 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Acoustic Model Architecture Optimization in Training for ASR
Jun 16, 2025Architecture design is inherently complex. Existing approaches rely on either handcrafted rules, which demand extensive empirical expertise, or automated methods like neural architecture search, which are computationally intensive. In this paper, we introduce DMAO, an architecture optimization framework that employs a grow-and-drop strategy to automatically reallocate parameters during training. This reallocation shifts resources from less-utilized areas to those parts of the model where they are most beneficial. Notably, DMAO only introduces negligible training overhead at a given model complexity. We evaluate DMAO through experiments with CTC on LibriSpeech, TED-LIUM-v2 and Switchboard datasets. The results show that, using the same amount of training resources, our proposed DMAO consistently improves WER by up to 6% relatively across various architectures, model sizes, and datasets. Furthermore, we analyze the pattern of parameter redistribution and uncover insightful findings.
Efficient Supernet Training with Orthogonal Softmax for Scalable ASR Model Compression
Jan 31, 2025ASR systems are deployed across diverse environments, each with specific hardware constraints. We use supernet training to jointly train multiple encoders of varying sizes, enabling dynamic model size adjustment to fit hardware constraints without redundant training. Moreover, we introduce a novel method called OrthoSoftmax, which applies multiple orthogonal softmax functions to efficiently identify optimal subnets within the supernet, avoiding resource-intensive search. This approach also enables more flexible and precise subnet selection by allowing selection based on various criteria and levels of granularity. Our results with CTC on Librispeech and TED-LIUM-v2 show that FLOPs-aware component-wise selection achieves the best overall performance. With the same number of training updates from one single job, WERs for all model sizes are comparable to or slightly better than those of individually trained models. Furthermore, we analyze patterns in the selected components and reveal interesting insights.
RASR2: The RWTH ASR Toolkit for Generic Sequence-to-sequence Speech Recognition
May 28, 2023Modern public ASR tools usually provide rich support for training various sequence-to-sequence (S2S) models, but rather simple support for decoding open-vocabulary scenarios only. For closed-vocabulary scenarios, public tools supporting lexical-constrained decoding are usually only for classical ASR, or do not support all S2S models. To eliminate this restriction on research possibilities such as modeling unit choice, we present