 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Learnable Feature Extraction for Automatic Speech Recognition
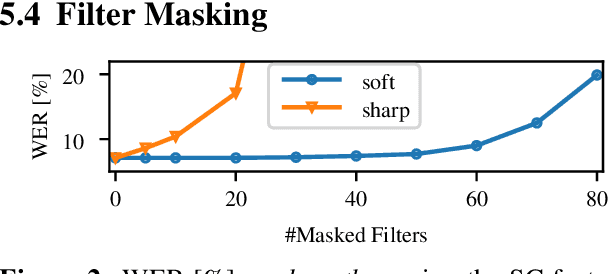
Jun 11, 2025Neural front-ends are an appealing alternative to traditional, fixed feature extraction pipelines for automatic speech recognition (ASR) systems since they can be directly trained to fit the acoustic model. However, their performance often falls short compared to classical methods, which we show is largely due to their increased susceptibility to overfitting. This work therefore investigates regularization methods for training ASR models with learnable feature extraction front-ends. First, we examine audio perturbation methods and show that larger relative improvements can be obtained for learnable features. Additionally, we identify two limitations in the standard use of SpecAugment for these front-ends and propose masking in the short time Fourier transform (STFT)-domain as a simple but effective modification to address these challenges. Finally, integrating both regularization approaches effectively closes the performance gap between traditional and learnable features.
Mixture Encoder Supporting Continuous Speech Separation for Meeting Recognition
Sep 15, 2023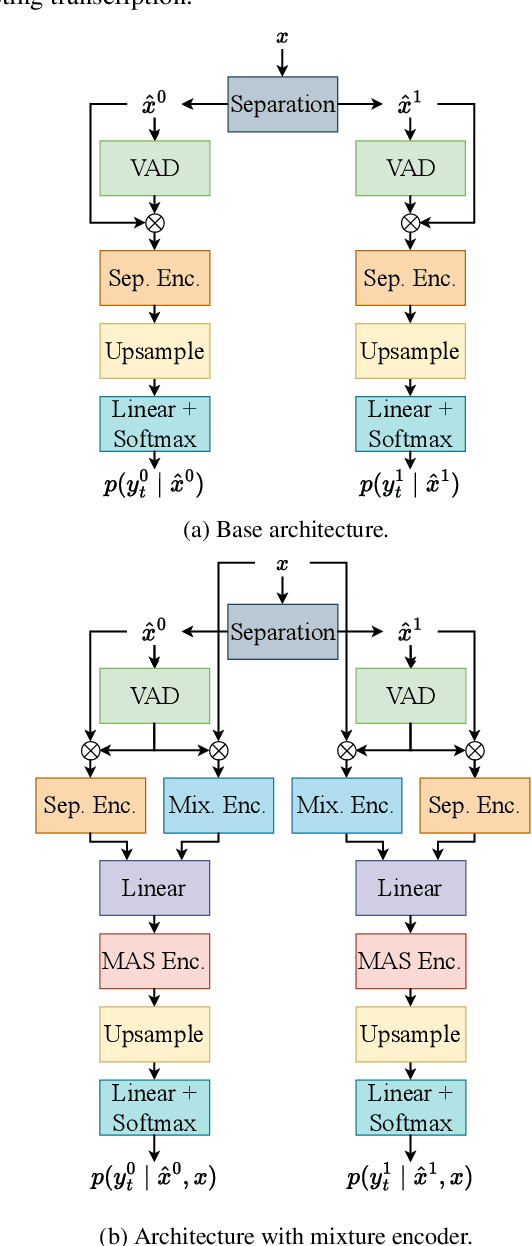



Many real-life applications of automatic speech recognition (ASR) require processing of overlapped speech. A commonmethod involves first separating the speech into overlap-free streams and then performing ASR on the resulting signals. Recently, the inclusion of a mixture encoder in the ASR model has been proposed. This mixture encoder leverages the original overlapped speech to mitigate the effect of artifacts introduced by the speech separation. Previously, however, the method only addressed two-speaker scenarios. In this work, we extend this approach to more natural meeting contexts featuring an arbitrary number of speakers and dynamic overlaps. We evaluate the performance using different speech separators, including the powerful TF-GridNet model. Our experiments show state-of-the-art performance on the LibriCSS dataset and highlight the advantages of the mixture encoder. Furthermore, they demonstrate the strong separation of TF-GridNet which largely closes the gap between previous methods and oracle separation.
