 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effect of Label Topology and Training Criterion on ASR Performance and Alignment Quality
Jul 16, 2024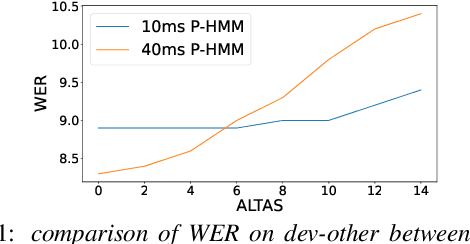
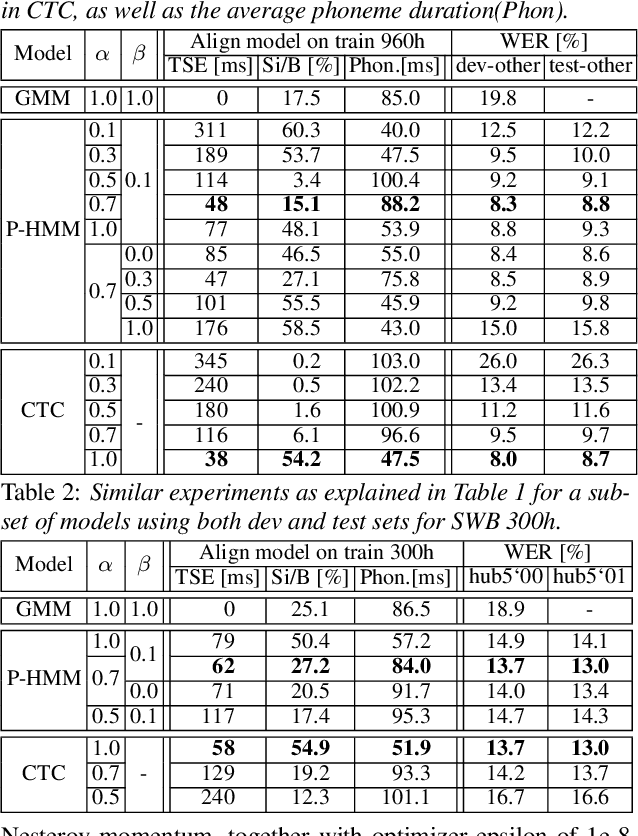
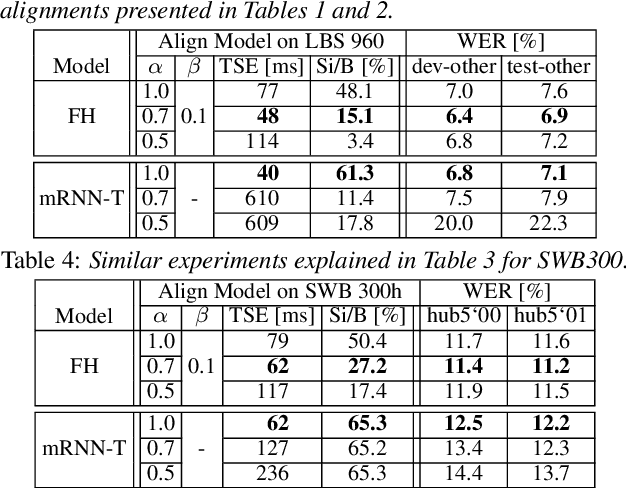
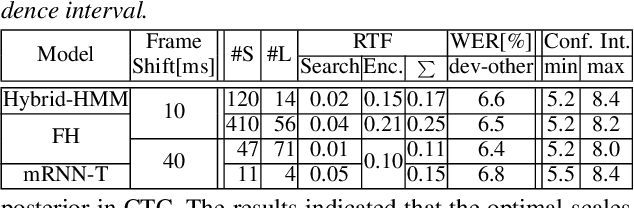
The ongoing research scenario for automatic speech recognition (ASR) envisions a clear division between end-to-end approaches and classic modular systems. Even though a high-level comparison between the two approaches in terms of their requirements and (dis)advantages is commonly addressed, a closer comparison under similar conditions is not readily available in the literature. In this work, we present a comparison focused on the label topology and training criterion. We compare two discriminative alignment models with hidden Markov model (HMM) and connectionist temporal classification topology, and two first-order label context ASR models utilizing factored HMM and strictly monotonic recurrent neural network transducer, respectively. We use different measurements for the evaluation of the alignment quality, and compare word error rate and real time factor of our best systems. Experiments are conducted on the LibriSpeech 960h and Switchboard 300h tasks.
