 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Maltese NLP using Transliterated and Machine Translated Arabic Data
Sep 16, 2025Maltese is a unique Semitic language that has evolved under extensive influence from Romance and Germanic languages, particularly Italian and English. Despite its Semitic roots, its orthography is based on the Latin script, creating a gap between it and its closest linguistic relatives in Arabic. In this paper, we explore whether Arabic-language resources can support Maltese natural language processing (NLP) through cross-lingual augmentation techniques. We investigate multiple strategies for aligning Arabic textual data with Maltese, including various transliteration schemes and machine translation (MT) approaches. As part of this, we also introduce novel transliteration systems that better represent Maltese orthography. We evaluate the impact of these augmentations on monolingual and mutlilingual models and demonstrate that Arabic-based augmentation can significantly benefit Maltese NLP tasks.
MELABenchv1: Benchmarking Large Language Models against Smaller Fine-Tuned Models for Low-Resource Maltese NLP
Jun 04, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various Natural Language Processing (NLP) tasks, largely due to their generalisability and ability to perform tasks without additional training. However, their effectiveness for low-resource languages remains limited. In this study, we evaluate the performance of 55 publicly available LLMs on Maltese, a low-resource language, using a newly introduced benchmark covering 11 discriminative and generative tasks. Our experiments highlight that many models perform poorly, particularly on generative tasks, and that smaller fine-tuned models often perform better across all tasks. From our multidimensional analysis, we investigate various factors impacting performance. We conclude that prior exposure to Maltese during pre-training and instruction-tuning emerges as the most important factor. We also examine the trade-offs between fine-tuning and prompting, highlighting that while fine-tuning requires a higher initial cost, it yields better performance and lower inference costs. Through this work, we aim to highlight the need for more inclusive language technologies and recommend that researchers working with low-resource languages consider more "traditional" language modelling approaches.
Cross-Lingual Transfer from Related Languages: Treating Low-Resource Maltese as Multilingual Code-Switching
Feb 03, 2024Although multilingual language models exhibit impressive cross-lingual transfer capabilities on unseen languages, the performance on downstream tasks is impacted when there is a script disparity with the languages used in the multilingual model's pre-training data. Using transliteration offers a straightforward yet effective means to align the script of a resource-rich language with a target language, thereby enhancing cross-lingual transfer capabilities. However, for mixed languages, this approach is suboptimal, since only a subset of the language benefits from the cross-lingual transfer while the remainder is impeded. In this work, we focus on Maltese, a Semitic language, with substantial influences from Arabic, Italian, and English, and notably written in Latin script. We present a novel dataset annotated with word-level etymology. We use this dataset to train a classifier that enables us to make informed decisions regarding the appropriate processing of each token in the Maltese language. We contrast indiscriminate transliteration or translation to mixing processing pipelines that only transliterate words of Arabic origin, thereby resulting in text with a mixture of scripts. We fine-tune the processed data on four downstream tasks and show that conditional transliteration based on word etymology yields the best results, surpassing fine-tuning with raw Maltese or Maltese processed with non-selective pipelines.
