 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training of Neural Transducer for Speech Recognition
Paper and Code
Apr 22, 2022


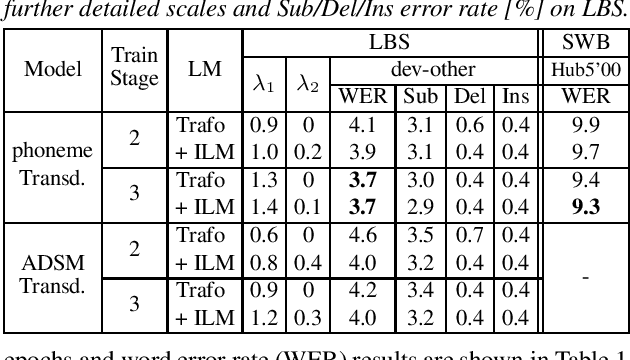
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.