 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training of a Neural HMM with Label and Transition Probabilities
Oct 09, 2023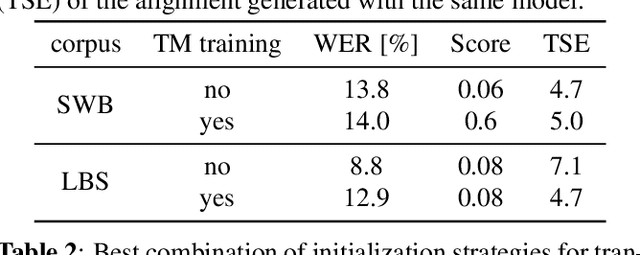
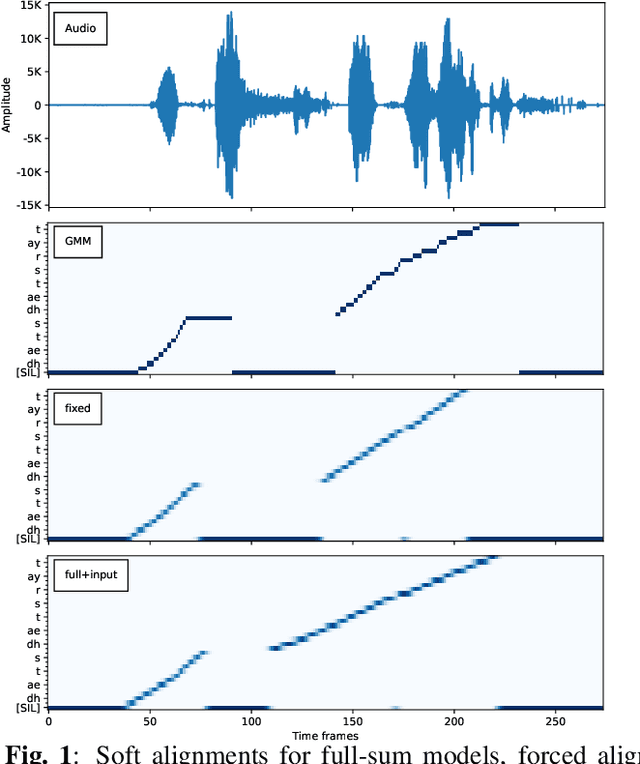

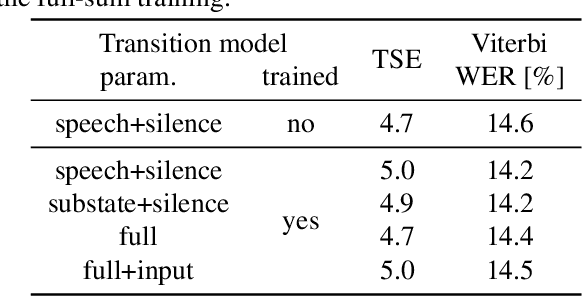
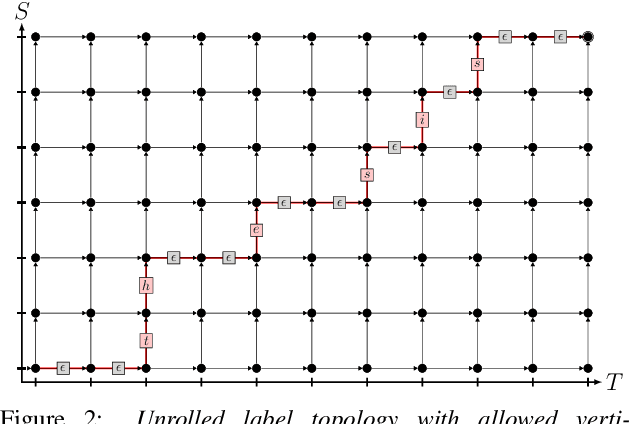
We investigate a novel modeling approach for end-to-end neural network training using hidden Markov models (HMM) where the transition probabilities between hidden states are modeled and learned explicitly. Most contemporary sequence-to-sequence models allow for from-scratch training by summing over all possible label segmentations in a given topology. In our approach there are explicit, learnable probabilities for transitions between segments as opposed to a blank label that implicitly encodes duration statistics. We implement a GPU-based forward-backward algorithm that enables the simultaneous training of label and transition probabilities. We investigate recognition results and additionally Viterbi alignments of our models. We find that while the transition model training does not improve recognition performance, it has a positive impact on the alignment quality. The generated alignments are shown to be viable targets in state-of-the-art Viterbi trainings.
Efficient Training of Neural Transducer for Speech Recognition
Apr 22, 2022


