 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Language Models for Speech Recognition
Apr 15, 2026Diffusion language models have recently emerged as a leading alternative to standard language models, due to their ability for bidirectional attention and parallel text generation. In this work, we explore variants for their use in speech recognition. Specifically, we introduce a comprehensive guide to incorporating masked diffusion language models (MDLM) and uniform-state diffusion models (USDMs) for rescoring ASR hypotheses. Additionally, we design a new joint-decoding method that combines CTC and USDM by integrating the framewise probability distributions derived from CTC with the labelwise probability distributions computed by USDM at each decoding step, thereby generating new candidates that combine strong language knowledge from USDM and acoustic information from CTC. Our findings reveal that USDM, as well as MDLM, can significantly improve the accuracy of recognized text. We publish all our code and recipes.
LLMs and Speech: Integration vs. Combination
Mar 16, 2026In this work, we study how to best utilize pre-trained LLMs for automatic speech recognition. Specifically, we compare the tight integration of an acoustic model (AM) with the LLM ("speech LLM") to the traditional way of combining AM and LLM via shallow fusion. For tight integration, we provide ablations on the effect of different label units, fine-tuning strategies, LLM sizes and pre-training data, attention interfaces, encoder downsampling, text prompts, and length normalization. Additionally, we investigate joint recognition with a CTC model to mitigate hallucinations of speech LLMs and present effective optimizations for this joint recognition. For shallow fusion, we investigate the effect of fine-tuning the LLM on the transcriptions using different label units, and we compare rescoring AM hypotheses to single-pass recognition with label-wise or delayed fusion of AM and LLM scores. We train on Librispeech and Loquacious and evaluate our models on the HuggingFace ASR leaderboard.
Reproducing and Dissecting Denoising Language Models for Speech Recognition
Dec 15, 2025Denoising language models (DLMs) have been proposed as a powerful alternative to traditional language models (LMs) for automatic speech recognition (ASR), motivated by their ability to use bidirectional context and adapt to a specific ASR model's error patterns. However, the complexity of the DLM training pipeline has hindered wider investigation. This paper presents the first independent, large-scale empirical study of DLMs. We build and release a complete, reproducible pipeline to systematically investigate the impact of key design choices. We evaluate dozens of configurations across multiple axes, including various data augmentation techniques (e.g., SpecAugment, dropout, mixup), different text-to-speech systems, and multiple decoding strategies. Our comparative analysis in a common subword vocabulary setting demonstrates that DLMs outperform traditional LMs, but only after a distinct compute tipping point. While LMs are more efficient at lower budgets, DLMs scale better with longer training, mirroring behaviors observed in diffusion language models. However, we observe smaller improvements than those reported in prior character-based work, which indicates that the DLM's performance is conditional on factors such as the vocabulary. Our analysis reveals that a key factor for improving performance is to condition the DLM on richer information from the ASR's hypothesis space, rather than just a single best guess. To this end, we introduce DLM-sum, a novel method for decoding from multiple ASR hypotheses, which consistently outperforms the previously proposed DSR decoding method. We believe our findings and public pipeline provide a crucial foundation for the community to better understand, improve, and build upon this promising class of models. The code is publicly available at https://github.com/rwth-i6/2025-denoising-lm/.
Dynamic Acoustic Model Architecture Optimization in Training for ASR
Jun 16, 2025Architecture design is inherently complex. Existing approaches rely on either handcrafted rules, which demand extensive empirical expertise, or automated methods like neural architecture search, which are computationally intensive. In this paper, we introduce DMAO, an architecture optimization framework that employs a grow-and-drop strategy to automatically reallocate parameters during training. This reallocation shifts resources from less-utilized areas to those parts of the model where they are most beneficial. Notably, DMAO only introduces negligible training overhead at a given model complexity. We evaluate DMAO through experiments with CTC on LibriSpeech, TED-LIUM-v2 and Switchboard datasets. The results show that, using the same amount of training resources, our proposed DMAO consistently improves WER by up to 6% relatively across various architectures, model sizes, and datasets. Furthermore, we analyze the pattern of parameter redistribution and uncover insightful findings.
The Conformer Encoder May Reverse the Time Dimension
Oct 01, 2024



