 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn training deep networks for satellite image super-resolution
Paper and Code
Jun 16, 2019


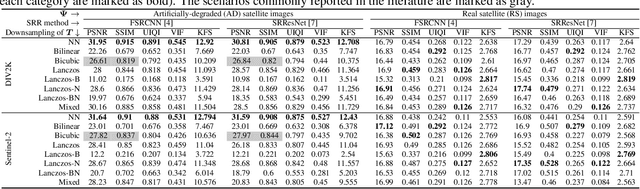
The capabilities of super-resolution reconstruction (SRR)---techniques for enhancing image spatial resolution---have been recently improved significantly by the use of deep convolutional neural networks. Commonly, such networks are learned using huge training sets composed of original images alongside their low-resolution counterparts, obtained with bicubic downsampling. In this paper, we investigate how the SRR performance is influenced by the way such low-resolution training data are obtained, which has not been explored up to date. Our extensive experimental study indicates that the training data characteristics have a large impact on the reconstruction accuracy, and the widely-adopted approach is not the most effective for dealing with satellite images. Overall, we argue that developing better training data preparation routines may be pivotal in making SRR suitable for real-world applications.