Comparative Analysis of the wav2vec 2.0 Feature Extractor
Aug 08, 2023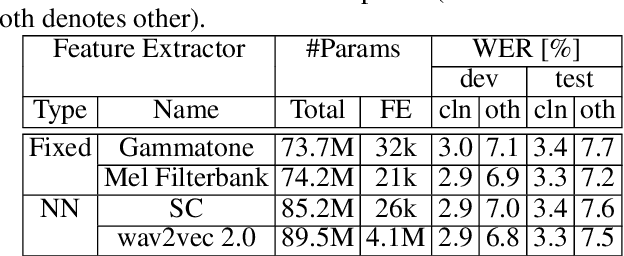
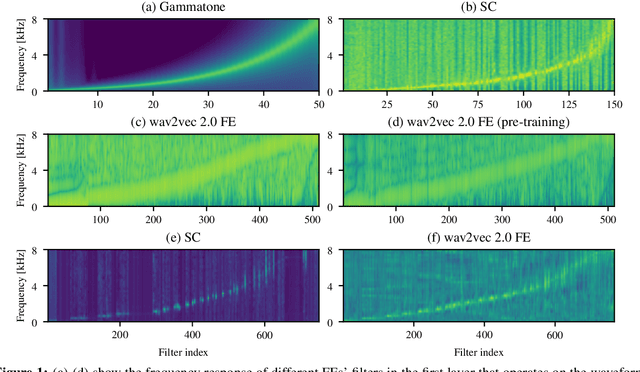
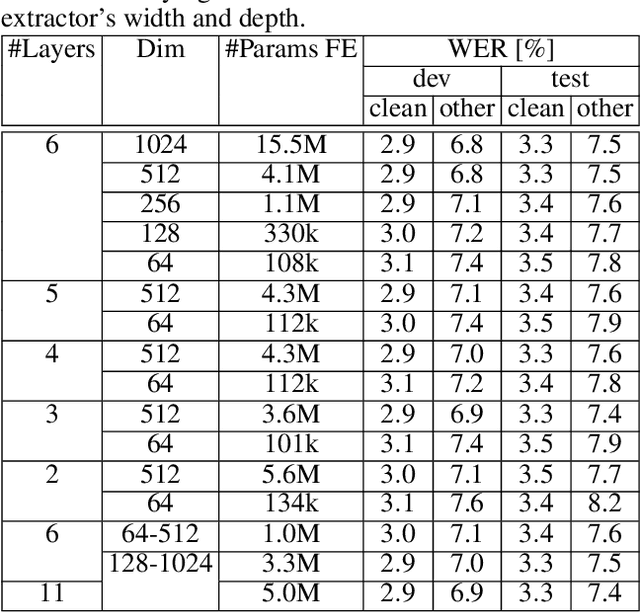
Automatic speech recognition (ASR) systems typically use handcrafted feature extraction pipelines. To avoid their inherent information loss and to achieve more consistent modeling from speech to transcribed text, neural raw waveform feature extractors (FEs) are an appealing approach. Also the wav2vec 2.0 model, which has recently gained large popularity, uses a convolutional FE which operates directly on the speech waveform. However, it is not yet studied extensively in the literature. In this work, we study its capability to replace the standard feature extraction methods in a connectionist temporal classification (CTC) ASR model and compare it to an alternative neural FE. We show that both are competitive with traditional FEs on the LibriSpeech benchmark and analyze the effect of the individual components. Furthermore, we analyze the learned filters and show that the most important information for the ASR system is obtained by a set of bandpass filters.
Mixture Encoder for Joint Speech Separation and Recognition
Jun 21, 2023Multi-speaker automatic speech recognition (ASR) is crucial for many real-world applications, but it requires dedicated modeling techniques. Existing approaches can be divided into modular and end-to-end methods. Modular approaches separate speakers and recognize each of them with a single-speaker ASR system. End-to-end models process overlapped speech directly in a single, powerful neural network. This work proposes a middle-ground approach that leverages explicit speech separation similarly to the modular approach but also incorporates mixture speech information directly into the ASR module in order to mitigate the propagation of errors made by the speech separator. We also explore a way to exchange cross-speaker context information through a layer that combines information of the individual speakers. Our system is optimized through separate and joint training stages and achieves a relative improvement of 7% in word error rate over a purely modular setup on the SMS-WSJ task.
