 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy does CTC result in peaky behavior?
Paper and Code

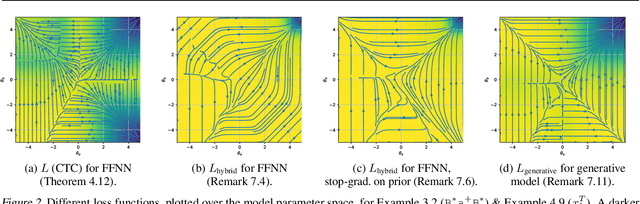

The peaky behavior of CTC models is well known experimentally. However, an understanding about why peaky behavior occurs is missing, and whether this is a good property. We provide a formal analysis of the peaky behavior and gradient descent convergence properties of the CTC loss and related training criteria. Our analysis provides a deep understanding why peaky behavior occurs and when it is suboptimal. On a simple example which should be trivial to learn for any model, we prove that a feed-forward neural network trained with CTC from uniform initialization converges towards peaky behavior with a 100% error rate. Our analysis further explains why CTC only works well together with the blank label. We further demonstrate that peaky behavior does not occur on other related losses including a label prior model, and that this improves convergence.