RASR2 in this work, a research-oriented generic S2S decoder implemented in C++. It offers a strong flexibility/compatibility for various S2S models, language models, label units/topologies and neural network architectures. It provides efficient decoding for both open- and closed-vocabulary scenarios based on a generalized search framework with rich support for different search modes and settings. We evaluate RASR2 with a wide range of experiments on both switchboard and Librispeech corpora. Our source code is public online.
Improving Factored Hybrid HMM Acoustic Modeling without State Tying
Jan 24, 2022
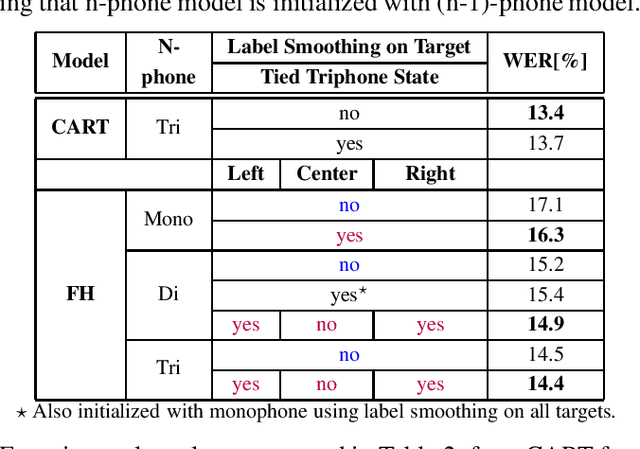
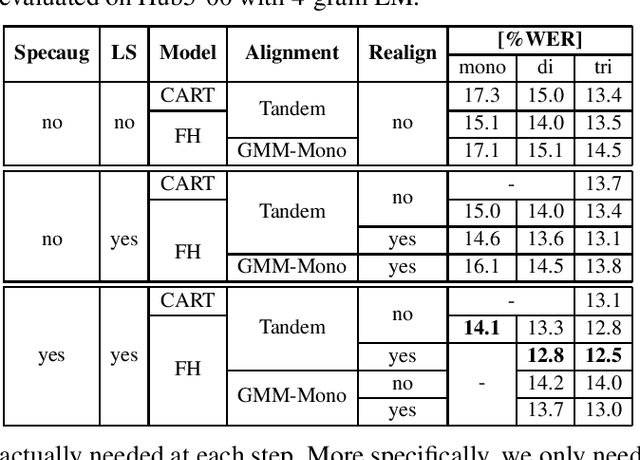
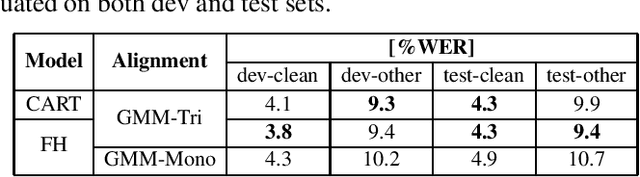
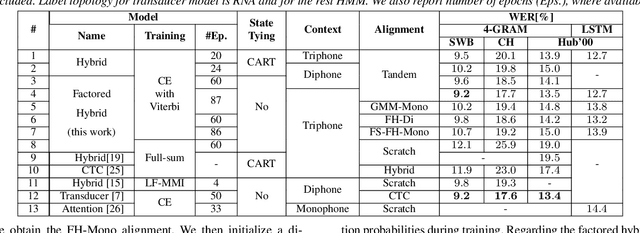
In this work, we show that a factored hybrid hidden Markov model (FH-HMM) which is defined without any phonetic state-tying outperforms a state-of-the-art hybrid HMM. The factored hybrid HMM provides a link to transducer models in the way it models phonetic (label) context while preserving the strict separation of acoustic and language model of the hybrid HMM approach. Furthermore, we show that the factored hybrid model can be trained from scratch without using phonetic state-tying in any of the training steps. Our modeling approach enables triphone context while avoiding phonetic state-tying by a decomposition into locally normalized factored posteriors for monophones/HMM states in phoneme context. Experimental results are provided for Switchboard 300h and LibriSpeech. On the former task we also show that by avoiding the phonetic state-tying step, the factored hybrid can take better advantage of regularization techniques during training, compared to the standard hybrid HMM with phonetic state-tying based on classification and regression trees (CART).
Towards Consistent Hybrid HMM Acoustic Modeling
Apr 28, 2021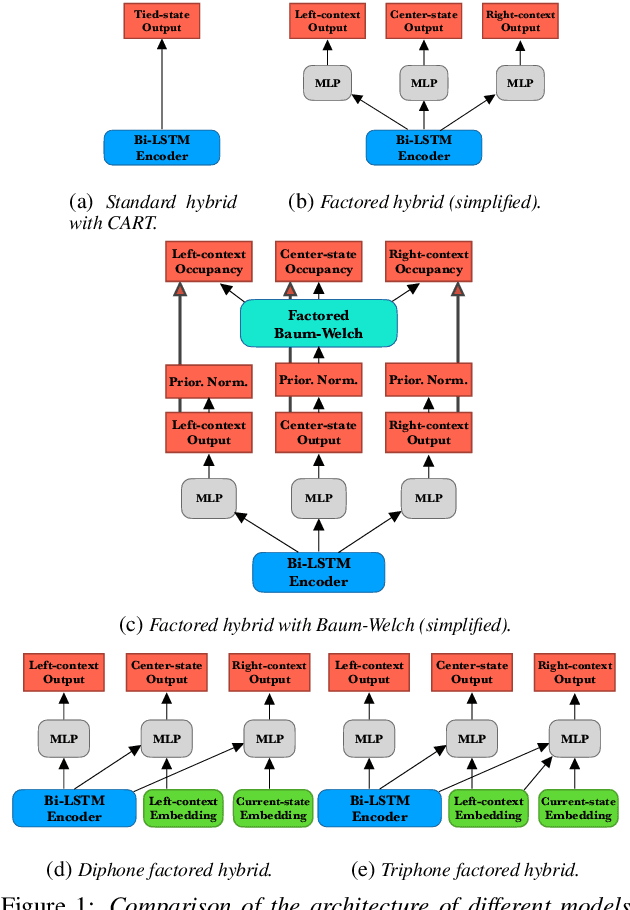
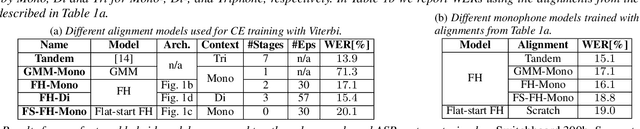
High-performance hybrid automatic speech recognition (ASR) systems are often trained with clustered triphone outputs, and thus require a complex training pipeline to generate the clustering. The same complex pipeline is often utilized in order to generate an alignment for use in frame-wise cross-entropy training. In this work, we propose a flat-start factored hybrid model trained by modeling the full set of triphone states explicitly without relying on clustering methods. This greatly simplifies the training of new models. Furthermore, we study the effect of different alignments used for Viterbi training. Our proposed models achieve competitive performance on the Switchboard task compared to systems using clustered triphones and other flat-start models in the literature.
