 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRWTH ASR Systems for LibriSpeech: Hybrid vs Attention - w/o Data Augmentation
Paper and Code
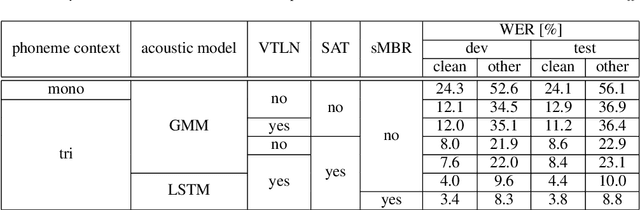
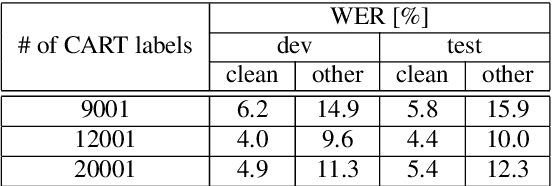
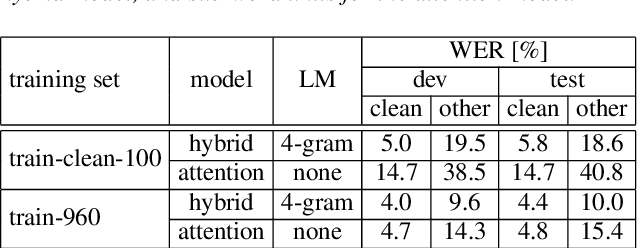
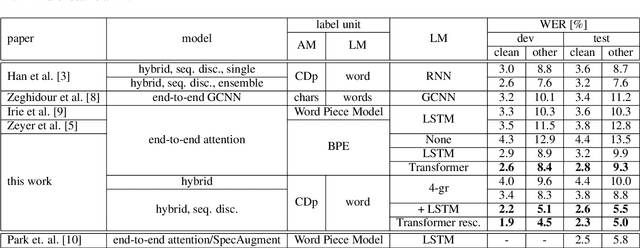
We present state-of-the-art automatic speech recognition (ASR) systems employing a standard hybrid DNN\/HMM architecture compared to an attention-based encoder-decoder design for the LibriSpeech task. Detailed descriptions of the system development, including model design, pretraining schemes, training schedules, and optimization approaches are provided for both system architectures. Both hybrid DNN/HMM and attention-based systems employ bi-directional LSTMs for acoustic modeling/encoding. For language modeling, we employ both LSTM and Transformer based architectures. All our systems are built using RWTHs open-source toolkits RASR and RETURNN. To the best knowledge of the authors, the results obtained when training on the full LibriSpeech training set, are the best published currently, both for the hybrid DNN/HMM and the attention-based systems. Our single hybrid system even outperforms previous results obtained from combining eight single systems. Our comparison shows that on the LibriSpeech 960h task, the hybrid DNN/HMM system outperforms the attention-based system by 15% relative on the clean and 40% relative on the other test sets in terms of word error rate. Moreover, experiments on a reduced 100h-subset of the LibriSpeech training corpus even show a more pronounced margin between the hybrid DNN/HMM and attention-based architectures.