To benefit from them in on-board processing, we compress nnU-Nets with knowledge distillation into much smaller and compact U-Nets. Our experiments, performed over Sentinel-2 and Landsat-8 images revealed that nnU-Nets deliver state-of-the-art performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 images (the winners obtained 0.897, the baseline U-Net with the ResNet-34 backbone: 0.817, and the classic Sentinel-2 image thresholding: 0.652). Finally, we showed that knowledge distillation enables to elaborate dramatically smaller (almost 280x) U-Nets when compared to nnU-Nets while still maintaining their segmentation capabilities.
Detecting Clouds in Multispectral Satellite Images Using Quantum-Kernel Support Vector Machines
Feb 16, 2023Support vector machines (SVMs) are a well-established classifier effectively deployed in an array of classification tasks. In this work, we consider extending classical SVMs with quantum kernels and applying them to satellite data analysis. The design and implementation of SVMs with quantum kernels (hybrid SVMs) are presented. Here, the pixels are mapped to the Hilbert space using a family of parameterized quantum feature maps (related to quantum kernels). The parameters are optimized to maximize the kernel target alignment. The quantum kernels have been selected such that they enabled analysis of numerous relevant properties while being able to simulate them with classical computers on a real-life large-scale dataset. Specifically, we approach the problem of cloud detection in the multispectral satellite imagery, which is one of the pivotal steps in both on-the-ground and on-board satellite image analysis processing chains. The experiments performed over the benchmark Landsat-8 multispectral dataset revealed that the simulated hybrid SVM successfully classifies satellite images with accuracy comparable to the classical SVM with the RBF kernel for large datasets. Interestingly, for large datasets, the high accuracy was also observed for the simple quantum kernels, lacking quantum entanglement.
Classification and Self-Supervised Regression of Arrhythmic ECG Signals Using Convolutional Neural Networks
Oct 25, 2022
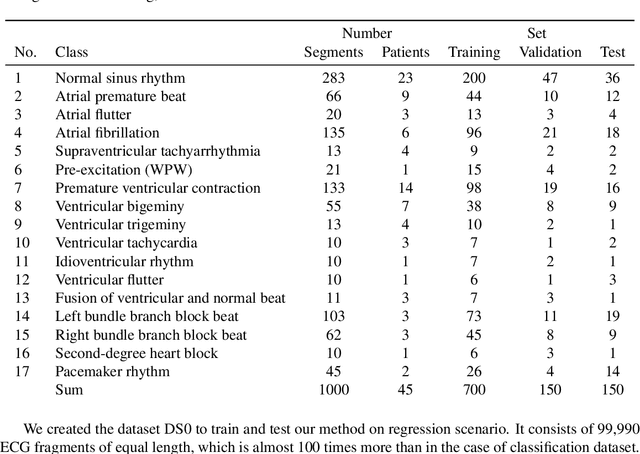
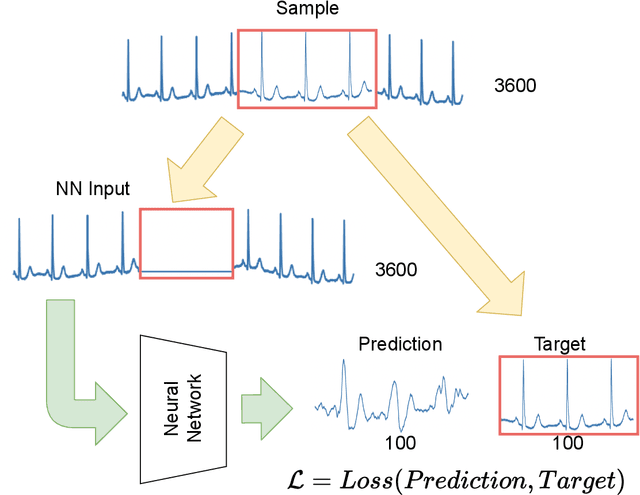

Interpretation of electrocardiography (ECG) signals is required for diagnosing cardiac arrhythmia. Recently, machine learning techniques have been applied for automated computer-aided diagnosis. Machine learning tasks can be divided into regression and classification. Regression can be used for noise and artifacts removal as well as resolve issues of missing data from low sampling frequency. Classification task concerns the prediction of output diagnostic classes according to expert-labeled input classes. In this work, we propose a deep neural network model capable of solving regression and classification tasks. Moreover, we combined the two approaches, using unlabeled and labeled data, to train the model. We tested the model on the MIT-BIH Arrhythmia database. Our method showed high effectiveness in detecting cardiac arrhythmia based on modified Lead II ECG records, as well as achieved high quality of ECG signal approximation. For the former, our method attained overall accuracy of 87:33% and balanced accuracy of 80:54%, on par with reference approaches. For the latter, application of self-supervised learning allowed for training without the need for expert labels. The regression model yielded satisfactory performance with fairly accurate prediction of QRS complexes. Transferring knowledge from regression to the classification task, our method attained higher overall accuracy of 87:78%.
Self-Configuring nnU-Nets Detect Clouds in Satellite Images
Oct 24, 2022



Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can help to reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling of the cloudy areas. We approach this important task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Our experiments, performed over Sentinel-2 and Landsat-8 multispectral images revealed that nnU-Nets deliver state-of-the-art cloud segmentation performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 participating teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 image patches (the winners obtained 0.897, whereas the baseline U-Net with the ResNet-34 backbone used as an encoder: 0.817, and the classic Sentinel-2 image thresholding: 0.652).
Stable training of autoencoders for hyperspectral unmixing
Sep 28, 2021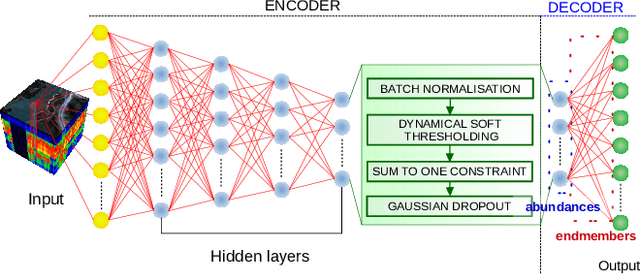
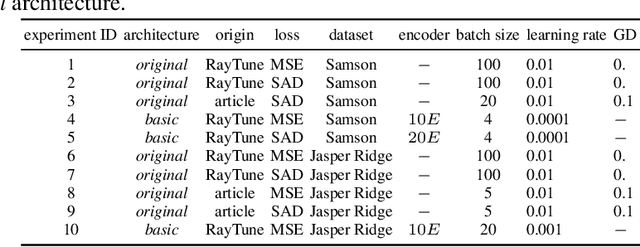
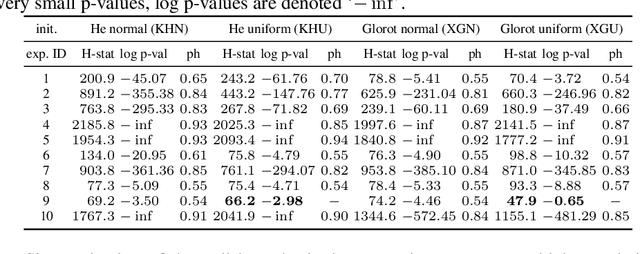

Neural networks, autoencoders in particular, are one of the most promising solutions for unmixing hyperspectral data, i.e. reconstructing the spectra of observed substances (endmembers) and their relative mixing fractions (abundances). Unmixing is needed for effective hyperspectral analysis and classification. However, as we show in this paper, the training of autoencoders for unmixing is highly dependent on weights initialisation. Some sets of weights lead to degenerate or low performance solutions, introducing negative bias in expected performance. In this work we present the results of experiments investigating autoencoders' stability, verifying the dependence of reconstruction error on initial weights and exploring conditions needed for successful optimisation of autoencoder parameters.
Effective transfer learning for hyperspectral image classification with deep convolutional neural networks
Sep 12, 2019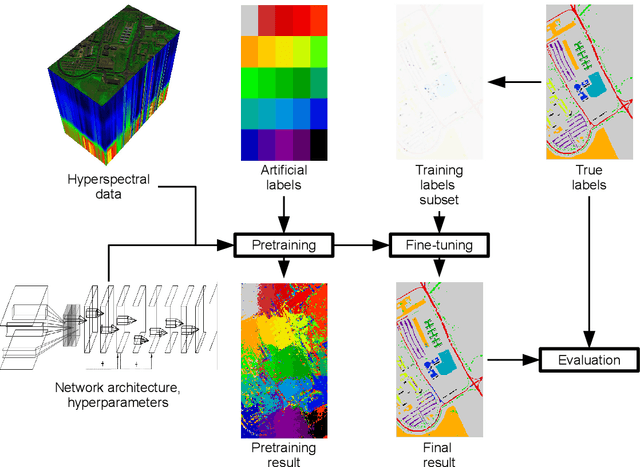
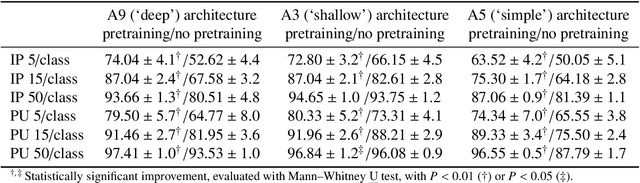
Hyperspectral imaging is a rich source of data, allowing for multitude of effective applications. On the other hand such imaging remains challenging because of large data dimension and, typically, small pool of available training examples. While deep learning approaches have been shown to be successful in providing effective classification solutions, especially for high dimensional problems, unfortunately they work best with a lot of labelled examples available. To alleviate the second requirement for a particular dataset the transfer learning approach can be used: first the network is pre-trained on some dataset with large amount of training labels available, then the actual dataset is used to fine-tune the network. This strategy is not straightforward to apply with hyperspectral images, as it is often the case that only one particular image of some type or characteristic is available. In this paper, we propose and investigate a simple and effective strategy of transfer learning that uses unsupervised pre-training step without label information. This approach can be applied to many of the hyperspectral classification problems. Performed experiments show that it is very effective in improving the classification accuracy without being restricted to a particular image type or neural network architecture. An additional advantage of the proposed approach is the unsupervised nature of the pre-training step, which can be done immediately after image acquisition, without the need of the potentially costly expert's time.