 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight Label Context in End-to-End Training of Time-Synchronous ASR Models
Jan 08, 2025



Current time-synchronous sequence-to-sequence automatic speech recognition (ASR) models are trained by using sequence level cross-entropy that sums over all alignments. Due to the discriminative formulation, incorporating the right label context into the training criterion's gradient causes normalization problems and is not mathematically well-defined. The classic hybrid neural network hidden Markov model (NN-HMM) with its inherent generative formulation enables conditioning on the right label context. However, due to the HMM state-tying the identity of the right label context is never modeled explicitly. In this work, we propose a factored loss with auxiliary left and right label contexts that sums over all alignments. We show that the inclusion of the right label context is particularly beneficial when training data resources are limited. Moreover, we also show that it is possible to build a factored hybrid HMM system by relying exclusively on the full-sum criterion. Experiments were conducted on Switchboard 300h and LibriSpeech 960h.
Investigating the Effect of Label Topology and Training Criterion on ASR Performance and Alignment Quality
Jul 16, 2024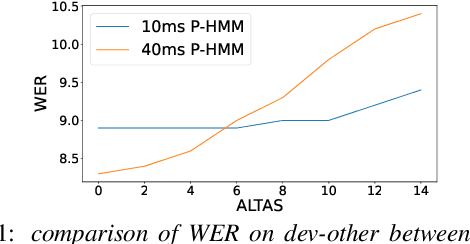
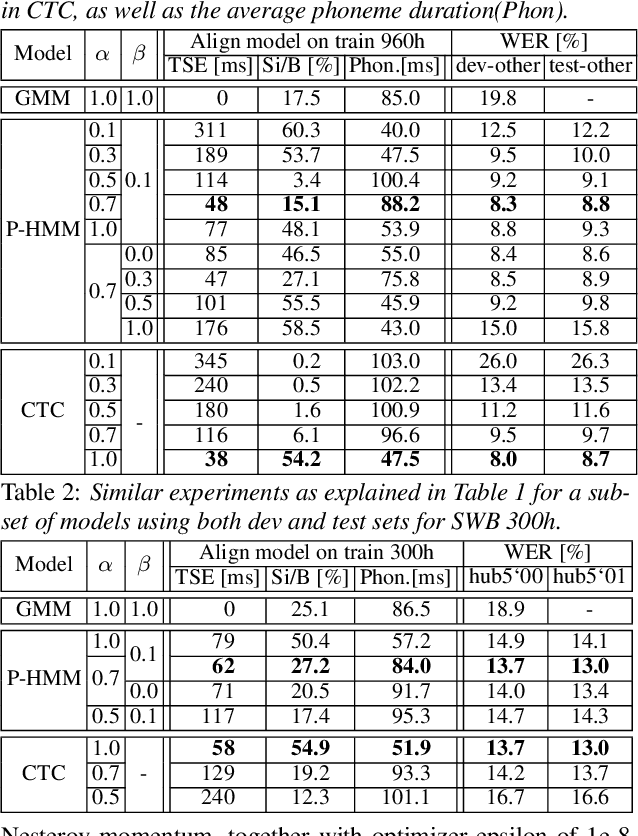
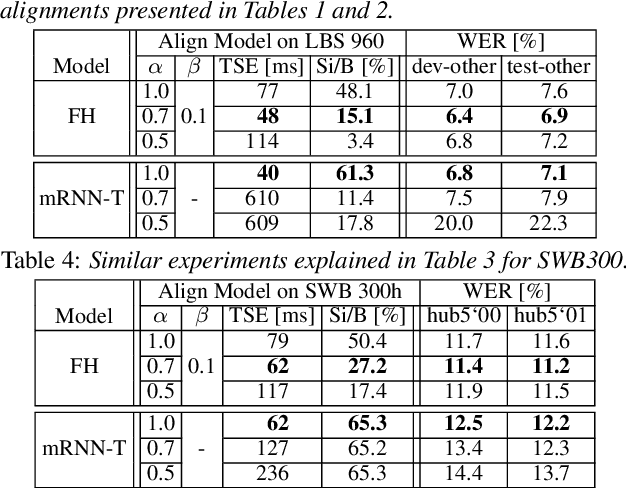
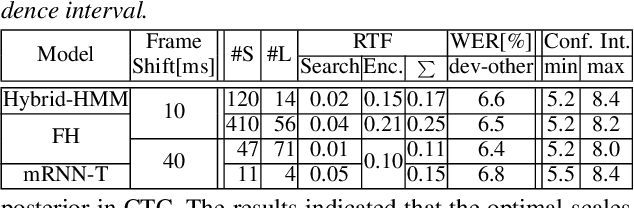
The ongoing research scenario for automatic speech recognition (ASR) envisions a clear division between end-to-end approaches and classic modular systems. Even though a high-level comparison between the two approaches in terms of their requirements and (dis)advantages is commonly addressed, a closer comparison under similar conditions