 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sequence Training of Attention Models using Approximative Recombination
Oct 18, 2021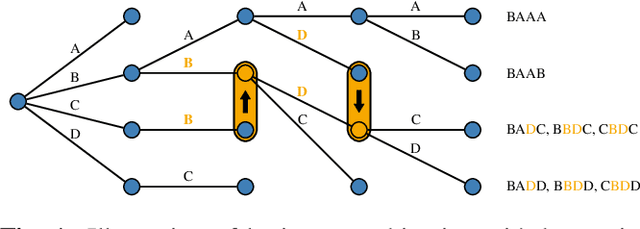
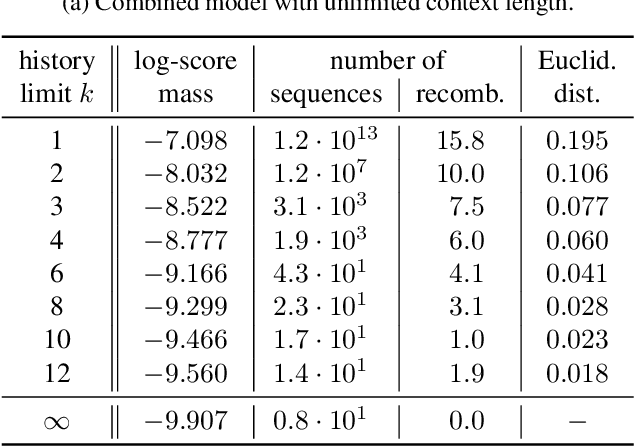
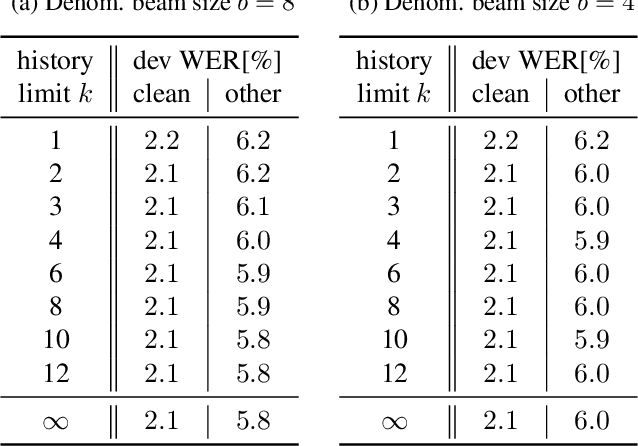

Sequence discriminative training is a great tool to improve the performance of an automatic speech recognition system. It does, however, necessitate a sum over all possible word sequences, which is intractable to compute in practice. Current state-of-the-art systems with unlimited label context circumvent this problem by limiting the summation to an n-best list of relevant competing hypotheses obtained from beam search. This work proposes to perform (approximative) recombinations of hypotheses during beam search, if they share a common local history. The error that is incurred by the approximation is analyzed and it is shown that using this technique the effective beam size can be increased by several orders of magnitude without significantly increasing the computational requirements. Lastly, it is shown that this technique can be used to effectively perform sequence discriminative training for attention-based encoder-decoder acoustic models on the LibriSpeech task.
