 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs and Speech: Integration vs. Combination
Mar 16, 2026In this work, we study how to best utilize pre-trained LLMs for automatic speech recognition. Specifically, we compare the tight integration of an acoustic model (AM) with the LLM ("speech LLM") to the traditional way of combining AM and LLM via shallow fusion. For tight integration, we provide ablations on the effect of different label units, fine-tuning strategies, LLM sizes and pre-training data, attention interfaces, encoder downsampling, text prompts, and length normalization. Additionally, we investigate joint recognition with a CTC model to mitigate hallucinations of speech LLMs and present effective optimizations for this joint recognition. For shallow fusion, we investigate the effect of fine-tuning the LLM on the transcriptions using different label units, and we compare rescoring AM hypotheses to single-pass recognition with label-wise or delayed fusion of AM and LLM scores. We train on Librispeech and Loquacious and evaluate our models on the HuggingFace ASR leaderboard.
Comprehensive Benchmarking of Machine Learning Methods for Risk Prediction Modelling from Large-Scale Survival Data: A UK Biobank Study
Mar 11, 2025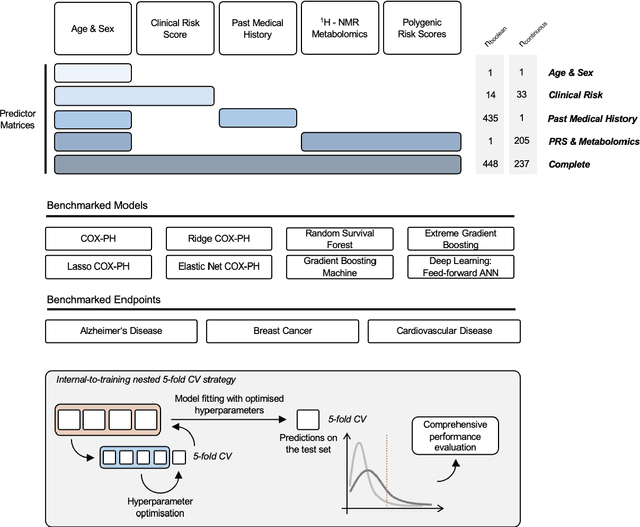
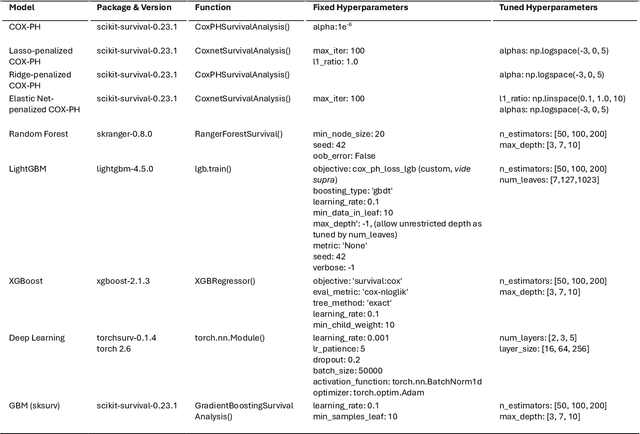
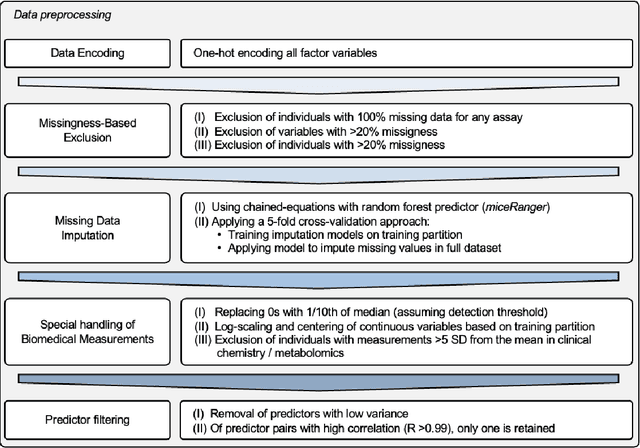
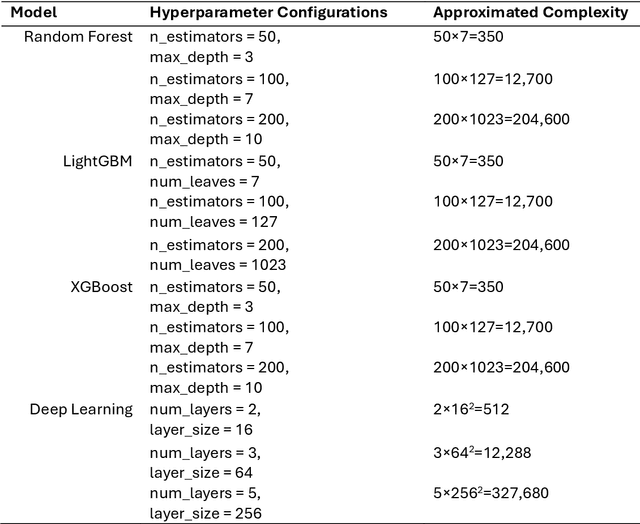
Predictive modelling is vital to guide preventive efforts. Whilst large-scale prospective cohort studies and a diverse toolkit of available machine learning (ML) algorithms have facilitated such survival task efforts, choosing the best-performing algorithm remains challenging. Benchmarking studies to date focus on relatively small-scale datasets and it is unclear how well such findings translate to large datasets that combine omics and clinical features. We sought to benchmark eight distinct survival task implementations, ranging from linear to deep learning (DL) models, within the large-scale prospective cohort study UK Biobank (UKB). We compared discrimination and computational requirements across heterogenous predictor matrices and endpoints. Finally, we assessed how well different architectures scale with sample sizes ranging from n = 5,000 to n = 250,000 individuals. Our results show that discriminative performance across a multitude of metrices is dependent on endpoint frequency and predictor matrix properties, with very robust performance of (penalised) COX Proportional Hazards (COX-PH) models. Of note, there are certain scenarios which favour more complex frameworks, specifically if working with larger numbers of observations and relatively simple