is not readily available in the literature. In this work, we present a comparison focused on the label topology and training criterion. We compare two discriminative alignment models with hidden Markov model (HMM) and connectionist temporal classification topology, and two first-order label context ASR models utilizing factored HMM and strictly monotonic recurrent neural network transducer, respectively. We use different measurements for the evaluation of the alignment quality, and compare word error rate and real time factor of our best systems. Experiments are conducted on the LibriSpeech 960h and Switchboard 300h tasks.
End-to-End Training of a Neural HMM with Label and Transition Probabilities
Oct 09, 2023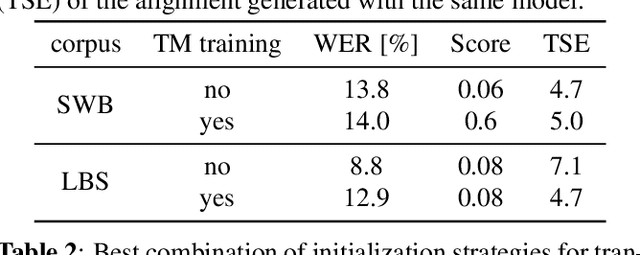
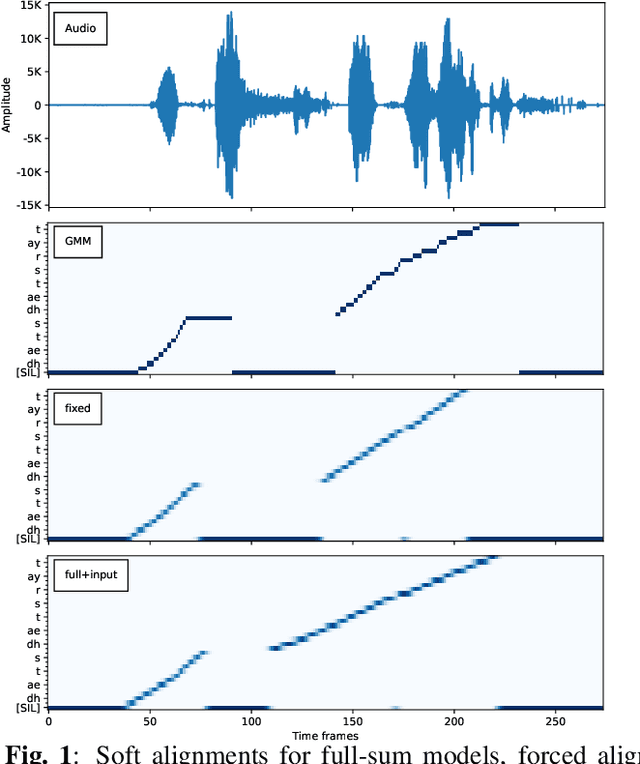

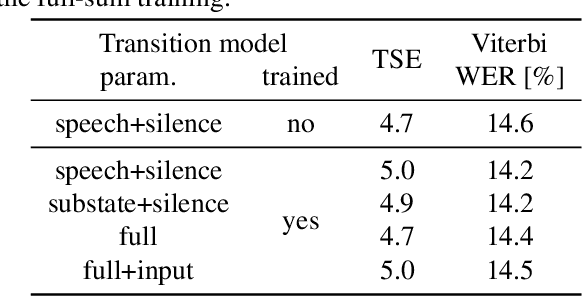
We investigate a novel modeling approach for end-to-end neural network training using hidden Markov models (HMM) where the transition probabilities between hidden states are modeled and learned explicitly. Most contemporary sequence-to-sequence models allow for from-scratch training by summing over all possible label segmentations in a given topology. In our approach there are explicit, learnable probabilities for transitions between segments as opposed to a blank label that implicitly encodes duration statistics. We implement a GPU-based forward-backward algorithm that enables the simultaneous training of label and transition probabilities. We investigate recognition results and additionally Viterbi alignments of our models. We find that while the transition model training does not improve recognition performance, it has a positive impact on the alignment quality. The generated alignments are shown to be viable targets in state-of-the-art Viterbi trainings.