Mixture Encoder Supporting Continuous Speech Separation for Meeting Recognition
Sep 15, 2023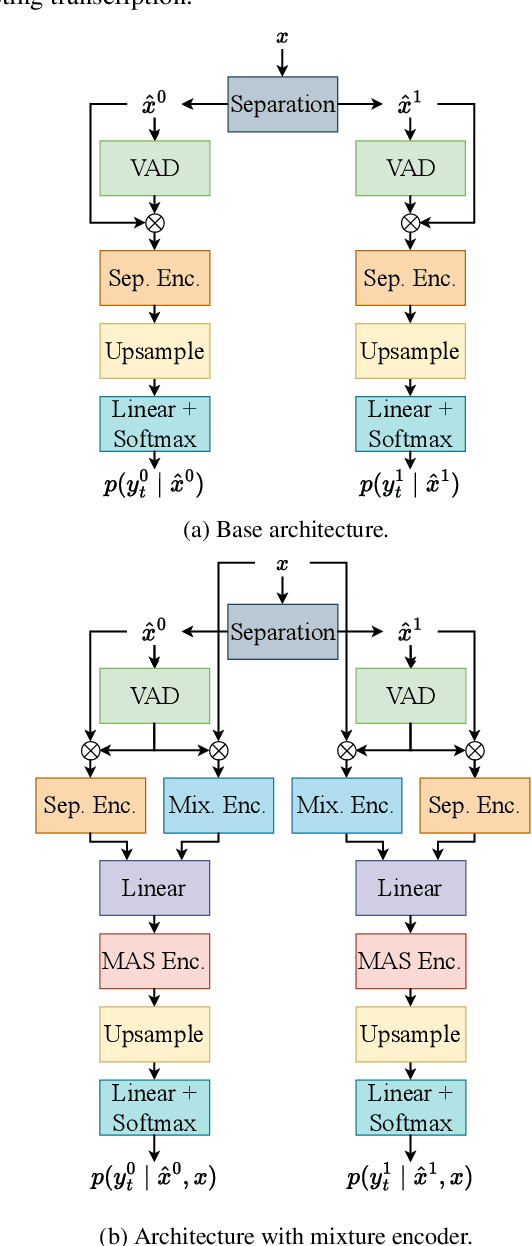



Many real-life applications of automatic speech recognition (ASR) require processing of overlapped speech. A commonmethod involves first separating the speech into overlap-free streams and then performing ASR on the resulting signals. Recently, the inclusion of a mixture encoder in the ASR model has been proposed. This mixture encoder leverages the original overlapped speech to mitigate the effect of artifacts introduced by the speech separation. Previously, however, the method only addressed two-speaker scenarios. In this work, we extend this approach to more natural meeting contexts featuring an arbitrary number of speakers and dynamic overlaps. We evaluate the performance using different speech separators, including the powerful TF-GridNet model. Our experiments show state-of-the-art performance on the LibriCSS dataset and highlight the advantages of the mixture encoder. Furthermore, they demonstrate the strong separation of TF-GridNet which largely closes the gap between previous methods and oracle separation.