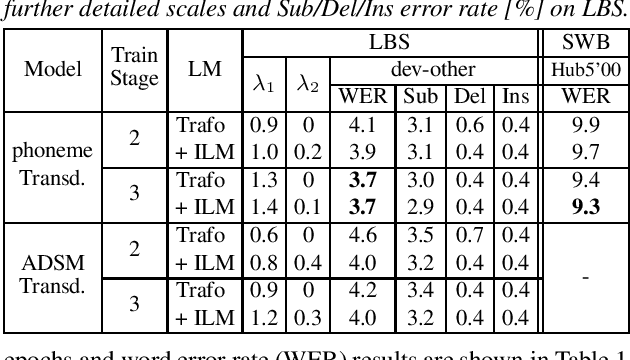
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.
Conformer-based Hybrid ASR System for Switchboard Dataset
Nov 05, 2021



The recently proposed conformer architecture has been successfully used for end-to-end automatic speech recognition (ASR) architectures achieving state-of-the-art performance on different datasets. To our best knowledge, the impact of using conformer acoustic model for hybrid ASR is not investigated. In this paper, we present and evaluate a competitive conformer-based hybrid model training recipe. We study different training aspects and methods to improve word-error-rate as well as to increase training speed. We apply time downsampling methods for efficient training and use transposed convolutions to upsample the output sequence again. We conduct experiments on Switchboard 300h dataset and our conformer-based hybrid model achieves competitive results compared to other architectures. It generalizes very well on Hub5'01 test set and outperforms the BLSTM-based hybrid model significantly.
Automatic Learning of Subword Dependent Model Scales
Oct 18, 2021
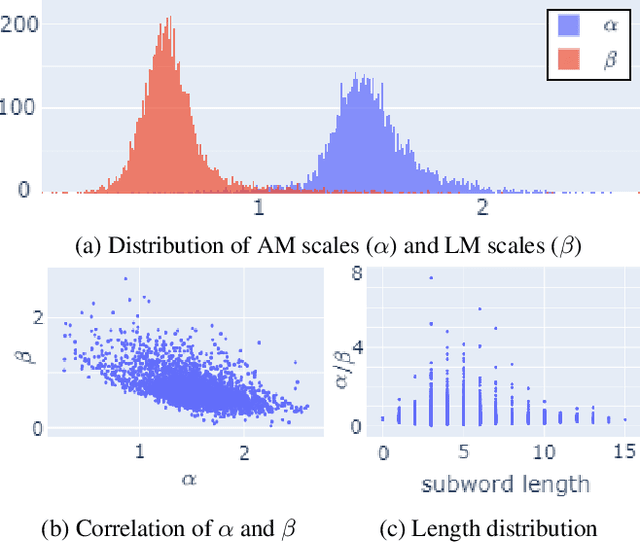