Competitive and Resource Efficient Factored Hybrid HMM Systems are Simpler Than You Think
Jun 15, 2023Building competitive hybrid hidden Markov model~(HMM) systems for automatic speech recognition~(ASR) requires a complex multi-stage pipeline consisting of several training criteria. The recent sequence-to-sequence models offer the advantage of having simpler pipelines that can start from-scratch. We propose a purely neural based single-stage from-scratch pipeline for a context-dependent hybrid HMM that offers similar simplicity. We use an alignment from a full-sum trained zero-order posterior HMM with a BLSTM encoder. We show that with this alignment we can build a Conformer factored hybrid that performs even better than both a state-of-the-art classic hybrid and a factored hybrid trained with alignments taken from more complex Gaussian mixture based systems. Our finding is confirmed on Switchboard 300h and LibriSpeech 960h tasks with comparable results to other approaches in the literature, and by additionally relying on a responsible choice of available computational resources.
HMM vs. CTC for Automatic Speech Recognition: Comparison Based on Full-Sum Training from Scratch
Oct 18, 2022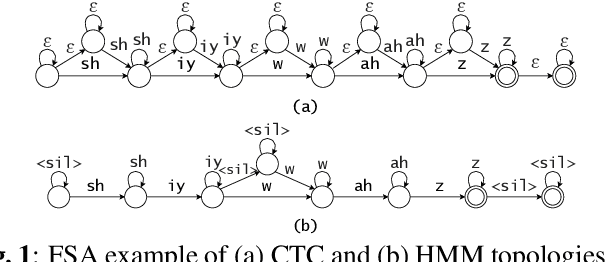
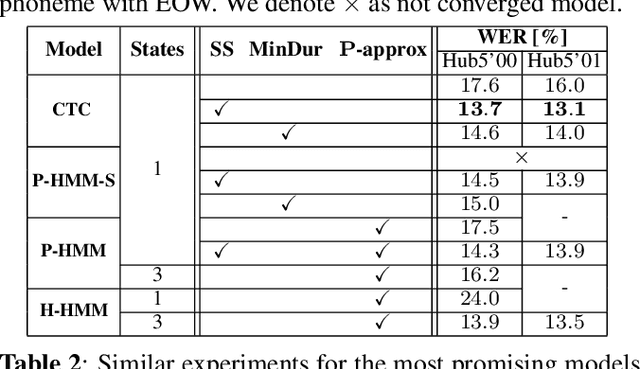
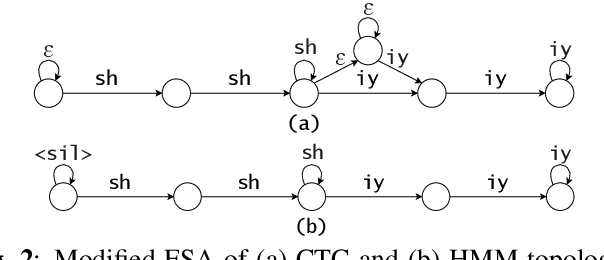
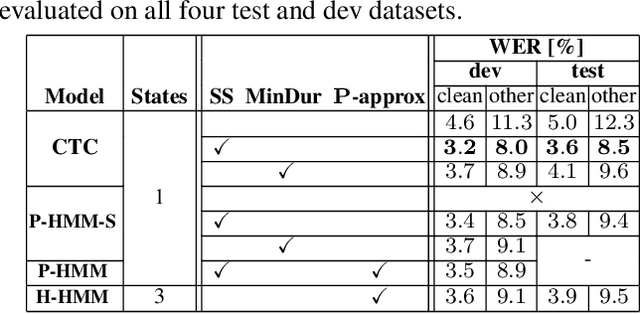
In this work, we compare from-scratch sequence-level cross-entropy (full-sum) training of Hidden Markov Model (HMM) and Connectionist Temporal Classification (CTC) topologies for automatic speech recognition (ASR). Besides accuracy, we further analyze their capability for generating high-quality time alignment between the speech signal and the transcription, which can be crucial for many subsequent applications. Moreover, we propose several methods to improve convergence of from-scratch full-sum training by addressing the alignment modeling issue. Systematic comparison is conducted on both Switchboard and LibriSpeech corpora across CTC, posterior HMM with and w/o transition probabilities, and standard hybrid HMM. We also provide a detailed analysis of both Viterbi forced-alignment and Baum-Welch full-sum occupation probabilities.
