 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArPoMeme: An Annotated Arabic Multimodal Dataset for Political Ideology and Polarization
May 20, 2026Memes have become a prominent medium of political communication in the Arab world, reflecting how humor, imagery, and text interact to express ideological and cultural positions. Despite the centrality of memes to online political discourse, there is a lack of systematically curated resources for analyzing their multimodal and ideological dimensions in Arabic. This paper presents ArPoMeme, a large-scale dataset of approximately 7,300 Arabic political memes categorized by ideological orientation, including Leftist, Islamist, Pan-Arabist, and Satirical perspectives. The dataset captures the diversity of Arabic meme ecosystems by grounding classification in the self-identification of public Facebook pages and groups that produce and disseminate these memes. To ensure both scale and accuracy, we designed a semi-automated data collection pipeline combining Playwright-based Facebook scraping with Google Drive synchronization, followed by text extraction using the Qwen2.5-VL-7B vision language model. The extracted text was manually verified and annotated for three polarization dimensions: Us vs. Them framing, Hostility toward out-groups, and Calls to action. Annotation was conducted through a custom Streamlit-based interface supporting distributed labeling, real-time tracking, and version control. The resulting dataset links visual content, textual messages, and ideological orientation, enabling fine-grained analysis of political antagonism, mobilization, and humor. Quantitative analysis of the annotated corpus reveals strong asymmetries in antagonistic framing across ideological groups, with Islamist and satirical memes exhibiting the highest levels of hostility and mobilization cues. The dataset and the annotation tool offers a reproducible and publicly available resource for studying Arabic political discourse, multimodal ideology detection, and polarization dynamics.
Exploiting Dialect Identification in Automatic Dialectal Text Normalization
Jul 03, 2024



Dialectal Arabic is the primary spoken language used by native Arabic speakers in daily communication. The rise of social media platforms has notably expanded its use as a written language. However, Arabic dialects do not have standard orthographies. This, combined with the inherent noise in user-generated content on social media, presents a major challenge to NLP applications dealing with Dialectal Arabic. In this paper, we explore and report on the task of CODAfication, which aims to normalize Dialectal Arabic into the Conventional Orthography for Dialectal Arabic (CODA). We work with a unique parallel corpus of multiple Arabic dialects focusing on five major city dialects. We benchmark newly developed pretrained sequence-to-sequence models on the task of CODAfication. We further show that using dialect identification information improves the performance across all dialects. We make our code, data, and pretrained models publicly available.