Towards Reinforcement Learning for Pivot-based Neural Machine Translation with Non-autoregressive Transformer
Sep 27, 2021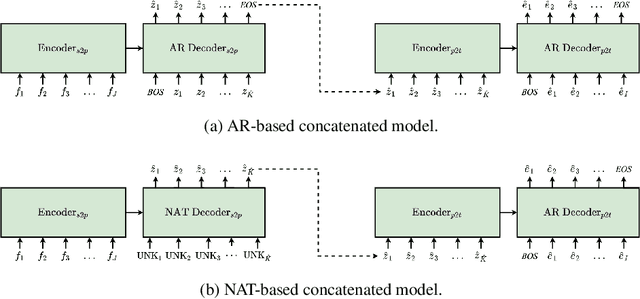
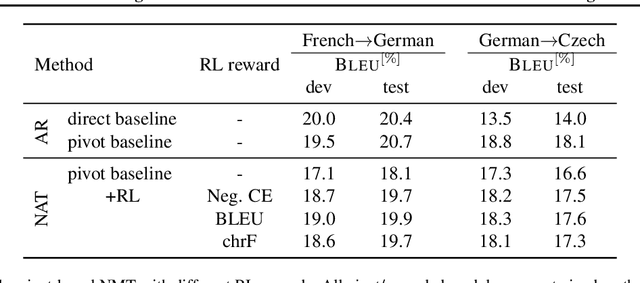
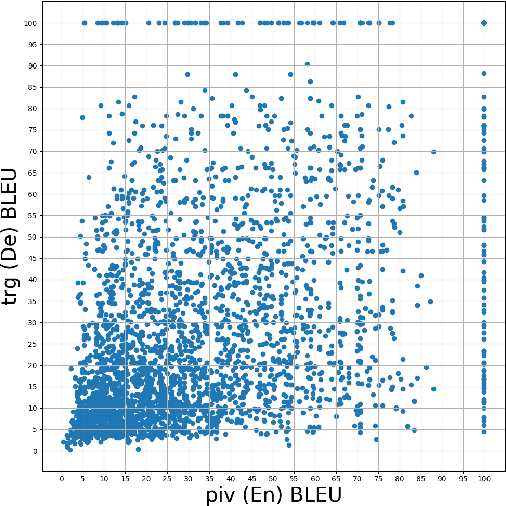
Pivot-based neural machine translation (NMT) is commonly used in low-resource setups, especially for translation between non-English language pairs. It benefits from using high resource source-pivot and pivot-target language pairs and an individual system is trained for both sub-tasks. However, these models have no connection during training, and the source-pivot model is not optimized to produce the best translation for the source-target task. In this work, we propose to train a pivot-based NMT system with the reinforcement learning (RL) approach, which has been investigated for various text generation tasks, including machine translation (MT). We utilize a non-autoregressive transformer and present an end-to-end pivot-based integrated model, enabling training on source-target data.
Integrated Training for Sequence-to-Sequence Models Using Non-Autoregressive Transformer
Sep 27, 2021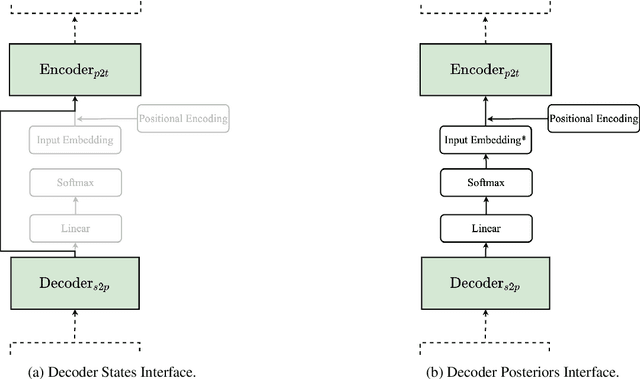
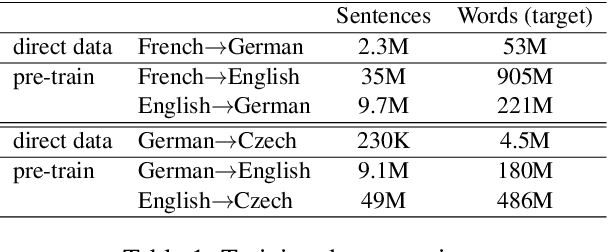
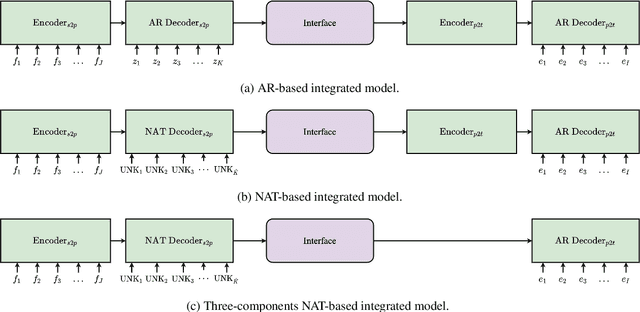
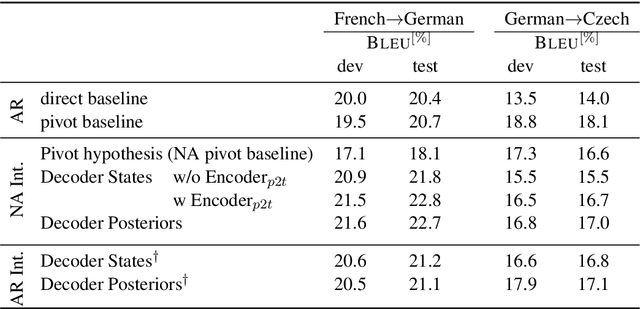
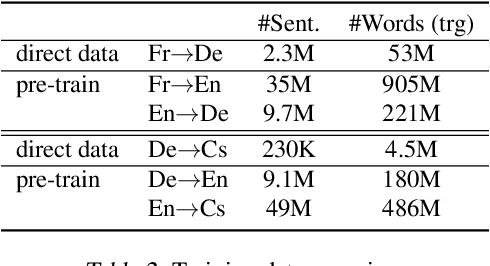
Complex natural language applications such as speech translation or pivot translation traditionally rely on cascaded models. However, cascaded models are known to be prone to error propagation and model discrepancy problems. Furthermore, there is no possibility of using end-to-end training data in conventional cascaded systems, meaning that the training data most suited for the task cannot be