Improving Factored Hybrid HMM Acoustic Modeling without State Tying
Jan 24, 2022
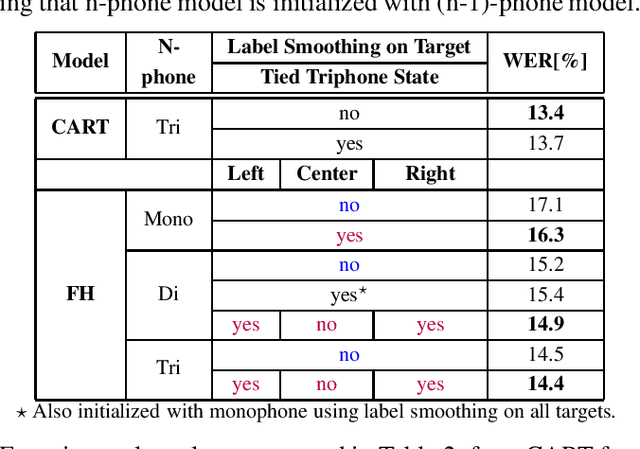
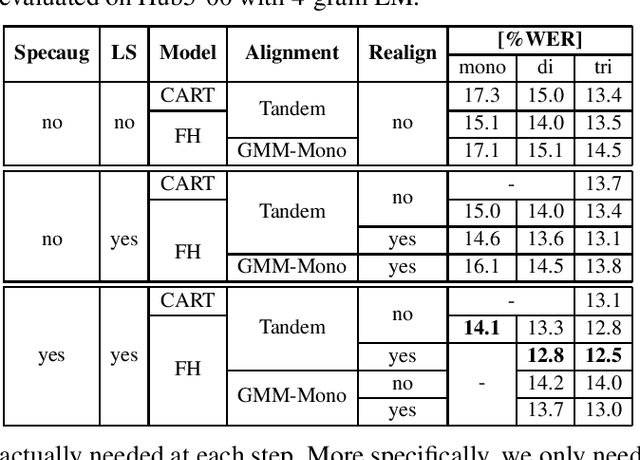
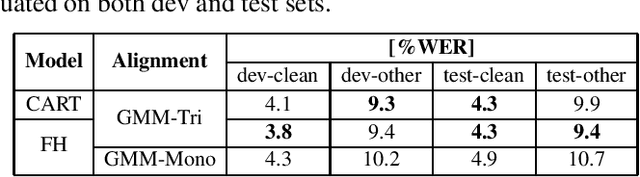
In this work, we show that a factored hybrid hidden Markov model (FH-HMM) which is defined without any phonetic state-tying outperforms a state-of-the-art hybrid HMM. The factored hybrid HMM provides a link to transducer models in the way it models phonetic (label) context while preserving the strict separation of acoustic and language model of the hybrid HMM approach. Furthermore, we show that the factored hybrid model can be trained from scratch without using phonetic state-tying in any of the training steps. Our modeling approach enables triphone context while avoiding phonetic state-tying by a decomposition into locally normalized factored posteriors for monophones/HMM states in phoneme context. Experimental results are provided for Switchboard 300h and LibriSpeech. On the former task we also show that by avoiding the phonetic state-tying step, the factored hybrid can take better advantage of regularization techniques during training, compared to the standard hybrid HMM with phonetic state-tying based on classification and regression trees (CART).
