 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Learnable Feature Extraction for Automatic Speech Recognition
Jun 11, 2025Neural front-ends are an appealing alternative to traditional, fixed feature extraction pipelines for automatic speech recognition (ASR) systems since they can be directly trained to fit the acoustic model. However, their performance often falls short compared to classical methods, which we show is largely due to their increased susceptibility to overfitting. This work therefore investigates regularization methods for training ASR models with learnable feature extraction front-ends. First, we examine audio perturbation methods and show that larger relative improvements can be obtained for learnable features. Additionally, we identify two limitations in the standard use of SpecAugment for these front-ends and propose masking in the short time Fourier transform (STFT)-domain as a simple but effective modification to address these challenges. Finally, integrating both regularization approaches effectively closes the performance gap between traditional and learnable features.
Running Conventional Automatic Speech Recognition on Memristor Hardware: A Simulated Approach
May 30, 2025Memristor-based hardware offers new possibilities for energy-efficient machine learning (ML) by providing analog in-memory matrix multiplication. Current hardware prototypes cannot fit large neural networks, and related literature covers only small ML models for tasks like MNIST or single word recognition. Simulation can be used to explore how hardware properties affect larger models, but existing software assumes simplified hardware. We propose a PyTorch-based library based on "Synaptogen" to simulate neural network execution with accurately captured memristor hardware properties. For the first time, we show how an ML system with millions of parameters would behave on memristor hardware, using a Conformer trained on the speech recognition task TED-LIUMv2 as example. With adjusted quantization-aware training, we limit the relative degradation in word error rate to 25% when using a 3-bit weight precision to execute linear operations via simulated analog computation.
On the Effect of Purely Synthetic Training Data for Different Automatic Speech Recognition Architectures
Jul 25, 2024In this work we evaluate the utility of synthetic data for training automatic speech recognition (ASR). We use the ASR training data to train a text-to-speech (TTS) system similar to FastSpeech-2. With this TTS we reproduce the original training data, training ASR systems solely on synthetic data. For ASR, we use three different architectures, attention-based encoder-decoder, hybrid deep neural network hidden Markov model and a Gaussian mixture hidden Markov model, showing the different sensitivity of the models to synthetic data generation. In order to extend previous work, we present a number of ablation studies on the effectiveness of synthetic vs. real training data for ASR. In particular we focus on how the gap between training on synthetic and real data changes by varying the speaker embedding or by scaling the model size. For the latter we show that the TTS models generalize well, even when training scores indicate overfitting.
On the Relevance of Phoneme Duration Variability of Synthesized Training Data for Automatic Speech Recognition
Oct 12, 2023



Synthetic data generated by text-to-speech (TTS) systems can be used to improve automatic speech recognition (ASR) systems in low-resource or domain mismatch tasks. It has been shown that TTS-generated outputs still do not have the same qualities as real data. In this work we focus on the temporal structure of synthetic data and its relation to ASR training. By using a novel oracle setup we show how much the degradation of synthetic data quality is influenced by duration modeling in non-autoregressive (NAR) TTS. To get reference phoneme durations we use two common alignment methods, a hidden Markov Gaussian-mixture model (HMM-GMM) aligner and a neural connectionist temporal classification (CTC) aligner. Using a simple algorithm based on random walks we shift phoneme duration distributions of the TTS system closer to real durations, resulting in an improvement of an ASR system using synthetic data in a semi-supervised setting.
Comparing the Benefit of Synthetic Training Data for Various Automatic Speech Recognition Architectures
Apr 12, 2021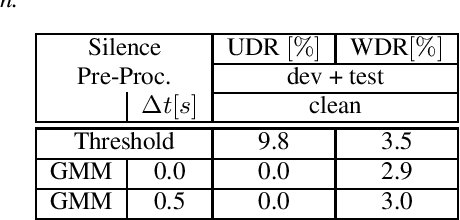
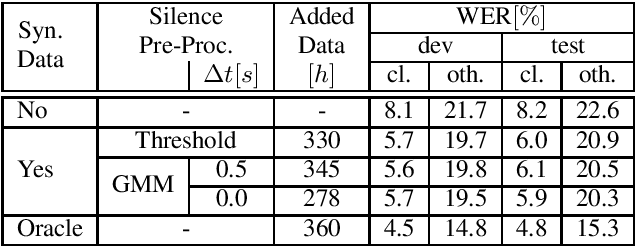
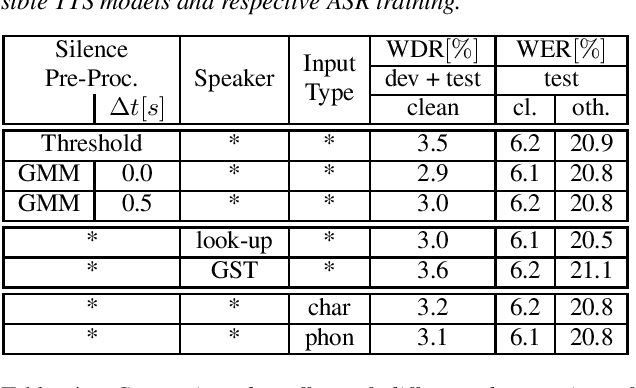
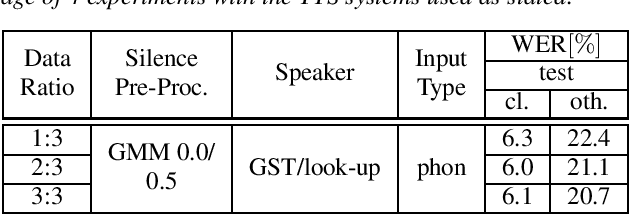
Recent publications on automatic-speech-recognition (ASR) have a strong focus on attention encoder-decoder (AED) architectures which work well for large datasets, but tend to overfit when applied in low resource scenarios. One solution to tackle this issue is to generate synthetic data with a trained text-to-speech system (TTS) if additional text is available. This was successfully applied in many publications with AED systems. We present a novel approach of silence correction in the data pre-processing for TTS systems which increases the robustness when training on corpora targeted for ASR applications. In this work we do not only show the successful application of synthetic data for AED systems, but also test the same method on a highly optimized state-of-the-art Hybrid ASR system and a competitive monophone based system using connectionist-temporal-classification (CTC). We show that for the later systems the addition of synthetic data only has a minor effect, but they still outperform the AED systems by a large margin on LibriSpeech-100h. We achieve a final word-error-rate of 3.3%/10.0% with a Hybrid system on the clean/noisy test-sets, surpassing any previous state-of-the-art systems that do not include unlabeled audio data.