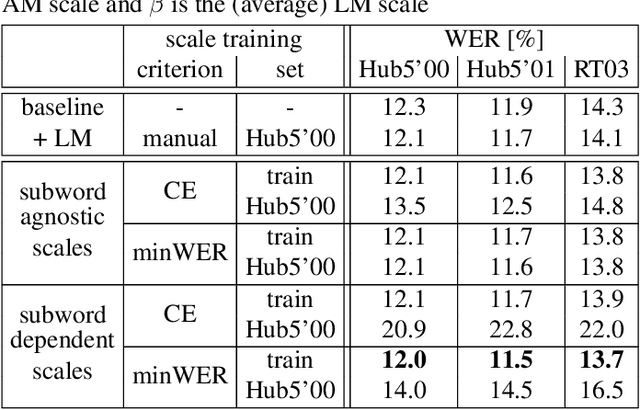
To improve the performance of state-of-the-art automatic speech recognition systems it is common practice to include external knowledge sources such as language models or prior corrections. This is usually done via log-linear model combination using separate scaling parameters for each model. Typically these parameters are manually optimized on some held-out data. In this work we propose to optimize these scaling parameters via automatic differentiation and stochastic gradient decent similar to the neural network model parameters. We show on the LibriSpeech (LBS) and Switchboard (SWB) corpora that the model scales for a combination of attentionbased encoder-decoder acoustic model and language model can be learned as effectively as with manual tuning. We further extend this approach to subword dependent model scales which could not be tuned manually which leads to 7% improvement on LBS and 3% on SWB. We also show that joint training of scales and model parameters is possible and gives additional 6% improvement on LBS.
Efficient Sequence Training of Attention Models using Approximative Recombination
Oct 18, 2021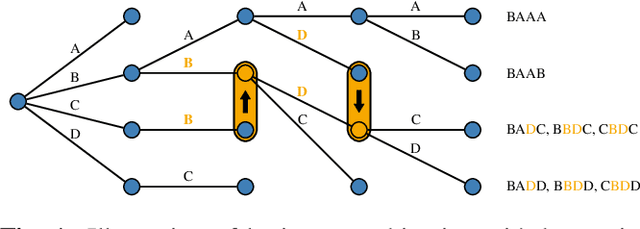
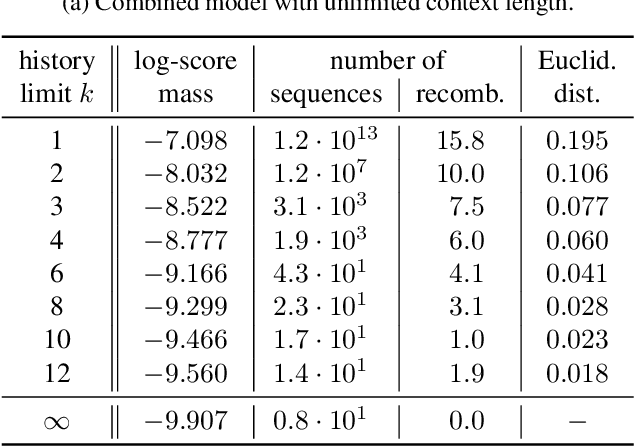
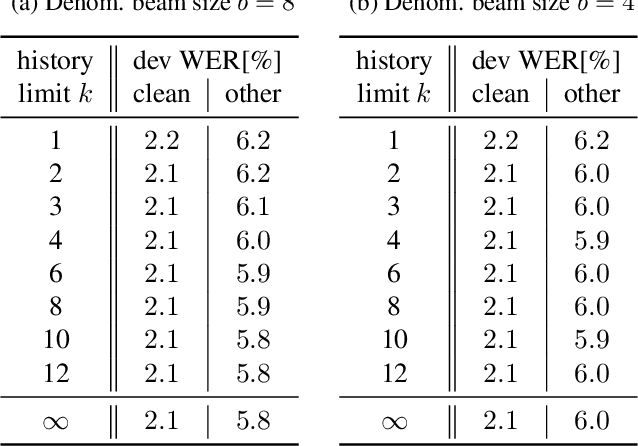

Sequence discriminative training is a great tool to improve the performance of an automatic speech recognition system. It does, however, necessitate a sum over all possible word sequences, which is intractable to compute in practice. Current state-of-the-art systems with unlimited label context circumvent this problem by limiting the summation to an n-best list of relevant competing hypotheses obtained from beam search. This work proposes to perform (approximative) recombinations of hypotheses during beam search, if they share a common local history. The error that is incurred by the approximation is analyzed and it is shown that using this technique the effective beam size can be increased by several orders of magnitude without significantly increasing the computational requirements. Lastly, it is shown that this technique can be used to effectively perform sequence discriminative training for attention-based encoder-decoder acoustic models on the LibriSpeech task.
Investigating Methods to Improve Language Model Integration for Attention-based Encoder-Decoder ASR Models
Apr 12, 2021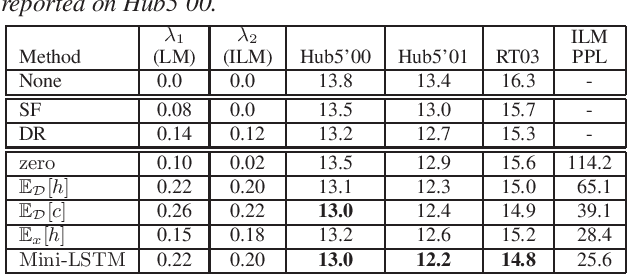