Towards Consistent Hybrid HMM Acoustic Modeling
Apr 28, 2021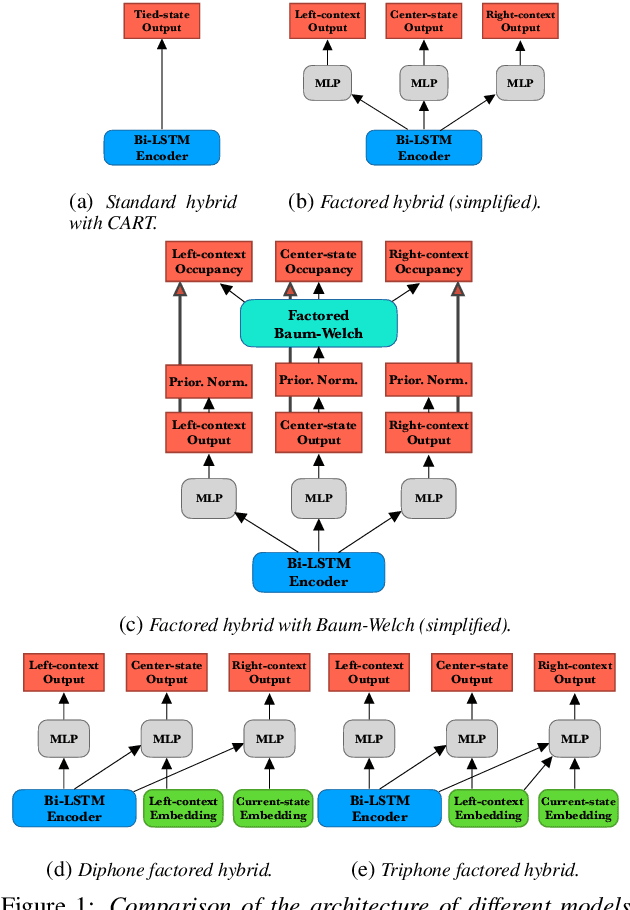
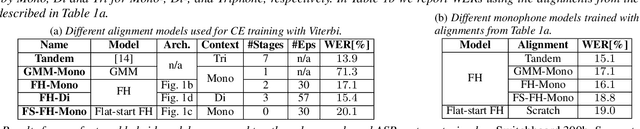
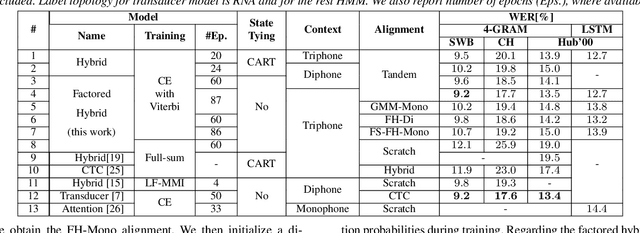
High-performance hybrid automatic speech recognition (ASR) systems are often trained with clustered triphone outputs, and thus require a complex training pipeline to generate the clustering. The same complex pipeline is often utilized in order to generate an alignment for use in frame-wise cross-entropy training. In this work, we propose a flat-start factored hybrid model trained by modeling the full set of triphone states explicitly without relying on clustering methods. This greatly simplifies the training of new models. Furthermore, we study the effect of different alignments used for Viterbi training. Our proposed models achieve competitive performance on the Switchboard task compared to systems using clustered triphones and other flat-start models in the literature.
