 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Learning of Subword Dependent Model Scales
Oct 18, 2021
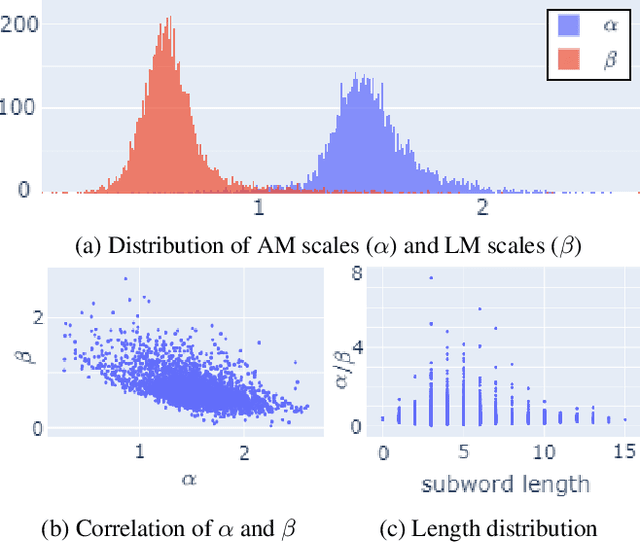

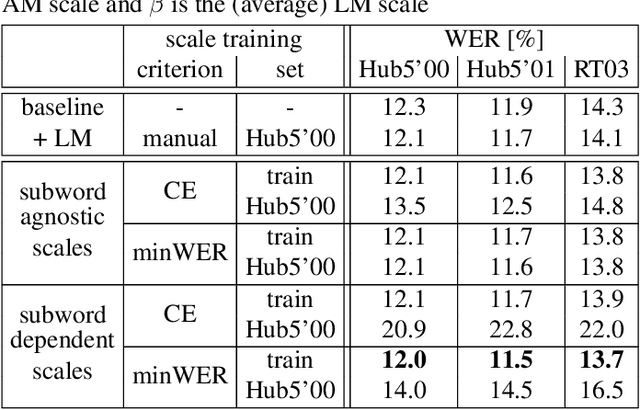
To improve the performance of state-of-the-art automatic speech recognition systems it is common practice to include external knowledge sources such as language models or prior corrections. This is usually done via log-linear model combination using separate scaling parameters for each model. Typically these parameters are manually optimized on some held-out data. In this work we propose to optimize these scaling parameters via automatic differentiation and stochastic gradient decent similar to the neural network model parameters. We show on the LibriSpeech (LBS) and Switchboard (SWB) corpora that the model scales for a combination of attentionbased encoder-decoder acoustic model and language model can be learned as effectively as with manual tuning. We further extend this approach to subword dependent model scales which could not be tuned manually which leads to 7% improvement on LBS and 3% on SWB. We also show that joint training of scales and model parameters is possible and gives additional 6% improvement on LBS.