Attention-based encoder-decoder (AED) models learn an implicit internal language model (ILM) from the training transcriptions. The integration with an external LM trained on much more unpaired text usually leads to better performance. A Bayesian interpretation as in the hybrid autoregressive transducer (HAT) suggests dividing by the prior of the discriminative acoustic model, which corresponds to this implicit LM, similarly as in the hybrid hidden Markov model approach. The implicit LM cannot be calculated efficiently in general and it is yet unclear what are the best methods to estimate it. In this work, we compare different approaches from the literature and propose several novel methods to estimate the ILM directly from the AED model. Our proposed methods outperform all previous approaches. We also investigate other methods to suppress the ILM mainly by decreasing the capacity of the AED model, limiting the label context, and also by training the AED model together with a pre-existing LM.
Feature Replacement and Combination for Hybrid ASR Systems
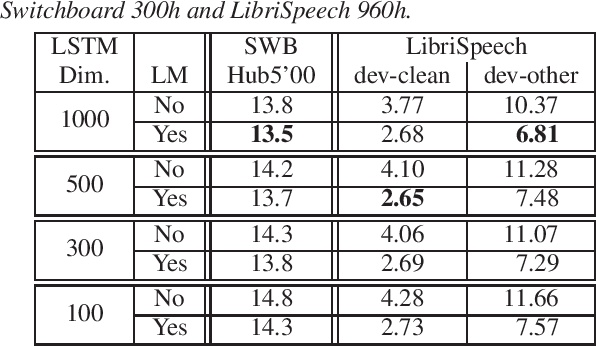
Apr 09, 2021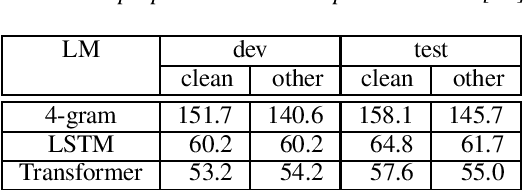


Acoustic modeling of raw waveform and learning feature extractors as part of the neural network classifier has been the goal of many studies in the area of automatic speech recognition (ASR). Recently, one line of research has focused on frameworks that can be pre-trained on audio-only data in an unsupervised fashion and aim at improving downstream ASR tasks. In this work, we investigate the usefulness of one of these front-end frameworks, namely wav2vec, for hybrid ASR systems. In addition to deploying a pre-trained feature extractor, we explore how to make use of an existing acoustic model (AM) trained on the same task with different features as well. Another neural front-end which is only trained together with the supervised ASR loss as well as traditional Gammatone features are applied for comparison. Moreover, it is shown that the AM can be retrofitted with i-vectors for speaker adaptation. Finally, the described features are combined in order to further advance the performance. With the final best system, we obtain a relative improvement of 4% and 6% over our previous best model on the LibriSpeech test-clean and test-other sets.
Librispeech Transducer Model with Internal Language Model Prior Correction
Apr 07, 2021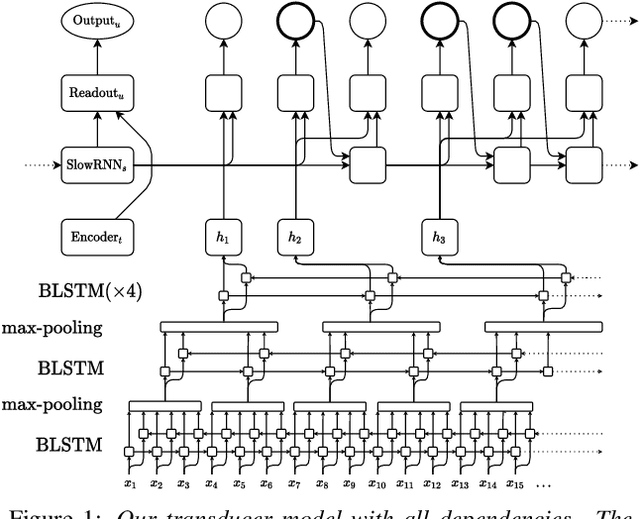