We sometimes observe monotonically decreasing cross-attention weights in our Conformer-based global attention-based encoder-decoder (AED) models. Further investigation shows that the Conformer encoder internally reverses the sequence in the time dimension. We analyze the initial behavior of the decoder cross-attention mechanism and find that it encourages the Conformer encoder self-attention to build a connection between the initial frames and all other informative frames. Furthermore, we show that, at some point in training, the self-attention module of the Conformer starts dominating the output over the preceding feed-forward module, which then only allows the reversed information to pass through. We propose several methods and ideas of how this flipping can be avoided. Additionally, we investigate a novel method to obtain label-frame-position alignments by using the gradients of the label log probabilities w.r.t. the encoder input frames.
Chunked Attention-based Encoder-Decoder Model for Streaming Speech Recognition
Sep 15, 2023



We study a streamable attention-based encoder-decoder model in which either the decoder, or both the encoder and decoder, operate on pre-defined, fixed-size windows called chunks. A special end-of-chunk (EOC) symbol advances from one chunk to the next chunk, effectively replacing the conventional end-of-sequence symbol. This modification, while minor, situates our model as equivalent to a transducer model that operates on chunks instead of frames, where EOC corresponds to the blank symbol. We further explore the remaining differences between a standard transducer and our model. Additionally, we examine relevant aspects such as long-form speech generalization, beam size, and length normalization. Through experiments on Librispeech and TED-LIUM-v2, and by concatenating consecutive sequences for long-form trials, we find that our streamable model maintains competitive performance compared to the non-streamable variant and generalizes very well to long-form speech.
Monotonic segmental attention for automatic speech recognition
Oct 26, 2022



We introduce a novel segmental-attention model for automatic speech recognition. We restrict the decoder attention to segments to avoid quadratic runtime of global attention, better generalize to long sequences, and eventually enable streaming. We directly compare global-attention and different segmental-attention modeling variants. We develop and compare two separate time-synchronous decoders, one specifically taking the segmental nature into account, yielding further improvements. Using time-synchronous decoding for segmental models is novel and a step towards streaming applications. Our experiments show the importance of a length model to predict the segment boundaries. The final best segmental-attention model using segmental decoding performs better than global-attention, in contrast to other monotonic attention approaches in the literature. Further, we observe that the segmental model generalizes much better to long sequences of up to several minutes.
Why does CTC result in peaky behavior?
Jun 03, 2021
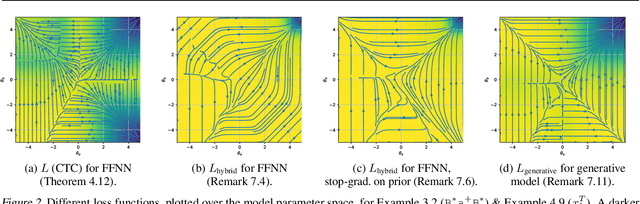

