 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effect of Label Topology and Training Criterion on ASR Performance and Alignment Quality
Jul 16, 2024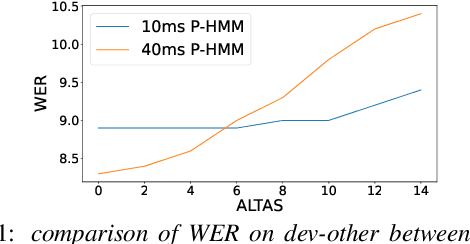
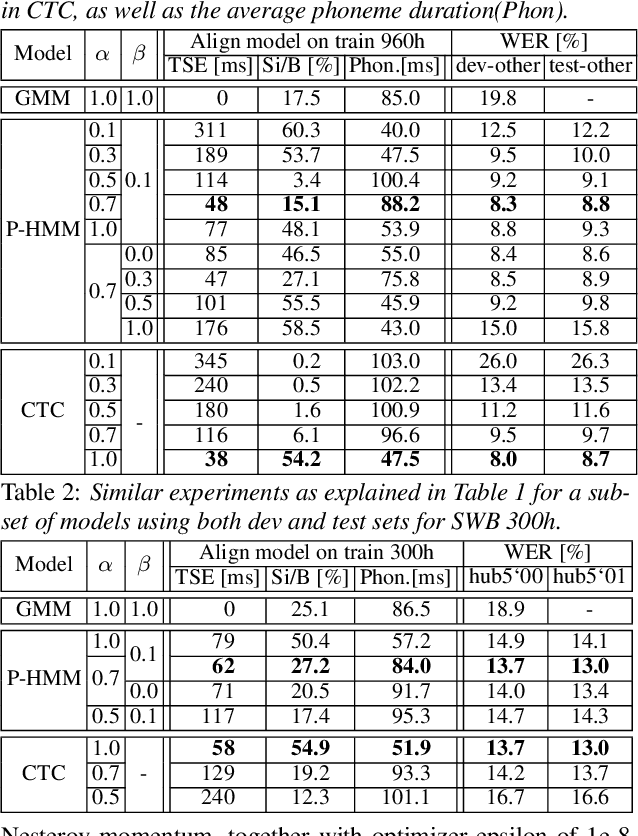
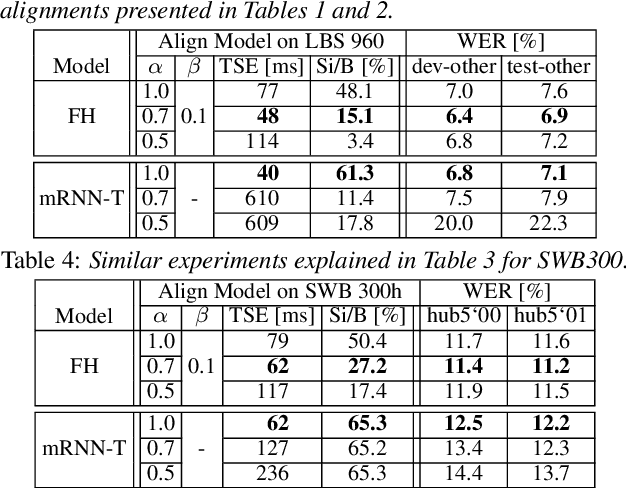
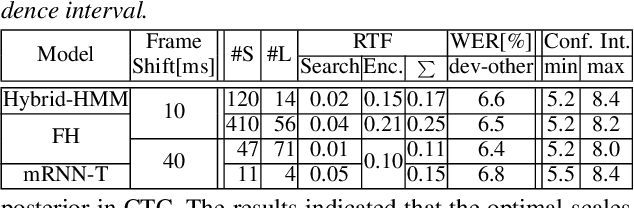
The ongoing research scenario for automatic speech recognition (ASR) envisions a clear division between end-to-end approaches and classic modular systems. Even though a high-level comparison between the two approaches in terms of their requirements and (dis)advantages is commonly addressed, a closer comparison under similar conditions is not readily available in the literature. In this work, we present a comparison focused on the label topology and training criterion. We compare two discriminative alignment models with hidden Markov model (HMM) and connectionist temporal classification topology, and two first-order label context ASR models utilizing factored HMM and strictly monotonic recurrent neural network transducer, respectively. We use different measurements for the evaluation of the alignment quality, and compare word error rate and real time factor of our best systems. Experiments are conducted on the LibriSpeech 960h and Switchboard 300h tasks.