used. Previous studies suggested several approaches for integrated end-to-end training to overcome those problems, however they mostly rely on (synthetic or natural) three-way data. We propose a cascaded model based on the non-autoregressive Transformer that enables end-to-end training without the need for an explicit intermediate representation. This new architecture (i) avoids unnecessary early decisions that can cause errors which are then propagated throughout the cascaded models and (ii) utilizes the end-to-end training data directly. We conduct an evaluation on two pivot-based machine translation tasks, namely French-German and German-Czech. Our experimental results show that the proposed architecture yields an improvement of more than 2 BLEU for French-German over the cascaded baseline.
Learning Bilingual Sentence Embeddings via Autoencoding and Computing Similarities with a Multilayer Perceptron
Jun 05, 2019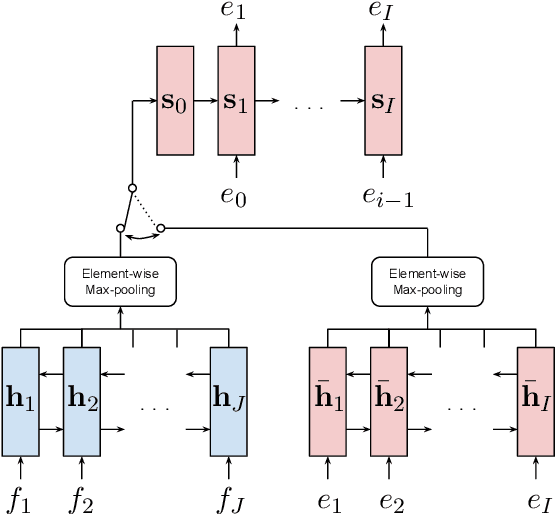
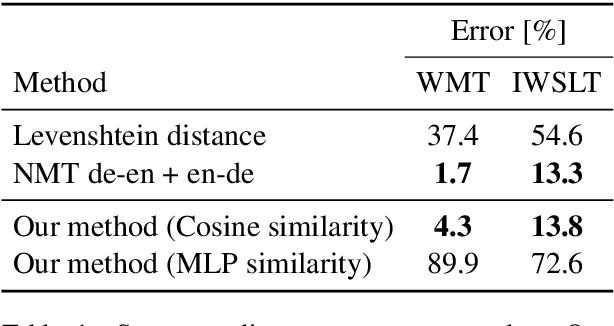
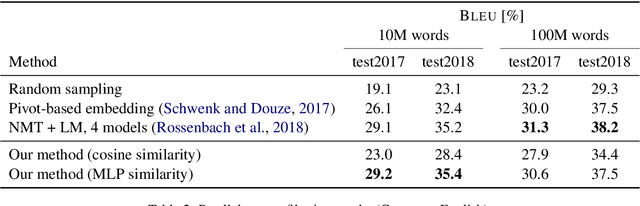
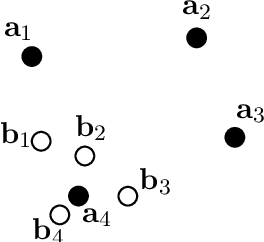
We propose a novel model architecture and training algorithm to learn bilingual sentence embeddings from a combination of parallel and monolingual data. Our method connects autoencoding and neural machine translation to force the source and target sentence embeddings to share the same space without the help of a pivot language or an additional transformation. We train a multilayer perceptron on top of the sentence embeddings to extract good bilingual sentence pairs from nonparallel or noisy parallel data. Our approach shows promising performance on sentence alignment recovery and the WMT 2018 parallel corpus filtering tasks with only a single model.