ZAEBUC-Spoken: A Multilingual Multidialectal Arabic-English Speech Corpus
Mar 27, 2024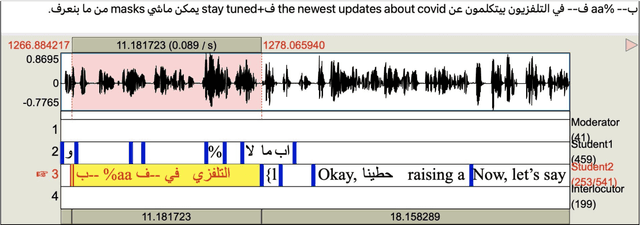
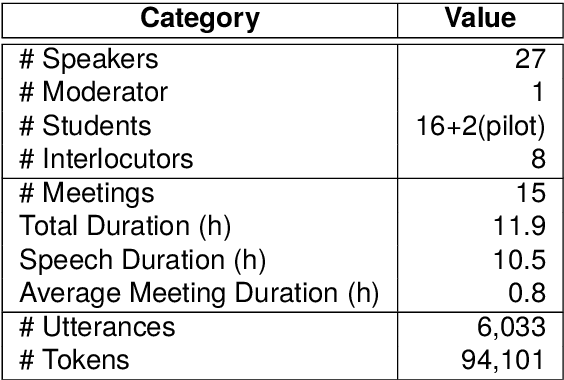
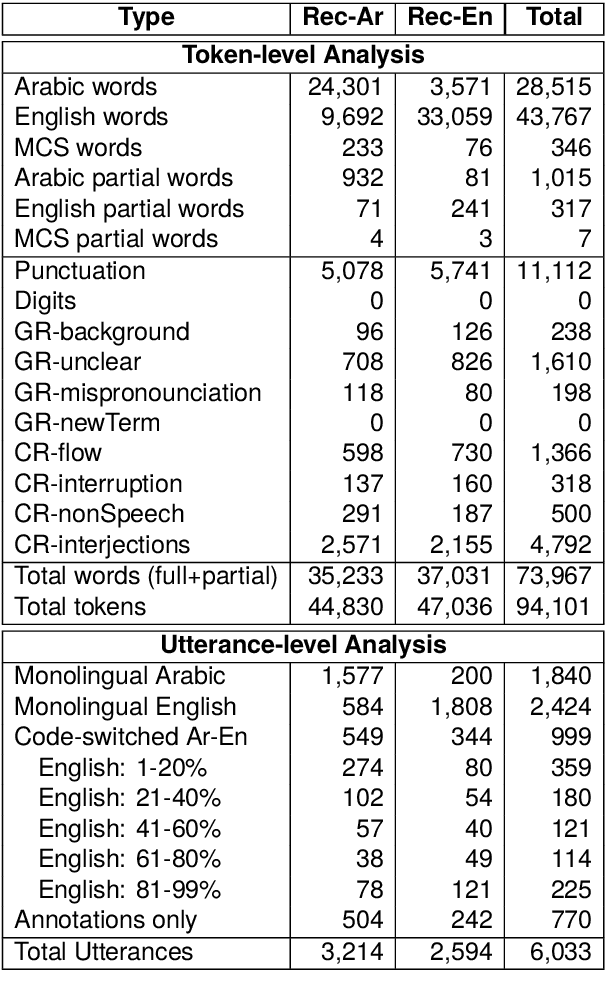
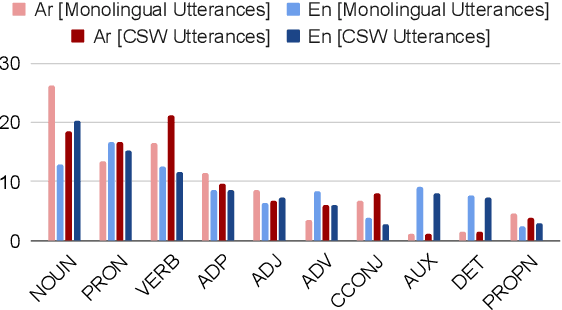
We present ZAEBUC-Spoken, a multilingual multidialectal Arabic-English speech corpus. The corpus comprises twelve hours of Zoom meetings involving multiple speakers role-playing a work situation where Students brainstorm ideas for a certain topic and then discuss it with an Interlocutor. The meetings cover different topics and are divided into phases with different language setups. The corpus presents a challenging set for automatic speech recognition (ASR), including two languages (Arabic and English) with Arabic spoken in multiple variants (Modern Standard Arabic, Gulf Arabic, and Egyptian Arabic) and English used with various accents. Adding to the complexity of the corpus, there is also code-switching between these languages and dialects. As part of our work, we take inspiration from established sets of transcription guidelines to present a set of guidelines handling issues of conversational speech, code-switching and orthography of both languages. We further enrich the corpus with two layers of annotations; (1) dialectness level annotation for the portion of the corpus where mixing occurs between different variants of Arabic, and (2) automatic morphological annotations, including tokenization, lemmatization, and part-of-speech tagging.
Cross-Lingual Transfer from Related Languages: Treating Low-Resource Maltese as Multilingual Code-Switching
Feb 03, 2024Although multilingual language models exhibit impressive cross-lingual transfer capabilities on unseen languages, the performance on downstream tasks is impacted when there is a script disparity with the languages used in the multilingual model's pre-training data. Using transliteration offers a straightforward yet effective means to align the script of a resource-rich language with a target language, thereby enhancing cross-lingual transfer capabilities. However, for mixed languages, this approach is suboptimal, since only a subset of the language benefits from the cross-lingual transfer while the remainder is impeded. In this work, we focus on Maltese, a Semitic language, with substantial influences from Arabic, Italian, and English, and notably written in Latin script. We present a novel dataset annotated with word-level etymology. We use this dataset to train a classifier that enables us to make informed decisions regarding the appropriate processing of each token in the Maltese language. We contrast indiscriminate transliteration or translation to mixing processing pipelines that only transliterate words of Arabic origin, thereby resulting in text with a mixture of scripts. We fine-tune the processed data on four downstream tasks and show that conditional transliteration based on word etymology yields the best results, surpassing fine-tuning with raw Maltese or Maltese processed with non-selective pipelines.