 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning with experience replay and adaptation of action dispersion
Paper and Code
Jul 30, 2022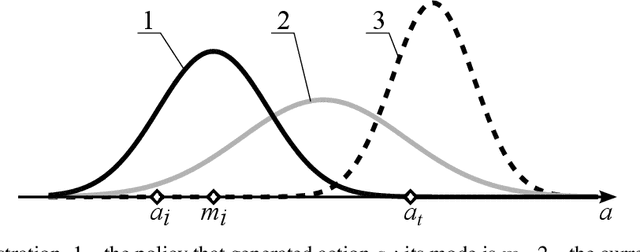


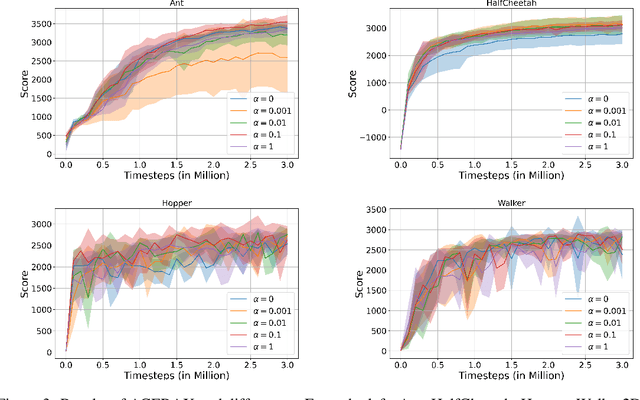
Effective reinforcement learning requires a proper balance of exploration and exploitation defined by the dispersion of action distribution. However, this balance depends on the task, the current stage of the learning process, and the current environment state. Existing methods that designate the action distribution dispersion require problem-dependent hyperparameters. In this paper, we propose to automatically designate the action distribution dispersion using the following principle: This distribution should have sufficient dispersion to enable the evaluation of future policies. To that end, the dispersion should be tuned to assure a sufficiently high probability (densities) of the actions in the replay buffer and the modes of the distributions that generated them, yet this dispersion should not be higher. This way, a policy can be effectively evaluated based on the actions in the buffer, but exploratory randomness in actions decreases when this policy converges. The above principle is verified here on challenging benchmarks Ant, HalfCheetah, Hopper, and Walker2D, with good results. Our method makes the action standard deviations converge to values similar to those resulting from trial-and-error optimization.