Context-Dependent Acoustic Modeling without Explicit Phone Clustering
May 15, 2020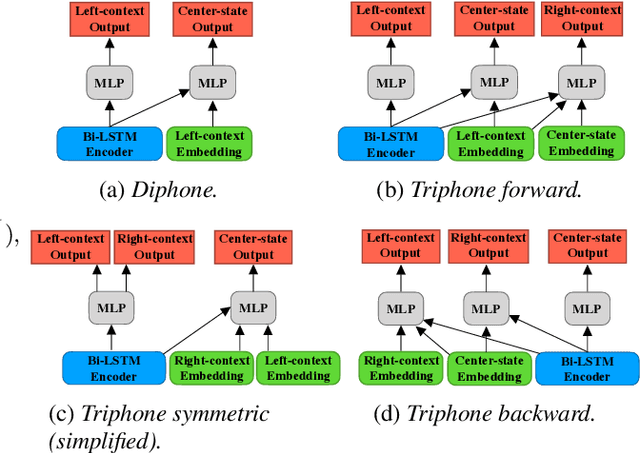
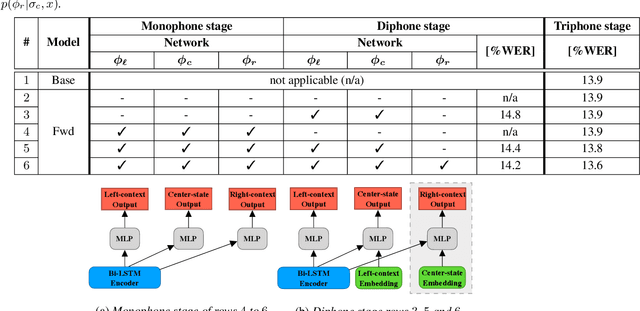
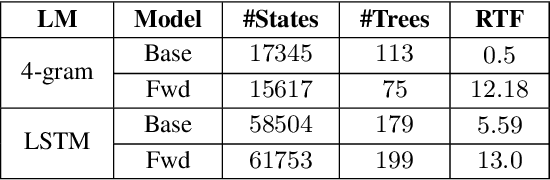
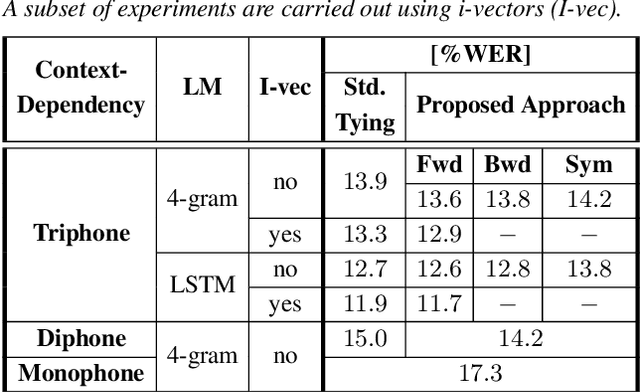
Phoneme-based acoustic modeling of large vocabulary automatic speech recognition takes advantage of phoneme context. The large number of context-dependent (CD) phonemes and their highly varying statistics require tying or smoothing to enable robust training. Usually, Classification and Regression Trees are used for phonetic clustering, which is standard in Hidden Markov Model (HMM)-based systems. However, this solution introduces a secondary training objective and does not allow for end-to-end training. In this work, we address a direct phonetic context modeling for the hybrid Deep Neural Network (DNN)/HMM, that does not build on any phone clustering algorithm for the determination of the HMM state inventory. By performing different decompositions of the joint probability of the center phoneme state and its left and right contexts, we obtain a factorized network consisting of different components, trained jointly. Moreover, the representation of the phonetic context for the network relies on phoneme embeddings. The recognition accuracy of our proposed models on the Switchboard task is comparable and outperforms slightly the hybrid model using the standard state-tying decision trees.
