 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Speech Recognition in Maltese: A Low-Resource Perspective
Nov 15, 2021


Developing speech technologies is a challenge for low-resource languages for which both annotated and raw speech data is sparse. Maltese is one such language. Recent years have seen an increased interest in the computational processing of Maltese, including speech technologies, but resources for the latter remain sparse. In this paper, we consider data augmentation techniques for improving speech recognition for such languages, focusing on Maltese as a test case. We consider three different types of data augmentation: unsupervised training, multilingual training and the use of synthesized speech as training data. The goal is to determine which of these techniques, or combination of them, is the most effective to improve speech recognition for languages where the starting point is a small corpus of approximately 7 hours of transcribed speech. Our results show that combining the three data augmentation techniques studied here lead us to an absolute WER improvement of 15% without the use of a language model.
Triplet loss based embeddings for forensic speaker identification in Spanish
Feb 24, 2021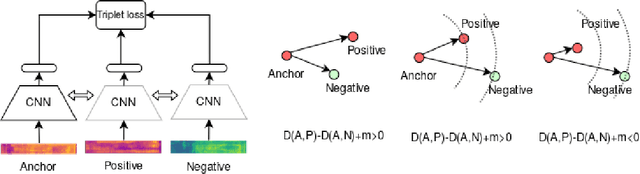

With the advent of digital technology, it is more common that committed crimes or legal disputes involve some form of speech recording where the identity of a speaker is questioned [1]. In face of this situation, the field of forensic speaker identification has been looking to shed light on the problem by quantifying how much a speech recording belongs to a particular person in relation to a population. In this work, we explore the use of speech embeddings obtained by training a CNN using the triplet loss. In particular, we focus on the Spanish language which has not been extensively studies. We propose extracting the embeddings from speech spectrograms samples, then explore several configurations of such spectrograms, and finally, quantify the embeddings quality. We also show some limitations of our data setting which is predominantly composed by male speakers. At the end, we propose two approaches to calculate the Likelihood Radio given out speech embeddings and we show that triplet loss is a good alternative to create speech embeddings for forensic speaker identification.
MASRI-HEADSET: A Maltese Corpus for Speech Recognition
Aug 13, 2020
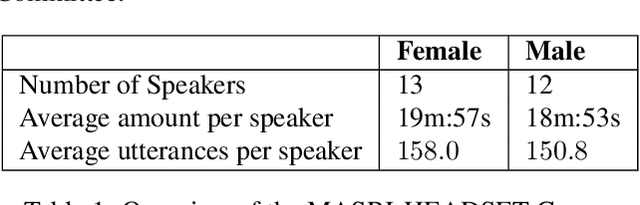
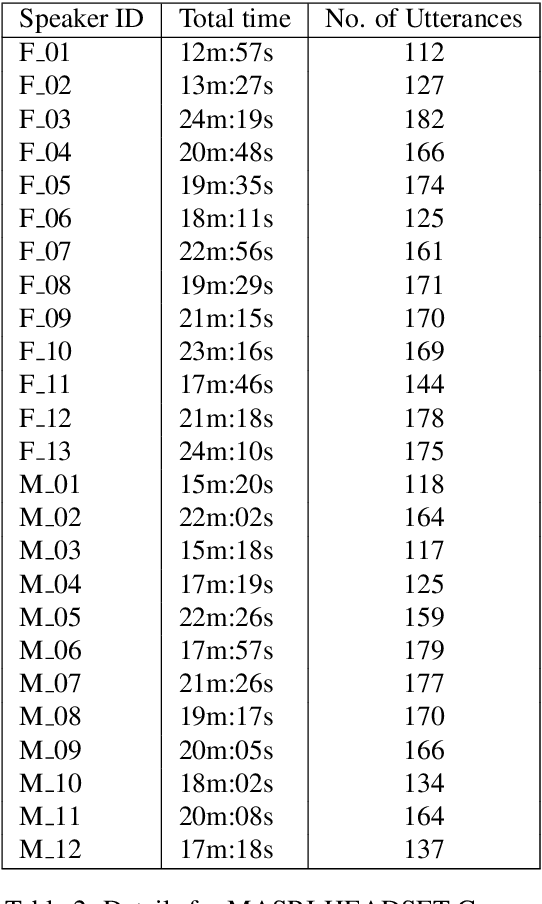
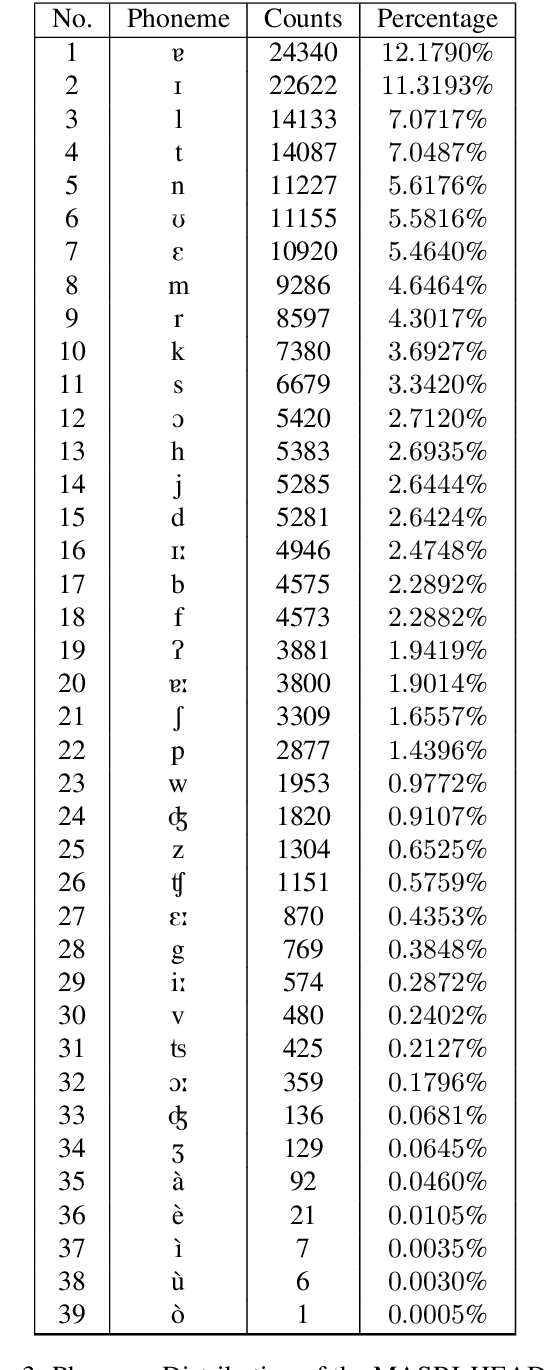
Maltese, the national language of Malta, is spoken by approximately 500,000 people. Speech processing for Maltese is still in its early stages of development. In this paper, we present the first spoken Maltese corpus designed purposely for Automatic Speech Recognition (ASR). The MASRI-HEADSET corpus was developed by the MASRI project at the University of Malta. It consists of 8 hours of speech paired with text, recorded by using short text snippets in a laboratory environment. The speakers were recruited from different geographical locations all over the Maltese islands, and were roughly evenly distributed by gender. This paper also presents some initial results achieved in baseline experiments for Maltese ASR using Sphinx and Kaldi. The MASRI-HEADSET Corpus is publicly available for research/academic purposes.