Competitive and Resource Efficient Factored Hybrid HMM Systems are Simpler Than You Think
Jun 15, 2023Building competitive hybrid hidden Markov model~(HMM) systems for automatic speech recognition~(ASR) requires a complex multi-stage pipeline consisting of several training criteria. The recent sequence-to-sequence models offer the advantage of having simpler pipelines that can start from-scratch. We propose a purely neural based single-stage from-scratch pipeline for a context-dependent hybrid HMM that offers similar simplicity. We use an alignment from a full-sum trained zero-order posterior HMM with a BLSTM encoder. We show that with this alignment we can build a Conformer factored hybrid that performs even better than both a state-of-the-art classic hybrid and a factored hybrid trained with alignments taken from more complex Gaussian mixture based systems. Our finding is confirmed on Switchboard 300h and LibriSpeech 960h tasks with comparable results to other approaches in the literature, and by additionally relying on a responsible choice of available computational resources.
Improving And Analyzing Neural Speaker Embeddings for ASR
Jan 11, 2023



Neural speaker embeddings encode the speaker's speech characteristics through a DNN model and are prevalent for speaker verification tasks. However, few studies have investigated the usage of neural speaker embeddings for an ASR system. In this work, we present our efforts w.r.t integrating neural speaker embeddings into a conformer based hybrid HMM ASR system. For ASR, our improved embedding extraction pipeline in combination with the Weighted-Simple-Add integration method results in x-vector and c-vector reaching on par performance with i-vectors. We further compare and analyze different speaker embeddings. We present our acoustic model improvements obtained by switching from newbob learning rate schedule to one cycle learning schedule resulting in a ~3% relative WER reduction on Switchboard, additionally reducing the overall training time by 17%. By further adding neural speaker embeddings, we gain additional ~3% relative WER improvement on Hub5'00. Our best Conformer-based hybrid ASR system with speaker embeddings achieves 9.0% WER on Hub5'00 and Hub5'01 with training on SWB 300h.
Enhancing and Adversarial: Improve ASR with Speaker Labels
Nov 11, 2022



ASR can be improved by multi-task learning (MTL) with domain enhancing or domain adversarial training, which are two opposite objectives with the aim to increase/decrease domain variance towards domain-aware/agnostic ASR, respectively. In this work, we study how to best apply these two opposite objectives with speaker labels to improve conformer-based ASR. We also propose a novel adaptive gradient reversal layer for stable and effective adversarial training without tuning effort. Detailed analysis and experimental verification are conducted to show the optimal positions in the ASR neural network (NN) to apply speaker enhancing and adversarial training. We also explore their combination for further improvement, achieving the same performance as i-vectors plus adversarial training. Our best speaker-based MTL achieves 7\% relative improvement on the Switchboard Hub5'00 set. We also investigate the effect of such speaker-based MTL w.r.t. cleaner dataset and weaker ASR NN.
Development of Hybrid ASR Systems for Low Resource Medical Domain Conversational Telephone Speech
Oct 26, 2022



Language barriers present a great challenge in our increasingly connected and global world. Especially within the medical domain, e.g. hospital or emergency room, communication difficulties and delays may lead to malpractice and non-optimal patient care. In the HYKIST project, we consider patient-physician communication, more specifically between a German-speaking physician and an Arabic- or Vietnamese-speaking patient. Currently, a doctor can call the Triaphon service to get assistance from an interpreter in order to help facilitate communication. The HYKIST goal is to support the usually non-professional bilingual interpreter with an automatic speech translation system to improve patient care and help overcome language barriers. In this work, we present our ASR system development efforts for this conversational telephone speech translation task in the medical domain for two languages pairs, data collection, various acoustic model architectures and dialect-induced difficulties.