LSTM Language Models for LVCSR in First-Pass Decoding and Lattice-Rescoring
Jul 01, 2019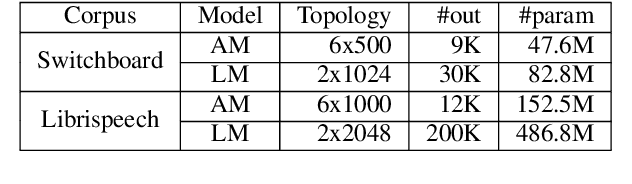



LSTM based language models are an important part of modern LVCSR systems as they significantly improve performance over traditional backoff language models. Incorporating them efficiently into decoding has been notoriously difficult. In this paper we present an approach based on a combination of one-pass decoding and lattice rescoring. We perform decoding with the LSTM-LM in the first pass but recombine hypothesis that share the last two words, afterwards we rescore the resulting lattice. We run our systems on GPGPU equipped machines and are able to produce competitive results on the Hub5'00 and Librispeech evaluation corpora with a runtime better than real-time. In addition we shortly investigate the possibility to carry out the full sum over all state-sequences belonging to a given word-hypothesis during decoding without recombination.
RWTH ASR Systems for LibriSpeech: Hybrid vs Attention - w/o Data Augmentation
May 08, 2019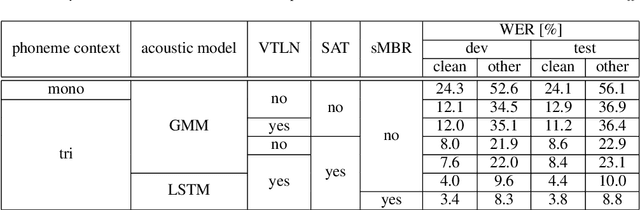
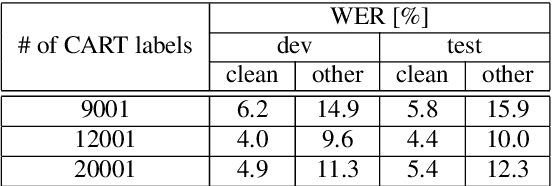
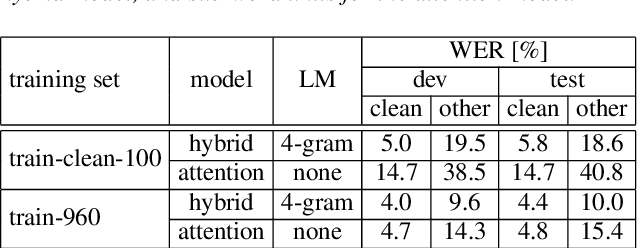
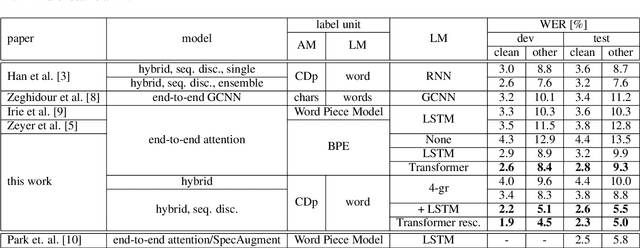
We present state-of-the-art automatic speech recognition (ASR) systems employing a standard hybrid DNN\/HMM architecture compared to an attention-based encoder-decoder design for the LibriSpeech task. Detailed descriptions of the system development, including model design, pretraining schemes, training schedules, and optimization approaches are provided for both system architectures. Both hybrid DNN/HMM and attention-based systems employ bi-directional LSTMs for acoustic modeling/encoding. For language modeling, we employ both LSTM and Transformer based architectures. All our systems are built using RWTHs open-source toolkits RASR and RETURNN. To the best knowledge of the authors, the results obtained when training on the full LibriSpeech training set, are the best published currently, both for the hybrid DNN/HMM and the attention-based systems. Our single hybrid system even outperforms previous results obtained from combining eight single systems. Our comparison shows that on the LibriSpeech 960h task, the hybrid DNN/HMM system outperforms the attention-based system by 15% relative on the clean and 40% relative on the other test sets in terms of word error rate. Moreover, experiments on a reduced 100h-subset of the LibriSpeech training corpus even show a more pronounced margin between the hybrid DNN/HMM and attention-based architectures.