 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMM vs. CTC for Automatic Speech Recognition: Comparison Based on Full-Sum Training from Scratch
Paper and Code
Oct 18, 2022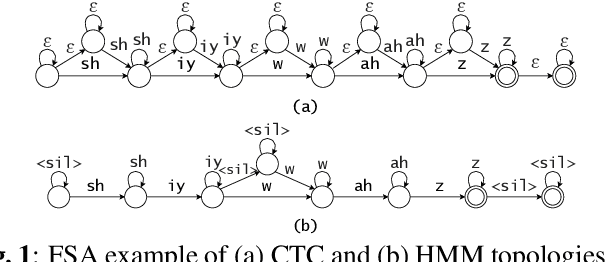
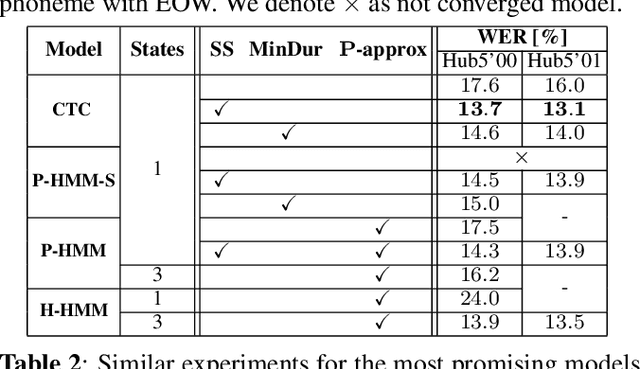
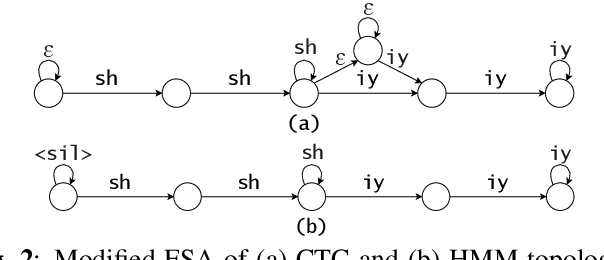
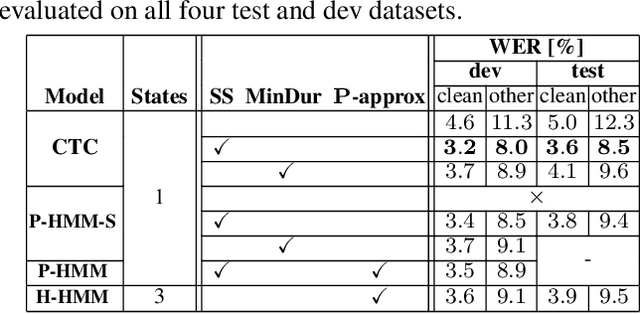
In this work, we compare from-scratch sequence-level cross-entropy (full-sum) training of Hidden Markov Model (HMM) and Connectionist Temporal Classification (CTC) topologies for automatic speech recognition (ASR). Besides accuracy, we further analyze their capability for generating high-quality time alignment between the speech signal and the transcription, which can be crucial for many subsequent applications. Moreover, we propose several methods to improve convergence of from-scratch full-sum training by addressing the alignment modeling issue. Systematic comparison is conducted on both Switchboard and LibriSpeech corpora across CTC, posterior HMM with and w/o transition probabilities, and standard hybrid HMM. We also provide a detailed analysis of both Viterbi forced-alignment and Baum-Welch full-sum occupation probabilities.