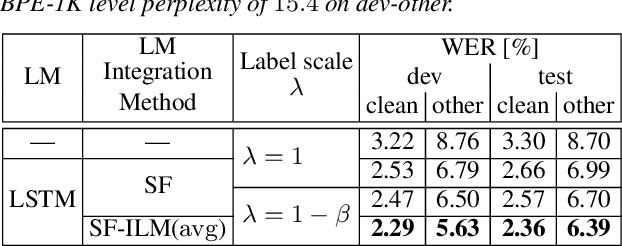
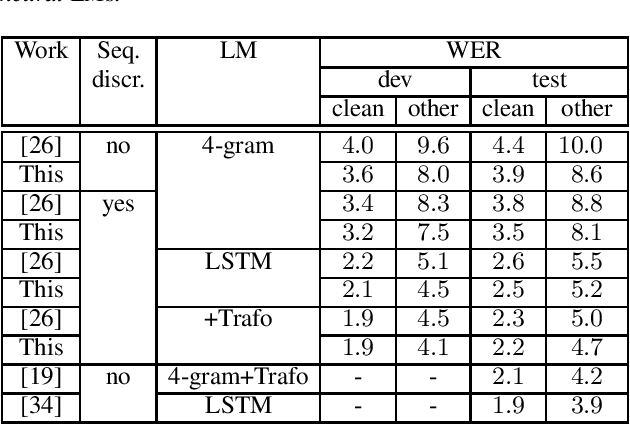
We present our transducer model on Librispeech. We study variants to include an external language model (LM) with shallow fusion and subtract an estimated internal LM. This is justified by a Bayesian interpretation where the transducer model prior is given by the estimated internal LM. The subtraction of the internal LM gives us over 14% relative improvement over normal shallow fusion. Our transducer has a separate probability distribution for the non-blank labels which allows for easier combination with the external LM, and easier estimation of the internal LM. We additionally take care of including the end-of-sentence (EOS) probability of the external LM in the last blank probability which further improves the performance. All our code and setups are published.
Early Stage LM Integration Using Local and Global Log-Linear Combination
May 20, 2020



Sequence-to-sequence models with an implicit alignment mechanism (e.g. attention) are closing the performance gap towards traditional hybrid hidden Markov models (HMM) for the task of automatic speech recognition. One important factor to improve word error rate in both cases is the use of an external language model (LM) trained on large text-only corpora. Language model integration is straightforward with the clear separation of acoustic model and language model in classical HMM-based modeling. In contrast, multiple integration schemes have been proposed for attention models. In this work, we present a novel method for language model integration into implicit-alignment based sequence-to-sequence models. Log-linear model combination of acoustic and language model is performed with a per-token renormalization. This allows us to compute the full normalization term efficiently both in training and in testing. This is compared to a global renormalization scheme which is equivalent to applying shallow fusion in training. The proposed methods show good improvements over standard model combination (shallow fusion) on our state-of-the-art Librispeech system. Furthermore, the improvements are persistent even if the LM is exchanged for a more powerful one after training.
Comparison of Lattice-Free and Lattice-Based Sequence Discriminative Training Criteria for LVCSR
Jul 01, 2019



Sequence discriminative training criteria have long been a standard tool in automatic speech recognition for improving the performance of acoustic models over their maximum likelihood / cross entropy trained counterparts. While previously a lattice approximation of the search space has been necessary to reduce computational complexity, recently proposed methods use other approximations to dispense of the need for the computationally expensive step of separate lattice creation. In this work we present a memory efficient implementation of the forward-backward computation that allows us to use uni-gram word-level language models in the denominator calculation while still doing a full summation on GPU. This allows for a direct comparison of lattice-based and lattice-free sequence discriminative training criteria such as MMI and sMBR, both using the same language model during training. We compared performance, speed of convergence, and stability on large vocabulary continuous speech recognition tasks like Switchboard and Quaero. We found that silence modeling seriously impacts the performance in the lattice-free case and needs special treatment. In our experiments lattice-free MMI comes on par with its lattice-based counterpart. Lattice-based sMBR still outperforms all lattice-free training criteria.