predictor matrices. The observed computational requirements were vastly different, and we provide solutions in cases where current implementations were impracticable. In conclusion, this work delineates how optimal model choice is dependent on a variety of factors, including sample size, endpoint frequency and predictor matrix properties, thus constituting an informative resource for researchers working on similar datasets. Furthermore, we showcase how linear models still display a highly effective and scalable platform to perform risk modelling at scale and suggest that those are reported alongside non-linear ML models.
The Conformer Encoder May Reverse the Time Dimension
Oct 01, 2024



We sometimes observe monotonically decreasing cross-attention weights in our Conformer-based global attention-based encoder-decoder (AED) models. Further investigation shows that the Conformer encoder internally reverses the sequence in the time dimension. We analyze the initial behavior of the decoder cross-attention mechanism and find that it encourages the Conformer encoder self-attention to build a connection between the initial frames and all other informative frames. Furthermore, we show that, at some point in training, the self-attention module of the Conformer starts dominating the output over the preceding feed-forward module, which then only allows the reversed information to pass through. We propose several methods and ideas of how this flipping can be avoided. Additionally, we investigate a novel method to obtain label-frame-position alignments by using the gradients of the label log probabilities w.r.t. the encoder input frames.
Monotonic segmental attention for automatic speech recognition
Oct 26, 2022



We introduce a novel segmental-attention model for automatic speech recognition. We restrict the decoder attention to segments to avoid quadratic runtime of global attention, better generalize to long sequences, and eventually enable streaming. We directly compare global-attention and different segmental-attention modeling variants. We develop and compare two separate time-synchronous decoders, one specifically taking the segmental nature into account, yielding further improvements. Using time-synchronous decoding for segmental models is novel and a step towards streaming applications. Our experiments show the importance of a length model to predict the segment boundaries. The final best segmental-attention model using segmental decoding performs better than global-attention, in contrast to other monotonic attention approaches in the literature. Further, we observe that the segmental model generalizes much better to long sequences of up to several minutes.