Pre-training Data Quality and Quantity for a Low-Resource Language: New Corpus and BERT Models for Maltese
May 26, 2022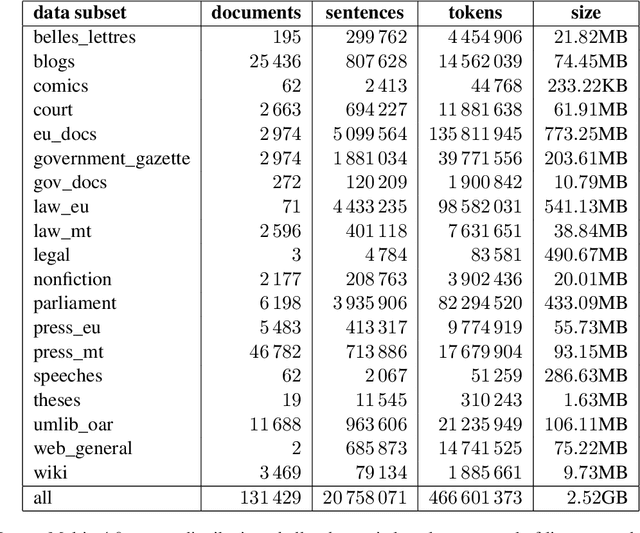
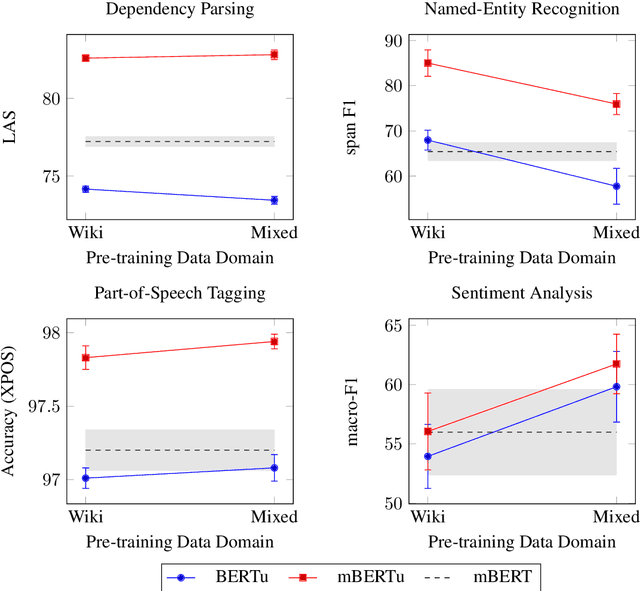
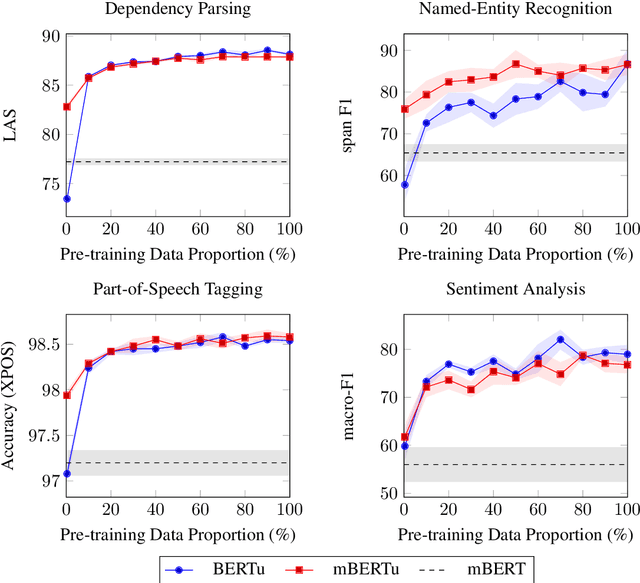
Multilingual language models such as mBERT have seen impressive cross-lingual transfer to a variety of languages, but many languages remain excluded from these models. In this paper, we analyse the effect of pre-training with monolingual data for a low-resource language that is not included in mBERT -- Maltese -- with a range of pre-training set ups. We conduct evaluations with the newly pre-trained models on three morphosyntactic tasks -- dependency parsing, part-of-speech tagging, and named-entity recognition -- and one semantic classification task -- sentiment analysis. We also present a newly created corpus for Maltese, and determine the effect that the pre-training data size and domain have on the downstream performance. Our results show that using a mixture of pre-training domains is often superior to using Wikipedia text only. We also find that a fraction of this corpus is enough to make significant leaps in performance over Wikipedia-trained models. We pre-train and compare two models on the new corpus: a monolingual BERT model trained from scratch (BERTu), and a further pre-trained multilingual BERT (mBERTu). The models achieve state-of-the-art performance on these tasks, despite the new corpus being considerably smaller than typically used corpora for high-resourced languages. On average, BERTu outperforms or performs competitively with mBERTu, and the largest gains are observed for higher-level tasks.