Mixture Encoder for Joint Speech Separation and Recognition
Jun 21, 2023Multi-speaker automatic speech recognition (ASR) is crucial for many real-world applications, but it requires dedicated modeling techniques. Existing approaches can be divided into modular and end-to-end methods. Modular approaches separate speakers and recognize each of them with a single-speaker ASR system. End-to-end models process overlapped speech directly in a single, powerful neural network. This work proposes a middle-ground approach that leverages explicit speech separation similarly to the modular approach but also incorporates mixture speech information directly into the ASR module in order to mitigate the propagation of errors made by the speech separator. We also explore a way to exchange cross-speaker context information through a layer that combines information of the individual speakers. Our system is optimized through separate and joint training stages and achieves a relative improvement of 7% in word error rate over a purely modular setup on the SMS-WSJ task.
RASR2: The RWTH ASR Toolkit for Generic Sequence-to-sequence Speech Recognition
May 28, 2023Modern public ASR tools usually provide rich support for training various sequence-to-sequence (S2S) models, but rather simple support for decoding open-vocabulary scenarios only. For closed-vocabulary scenarios, public tools supporting lexical-constrained decoding are usually only for classical ASR, or do not support all S2S models. To eliminate this restriction on research possibilities such as modeling unit choice, we present RASR2 in this work, a research-oriented generic S2S decoder implemented in C++. It offers a strong flexibility/compatibility for various S2S models, language models, label units/topologies and neural network architectures. It provides efficient decoding for both open- and closed-vocabulary scenarios based on a generalized search framework with rich support for different search modes and settings. We evaluate RASR2 with a wide range of experiments on both switchboard and Librispeech corpora. Our source code is public online.
HMM vs. CTC for Automatic Speech Recognition: Comparison Based on Full-Sum Training from Scratch
Oct 18, 2022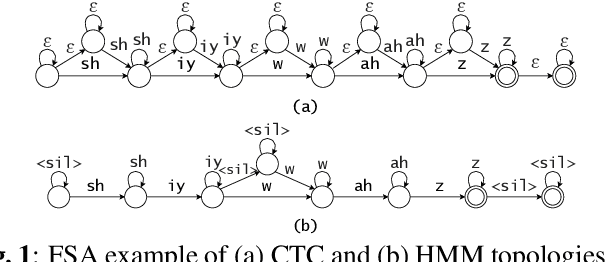
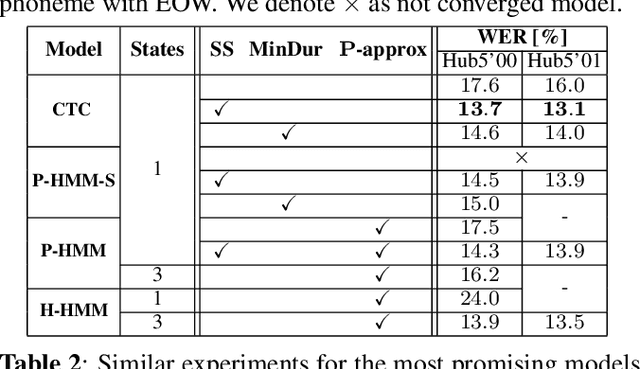
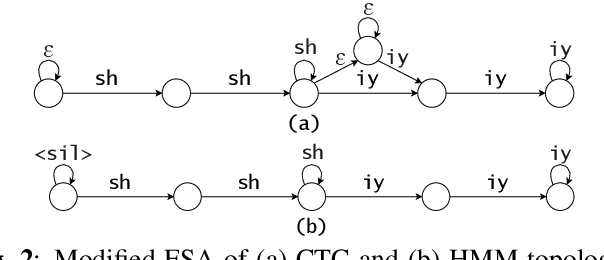
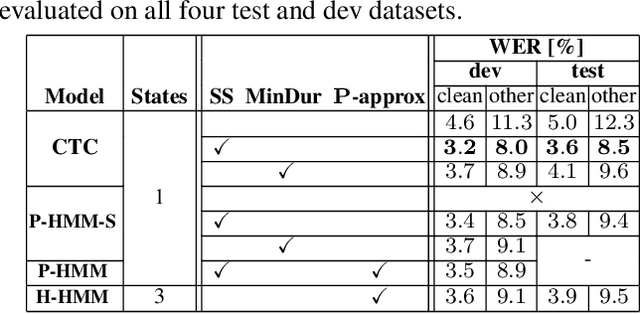
In this work, we compare from-scratch sequence-level cross-entropy (full-sum) training of Hidden Markov Model (HMM) and Connectionist Temporal Classification (CTC) topologies for automatic speech recognition (ASR). Besides accuracy, we further analyze their capability for generating high-quality time alignment between the speech signal and the transcription, which can be crucial for many subsequent applications. Moreover, we propose several methods to improve convergence of from-scratch full-sum training by addressing the alignment modeling issue. Systematic comparison is conducted on both Switchboard and LibriSpeech corpora across CTC, posterior HMM with and w/o transition probabilities, and standard hybrid HMM. We also provide a detailed analysis of both Viterbi forced-alignment and Baum-Welch full-sum occupation probabilities.