The peaky behavior of CTC models is well known experimentally. However, an understanding about why peaky behavior occurs is missing, and whether this is a good property. We provide a formal analysis of the peaky behavior and gradient descent convergence properties of the CTC loss and related training criteria. Our analysis provides a deep understanding why peaky behavior occurs and when it is suboptimal. On a simple example which should be trivial to learn for any model, we prove that a feed-forward neural network trained with CTC from uniform initialization converges towards peaky behavior with a 100% error rate. Our analysis further explains why CTC only works well together with the blank label. We further demonstrate that peaky behavior does not occur on other related losses including a label prior model, and that this improves convergence.
Equivalence of Segmental and Neural Transducer Modeling: A Proof of Concept
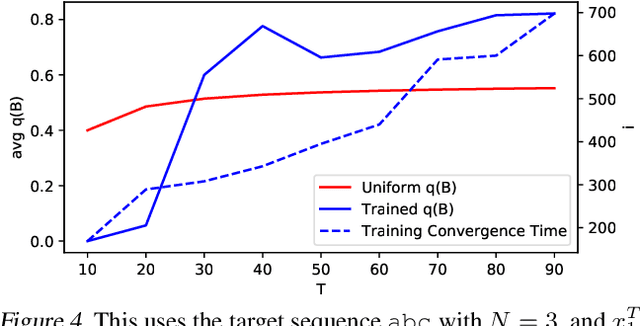
Apr 13, 2021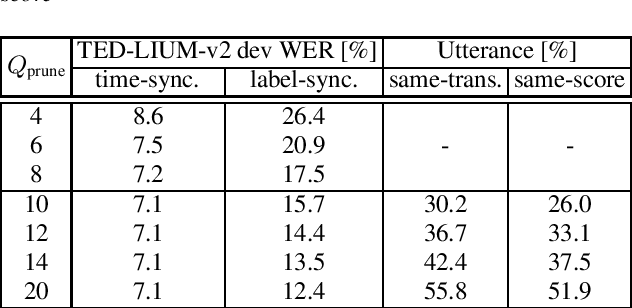
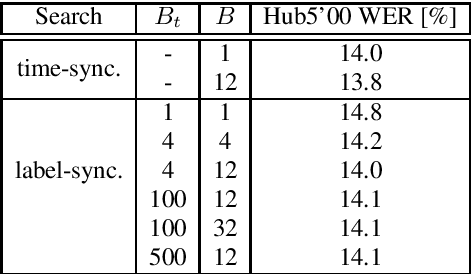
With the advent of direct models in automatic speech recognition (ASR), the formerly prevalent frame-wise acoustic modeling based on hidden Markov models (HMM) diversified into a number of modeling architectures like encoder-decoder attention models, transducer models and segmental models (direct HMM). While transducer models stay with a frame-level model definition, segmental models are defined on the level of label segments, directly. While (soft-)attention-based models avoid explicit alignment, transducer and segmental approach internally do model alignment, either by segment hypotheses or, more implicitly, by emitting so-called blank symbols. In this work, we prove that the widely used class of RNN-Transducer models and segmental models (direct HMM) are equivalent and therefore show equal modeling power. It is shown that blank probabilities translate into segment length probabilities and vice versa. In addition, we provide initial experiments investigating decoding and beam-pruning, comparing time-synchronous and label-/segment-synchronous search strategies and their properties using the same underlying model.
Investigating Methods to Improve Language Model Integration for Attention-based Encoder-Decoder ASR Models
Apr 12, 2021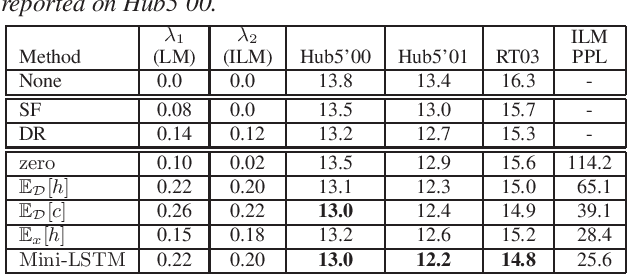


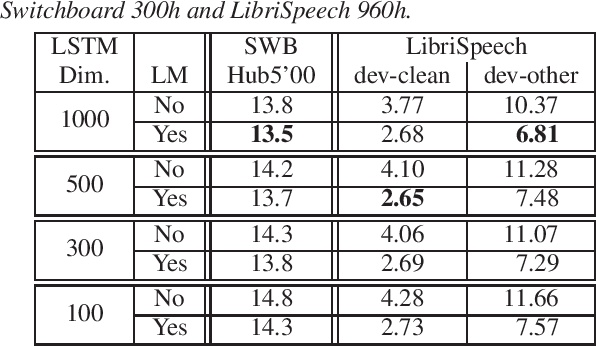
Attention-based encoder-decoder (AED) models learn an implicit internal language model (ILM) from the training transcriptions. The integration with an external LM trained on much more unpaired text usually leads to better performance. A Bayesian interpretation as in the hybrid autoregressive transducer (HAT) suggests dividing by the prior of the discriminative acoustic model, which corresponds to this implicit LM, similarly as in the hybrid hidden Markov model approach. The implicit LM cannot be calculated efficiently in general and it is yet unclear what are the best methods to estimate it. In this work, we compare different approaches from the literature and propose several novel methods to estimate the ILM directly from the AED model. Our proposed methods outperform all previous approaches. We also investigate other methods to suppress the ILM mainly by decreasing the capacity of the AED model, limiting the label context, and also by training the AED model together with a pre-existing LM.