Improved Robustness to Disfluencies in RNN-Transducer Based Speech Recognition
Dec 11, 2020



Automatic Speech Recognition (ASR) based on Recurrent Neural Network Transducers (RNN-T) is gaining interest in the speech community. We investigate data selection and preparation choices aiming for improved robustness of RNN-T ASR to speech disfluencies with a focus on partial words. For evaluation we use clean data, data with disfluencies and a separate dataset with speech affected by stuttering. We show that after including a small amount of data with disfluencies in the training set the recognition accuracy on the tests with disfluencies and stuttering improves. Increasing the amount of training data with disfluencies gives additional gains without degradation on the clean data. We also show that replacing partial words with a dedicated token helps to get even better accuracy on utterances with disfluencies and stutter. The evaluation of our best model shows 22.5% and 16.4% relative WER reduction on those two evaluation sets.
Context-Dependent Acoustic Modeling without Explicit Phone Clustering
May 15, 2020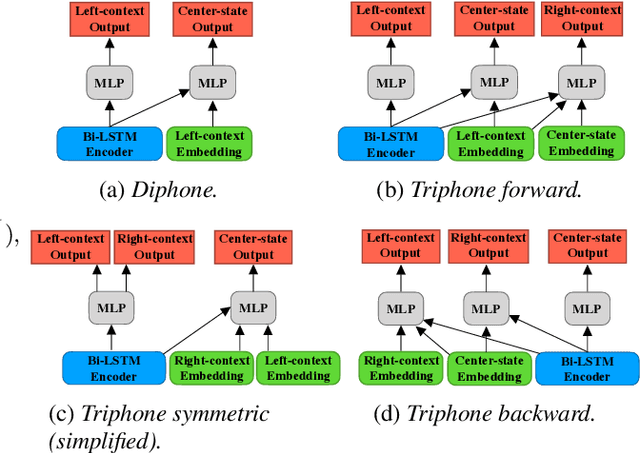
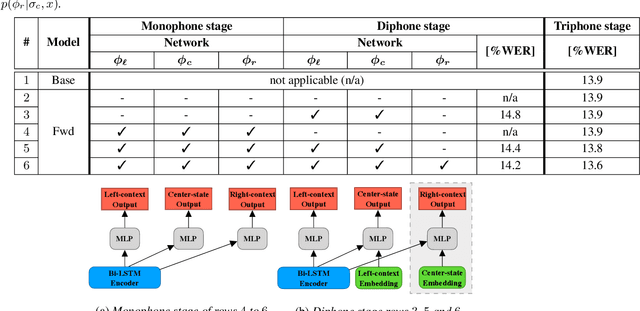
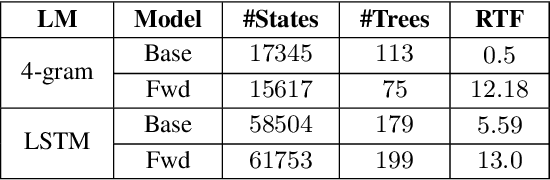
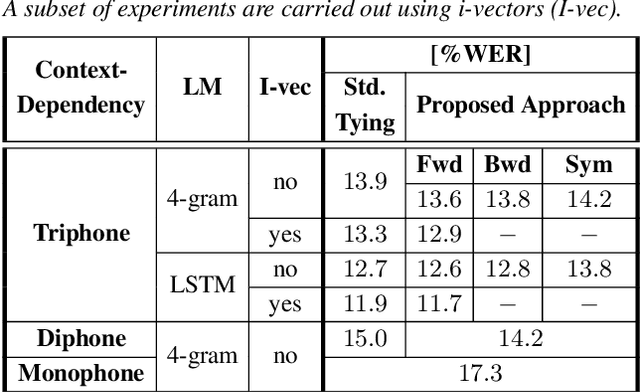
Phoneme-based acoustic modeling of large vocabulary automatic speech recognition takes advantage of phoneme context. The large number of context-dependent (CD) phonemes and their highly varying statistics require tying or smoothing to enable robust training. Usually, Classification and Regression Trees are used for phonetic clustering, which is standard in Hidden Markov Model (HMM)-based systems. However, this solution introduces a secondary training objective and does not allow for end-to-end training. In this work, we address a direct phonetic context modeling for the hybrid Deep Neural Network (DNN)/HMM, that does not build on any phone clustering algorithm for the determination of the HMM state inventory. By performing different decompositions of the joint probability of the center phoneme state and its left and right contexts, we obtain a factorized network consisting of different components, trained jointly. Moreover, the representation of the phonetic context for the network relies on phoneme embeddings. The recognition accuracy of our proposed models on the Switchboard task is comparable and outperforms slightly the hybrid model using the standard state-tying decision trees.