Phoneme Based Neural Transducer for Large Vocabulary Speech Recognition
Nov 09, 2020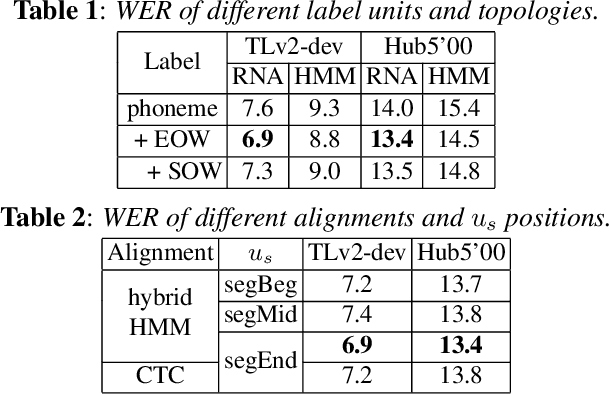
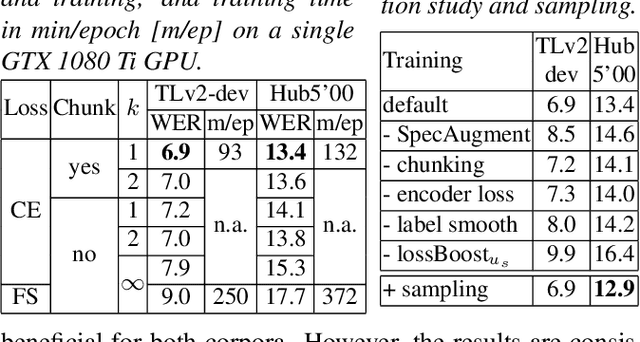

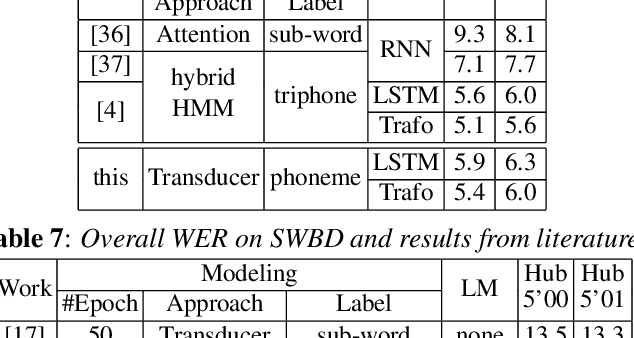
To join the advantages of classical and end-to-end approaches for speech recognition, we present a simple, novel and competitive approach for phoneme-based neural transducer modeling. Different alignment label topologies are compared and word-end-based phoneme label augmentation is proposed to improve performance. Utilizing the local dependency of phonemes, we adopt a simplified neural network structure and a straightforward integration with the external word-level language model to preserve the consistency of seq-to-seq modeling. We also present a simple, stable and efficient training procedure using frame-wise cross-entropy loss. A phonetic context size of one is shown to be sufficient for the best performance. A simplified scheduled sampling approach is applied for further improvement. We also briefly compare different decoding approaches. The overall performance of our best model is comparable to state-of-the-art results for the TED-LIUM Release 2 and Switchboard corpora.