Efficient Use of Large Pre-Trained Models for Low Resource ASR
Oct 26, 2022Automatic speech recognition (ASR) has been established as a well-performing technique for many scenarios where lots of labeled data is available. Additionally, unsupervised representation learning recently helped to tackle tasks with limited data. Following this, hardware limitations and applications give rise to the question how to efficiently take advantage of large pretrained models and reduce their complexity for downstream tasks. In this work, we study a challenging low resource conversational telephony speech corpus from the medical domain in Vietnamese and German. We show the benefits of using unsupervised techniques beyond simple fine-tuning of large pre-trained models, discuss how to adapt them to a practical telephony task including bandwidth transfer and investigate different data conditions for pre-training and fine-tuning. We outperform the project baselines by 22% relative using pretraining techniques. Further gains of 29% can be achieved by refinements of architecture and training and 6% by adding 0.8 h of in-domain adaptation data.
Improving the Training Recipe for a Robust Conformer-based Hybrid Model
Jun 26, 2022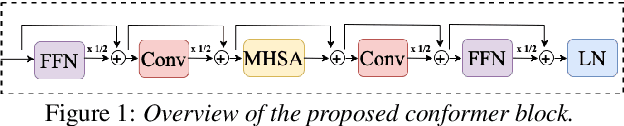
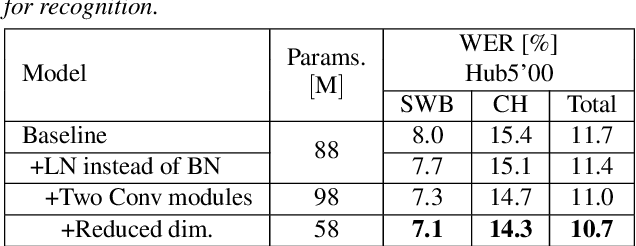

Speaker adaptation is important to build robust automatic speech recognition (ASR) systems. In this work, we investigate various methods for speaker adaptive training (SAT) based on feature-space approaches for a conformer-based acoustic model (AM) on the Switchboard 300h dataset. We propose a method, called Weighted-Simple-Add, which adds weighted speaker information vectors to the input of the multi-head self-attention module of the conformer AM. Using this method for SAT, we achieve 3.5% and 4.5% relative improvement in terms of WER on the CallHome part of Hub5'00 and Hub5'01 respectively. Moreover, we build on top of our previous work where we proposed a novel and competitive training recipe for a conformer-based hybrid AM. We extend and improve this recipe where we achieve 11% relative improvement in terms of word-error-rate (WER) on Switchboard 300h Hub5'00 dataset. We also make this recipe efficient by reducing the total number of parameters by 34% relative.
Conformer-based Hybrid ASR System for Switchboard Dataset
Nov 05, 2021



The recently proposed conformer architecture has been successfully used for end-to-end automatic speech recognition (ASR) architectures achieving state-of-the-art performance on different datasets. To our best knowledge, the impact of using conformer acoustic model for hybrid ASR is not investigated. In this paper, we present and evaluate a competitive conformer-based hybrid model training recipe. We study different training aspects and methods to improve word-error-rate as well as to increase training speed. We apply time downsampling methods for efficient training and use transposed convolutions to upsample the output sequence again. We conduct experiments on Switchboard 300h dataset and our conformer-based hybrid model achieves competitive results compared to other architectures. It generalizes very well on Hub5'01 test set and outperforms the BLSTM-based hybrid model significantly.