Extended pipeline for content-based feature engineering in music genre recognition
May 12, 2018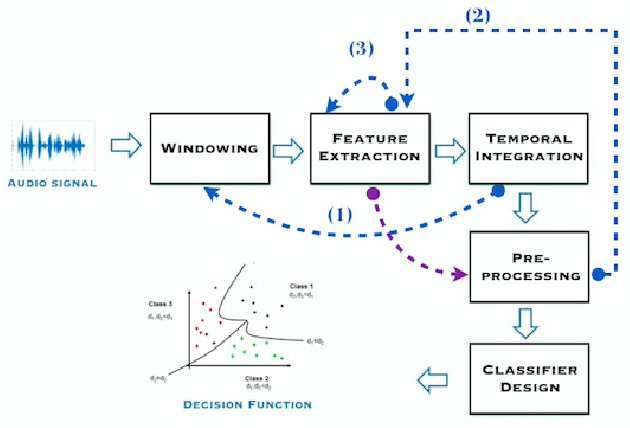
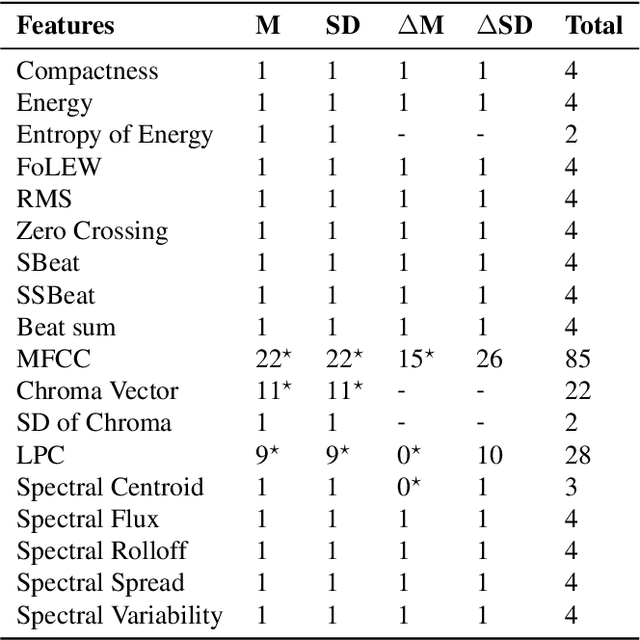
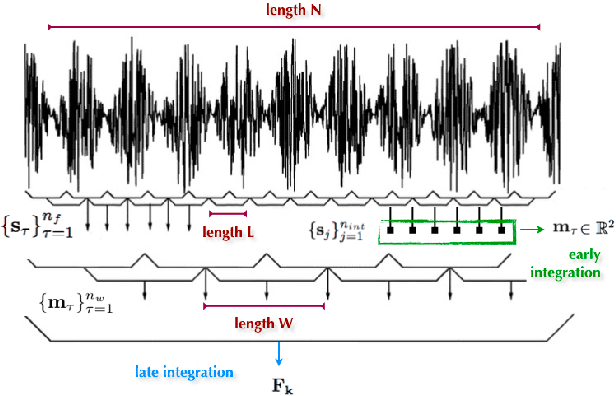

We present a feature engineering pipeline for the construction of musical signal characteristics, to be used for the design of a supervised model for musical genre identification. The key idea is to extend the traditional two-step process of extraction and classification with additive stand-alone phases which are no longer organized in a waterfall scheme. The whole system is realized by traversing backtrack arrows and cycles between various stages. In order to give a compact and effective representation of the features, the standard early temporal integration is combined with other selection and extraction phases: on the one hand, the selection of the most meaningful characteristics based on information gain, and on the other hand, the inclusion of the nonlinear correlation between this subset of features, determined by an autoencoder. The results of the experiments conducted on GTZAN dataset reveal a noticeable contribution of this methodology towards the model's performance in classification task.