 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalence of Segmental and Neural Transducer Modeling: A Proof of Concept
Apr 13, 2021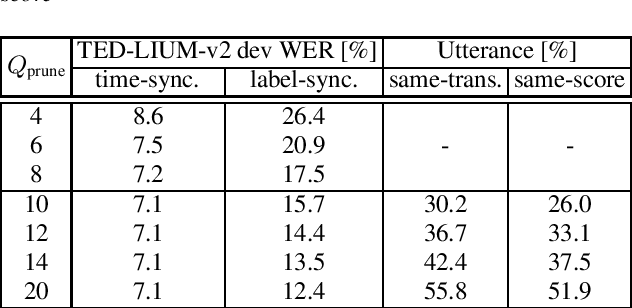
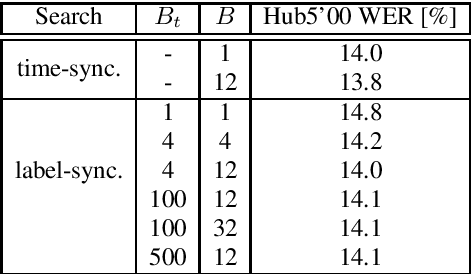
With the advent of direct models in automatic speech recognition (ASR), the formerly prevalent frame-wise acoustic modeling based on hidden Markov models (HMM) diversified into a number of modeling architectures like encoder-decoder attention models, transducer models and segmental models (direct HMM). While transducer models stay with a frame-level model definition, segmental models are defined on the level of label segments, directly. While (soft-)attention-based models avoid explicit alignment, transducer and segmental approach internally do model alignment, either by segment hypotheses or, more implicitly, by emitting so-called blank symbols. In this work, we prove that the widely used class of RNN-Transducer models and segmental models (direct HMM) are equivalent and therefore show equal modeling power. It is shown that blank probabilities translate into segment length probabilities and vice versa. In addition, we provide initial experiments investigating decoding and beam-pruning, comparing time-synchronous and label-/segment-synchronous search strategies and their properties using the same underlying model.
Librispeech Transducer Model with Internal Language Model Prior Correction
Apr 07, 2021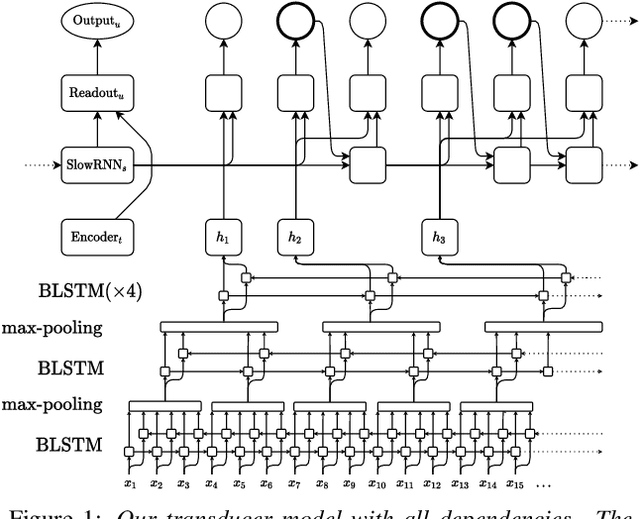

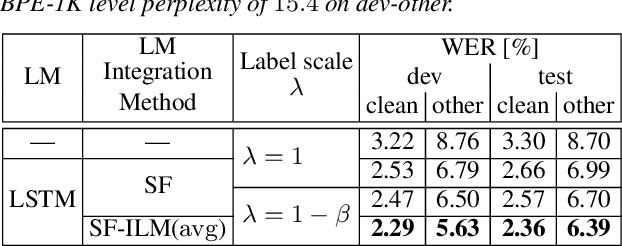
We present our transducer model on Librispeech. We study variants to include an external language model (LM) with shallow fusion and subtract an estimated internal LM. This is justified by a Bayesian interpretation where the transducer model prior is given by the estimated internal LM. The subtraction of the internal LM gives us over 14% relative improvement over normal shallow fusion. Our transducer has a separate probability distribution for the non-blank labels which allows for easier combination with the external LM, and easier estimation of the internal LM. We additionally take care of including the end-of-sentence (EOS) probability of the external LM in the last blank probability which further improves the performance. All our code and setups are published.
A New Training Pipeline for an Improved Neural Transducer
May 19, 2020
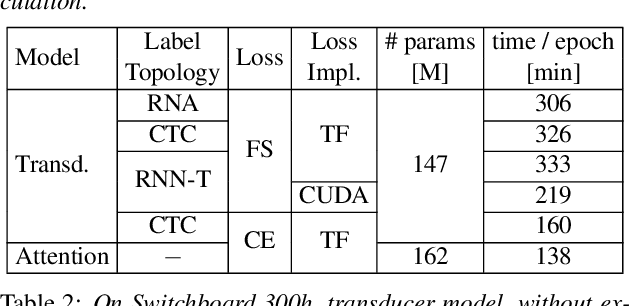
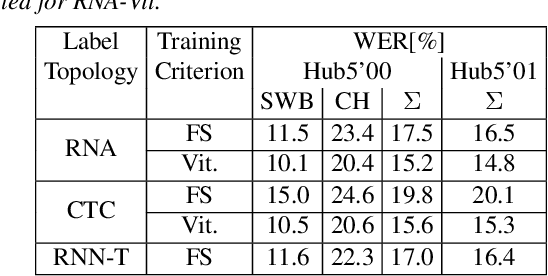

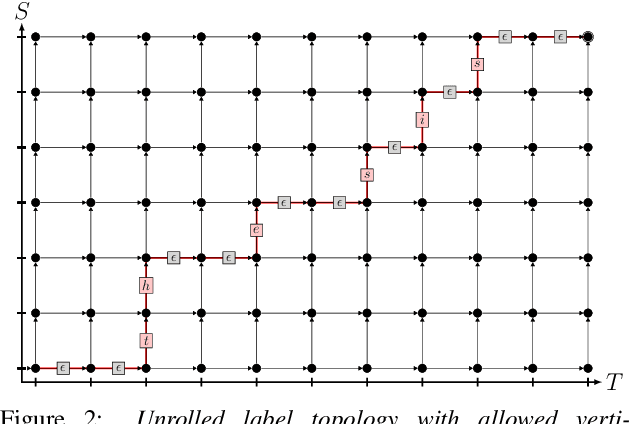
The RNN transducer is a promising end-to-end model candidate. We compare the original training criterion with the full marginalization over all alignments, to the commonly used maximum approximation, which simplifies, improves and speeds up our training. We also generalize from the original neural network model and study more powerful models, made possible due to the maximum approximation. We further generalize the output label topology to cover RNN-T, RNA and CTC. We perform several studies among all these aspects, including a study on the effect of external alignments. We find that the transducer model generalizes much better on longer sequences than the attention model. Our final transducer model outperforms our attention model on Switchboard 300h by over 6% relative WER.