Feature Replacement and Combination for Hybrid ASR Systems
Apr 09, 2021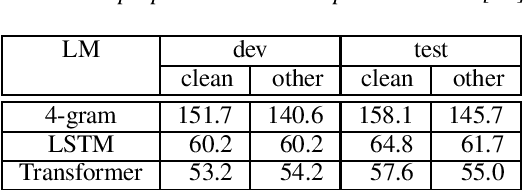


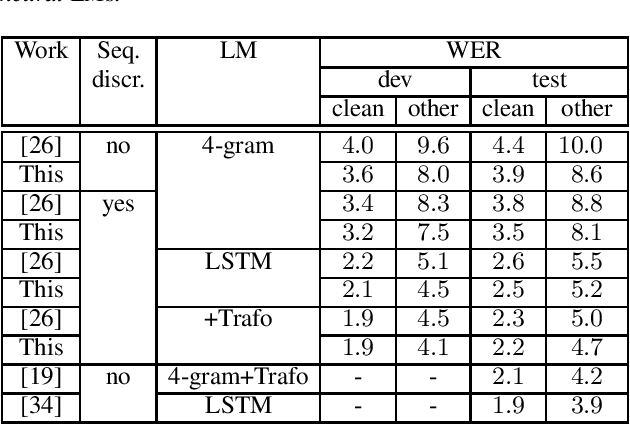
Acoustic modeling of raw waveform and learning feature extractors as part of the neural network classifier has been the goal of many studies in the area of automatic speech recognition (ASR). Recently, one line of research has focused on frameworks that can be pre-trained on audio-only data in an unsupervised fashion and aim at improving downstream ASR tasks. In this work, we investigate the usefulness of one of these front-end frameworks, namely wav2vec, for hybrid ASR systems. In addition to deploying a pre-trained feature extractor, we explore how to make use of an existing acoustic model (AM) trained on the same task with different features as well. Another neural front-end which is only trained together with the supervised ASR loss as well as traditional Gammatone features are applied for comparison. Moreover, it is shown that the AM can be retrofitted with i-vectors for speaker adaptation. Finally, the described features are combined in order to further advance the performance. With the final best system, we obtain a relative improvement of 4% and 6% over our previous best model on the LibriSpeech test-clean and test-other sets.
RWTH ASR Systems for LibriSpeech: Hybrid vs Attention - w/o Data Augmentation
May 08, 2019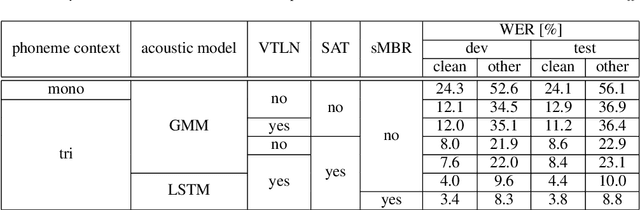
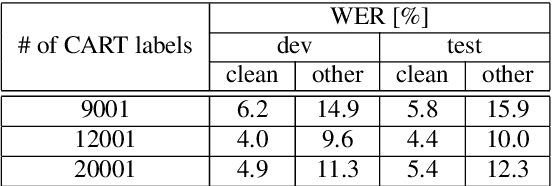
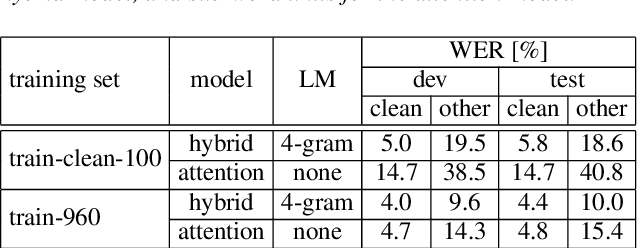
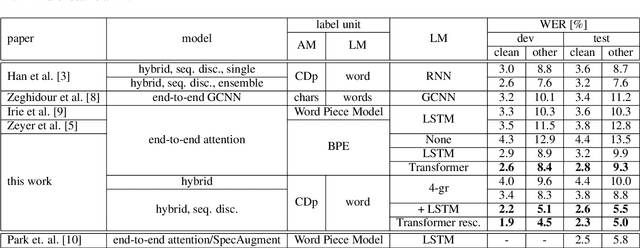
We present state-of-the-art automatic speech recognition (ASR) systems employing a standard hybrid DNN\/HMM architecture compared to an attention-based encoder-decoder design for the LibriSpeech task. Detailed descriptions of the system development, including model design, pretraining schemes, training schedules, and optimization approaches are provided for both system architectures. Both hybrid DNN/HMM and attention-based systems employ bi-directional LSTMs for acoustic modeling/encoding. For language modeling, we employ both LSTM and Transformer based architectures. All our systems are built using RWTHs open-source toolkits RASR and RETURNN. To the best knowledge of the authors, the results obtained when training on the full LibriSpeech training set, are the best published currently, both for the hybrid DNN/HMM and the attention-based systems. Our single hybrid system even outperforms previous results obtained from combining eight single systems. Our comparison shows that on the LibriSpeech 960h task, the hybrid DNN/HMM system outperforms the attention-based system by 15% relative on the clean and 40% relative on the other test sets in terms of word error rate. Moreover, experiments on a reduced 100h-subset of the LibriSpeech training corpus even show a more pronounced margin between the hybrid DNN/HMM and attention-based architectures.