Efficient Use of Large Pre-Trained Models for Low Resource ASR
Oct 26, 2022Automatic speech recognition (ASR) has been established as a well-performing technique for many scenarios where lots of labeled data is available. Additionally, unsupervised representation learning recently helped to tackle tasks with limited data. Following this, hardware limitations and applications give rise to the question how to efficiently take advantage of large pretrained models and reduce their complexity for downstream tasks. In this work, we study a challenging low resource conversational telephony speech corpus from the medical domain in Vietnamese and German. We show the benefits of using unsupervised techniques beyond simple fine-tuning of large pre-trained models, discuss how to adapt them to a practical telephony task including bandwidth transfer and investigate different data conditions for pre-training and fine-tuning. We outperform the project baselines by 22% relative using pretraining techniques. Further gains of 29% can be achieved by refinements of architecture and training and 6% by adding 0.8 h of in-domain adaptation data.
Development of Hybrid ASR Systems for Low Resource Medical Domain Conversational Telephone Speech
Oct 26, 2022



Language barriers present a great challenge in our increasingly connected and global world. Especially within the medical domain, e.g. hospital or emergency room, communication difficulties and delays may lead to malpractice and non-optimal patient care. In the HYKIST project, we consider patient-physician communication, more specifically between a German-speaking physician and an Arabic- or Vietnamese-speaking patient. Currently, a doctor can call the Triaphon service to get assistance from an interpreter in order to help facilitate communication. The HYKIST goal is to support the usually non-professional bilingual interpreter with an automatic speech translation system to improve patient care and help overcome language barriers. In this work, we present our ASR system development efforts for this conversational telephone speech translation task in the medical domain for two languages pairs, data collection, various acoustic model architectures and dialect-induced difficulties.
Feature Replacement and Combination for Hybrid ASR Systems
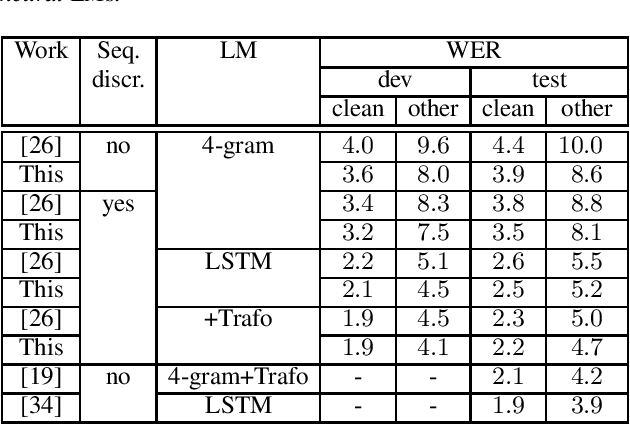
Apr 09, 2021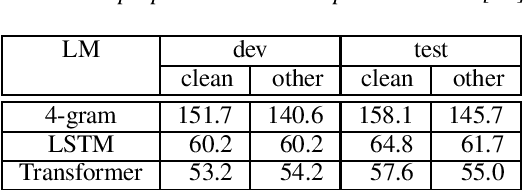


Acoustic modeling of raw waveform and learning feature extractors as part of the neural network classifier has been the goal of many studies in the area of automatic speech recognition (ASR). Recently, one line of research has focused on frameworks that can be pre-trained on audio-only data in an unsupervised fashion and aim at improving downstream ASR tasks. In this work, we investigate the usefulness of one of these front-end frameworks, namely wav2vec, for hybrid ASR systems. In addition to deploying a pre-trained feature extractor, we explore how to make use of an existing acoustic model (AM) trained on the same task with different features as well. Another neural front-end which is only trained together with the supervised ASR loss as well as traditional Gammatone features are applied for comparison. Moreover, it is shown that the AM can be retrofitted with i-vectors for speaker adaptation. Finally, the described features are combined in order to further advance the performance. With the final best system, we obtain a relative improvement of 4% and 6% over our previous best model on the LibriSpeech test-clean and test-other sets.