 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and reducing the synthetic-to-real transfer gap in Music Information Retrieval: the task of automatic drum transcription
Jul 29, 2024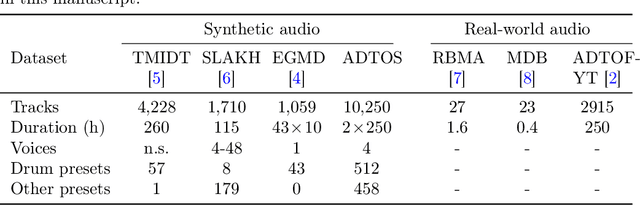
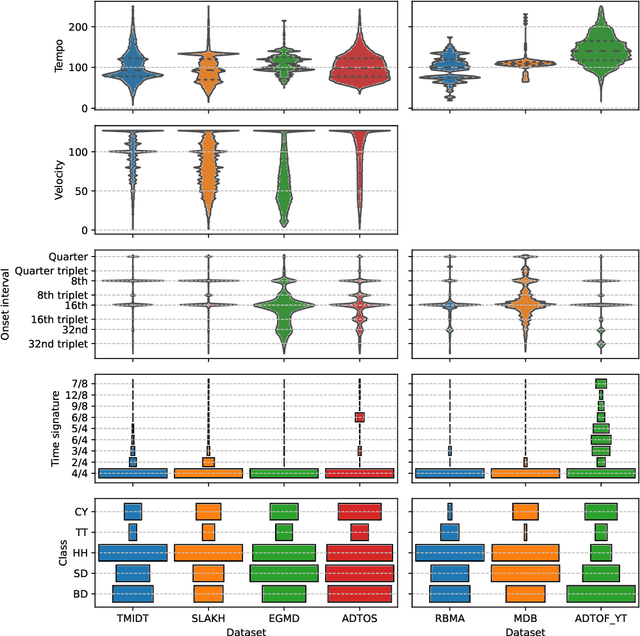
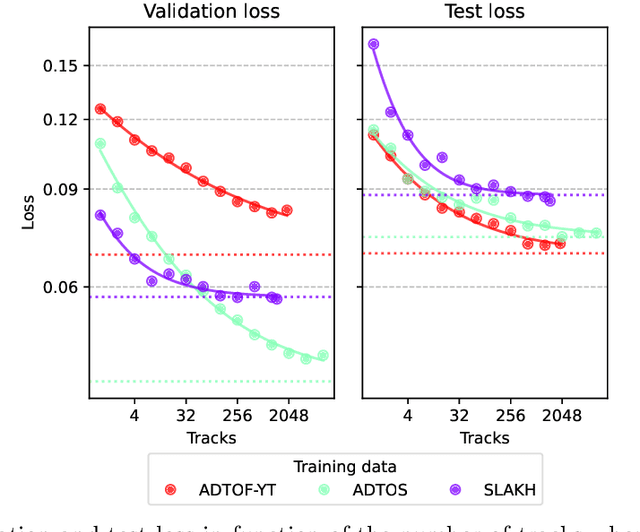
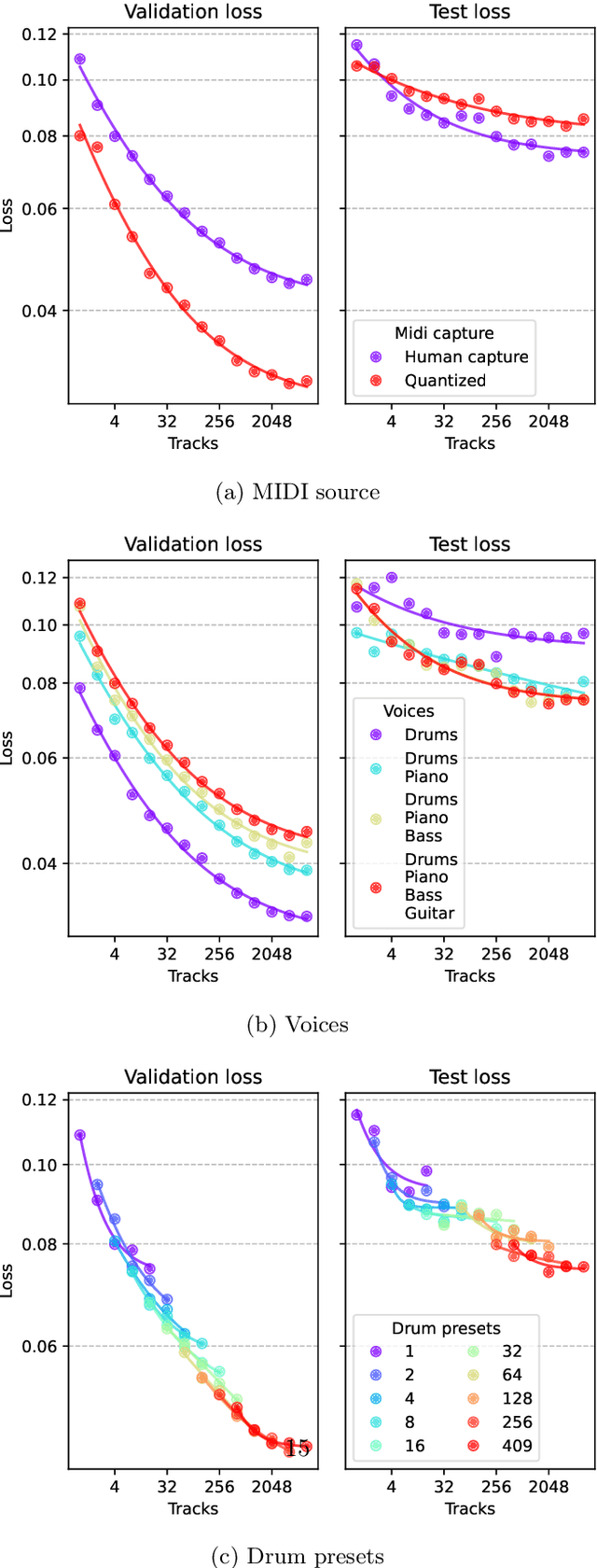
Automatic drum transcription is a critical tool in Music Information Retrieval for extracting and analyzing the rhythm of a music track, but it is limited by the size of the datasets available for training. A popular method used to increase the amount of data is by generating them synthetically from music scores rendered with virtual instruments. This method can produce a virtually infinite quantity of tracks, but empirical evidence shows that models trained on previously created synthetic datasets do not transfer well to real tracks. In this work, besides increasing the amount of data, we identify and evaluate three more strategies that practitioners can use to improve the realism of the generated data and, thus, narrow the synthetic-to-real transfer gap. To explore their efficacy, we used them to build a new synthetic dataset and then we measured how the performance of a model scales and, specifically, at what value it will stagnate when increasing the number of training tracks for different datasets. By doing this, we were able to prove that the aforementioned strategies contribute to make our dataset the one with the most realistic data distribution and the lowest synthetic-to-real transfer gap among the synthetic datasets we evaluated. We conclude by highlighting the limits of training with infinite data in drum transcription and we show how they can be overcome.
Ranking with Ties based on Noisy Performance Data
May 28, 2024We consider the problem of ranking a set of objects based on their performance when the measurement of said performance is subject to noise. In this scenario, the performance is measured repeatedly, resulting in a range of measurements for each object. If the ranges of two objects do not overlap, then we consider one object as 'better' than the other, and we expect it to receive a higher rank; if, however, the ranges overlap, then the objects are incomparable, and we wish them to be assigned the same rank. Unfortunately, the incomparability relation of ranges is in general not transitive; as a consequence, in general the two requirements cannot be satisfied simultaneously, i.e., it is not possible to guarantee both distinct ranks for objects with separated ranges, and same rank for objects with overlapping ranges. This conflict leads to more than one reasonable way to rank a set of objects. In this paper, we explore the ambiguities that arise when ranking with ties, and define a set of reasonable rankings, which we call partial rankings. We develop and analyse three different methodologies to compute a partial ranking. Finally, we show how performance differences among objects can be investigated with the help of partial ranking.
Benchmarking the Linear Algebra Awareness of TensorFlow and PyTorch
Feb 20, 2022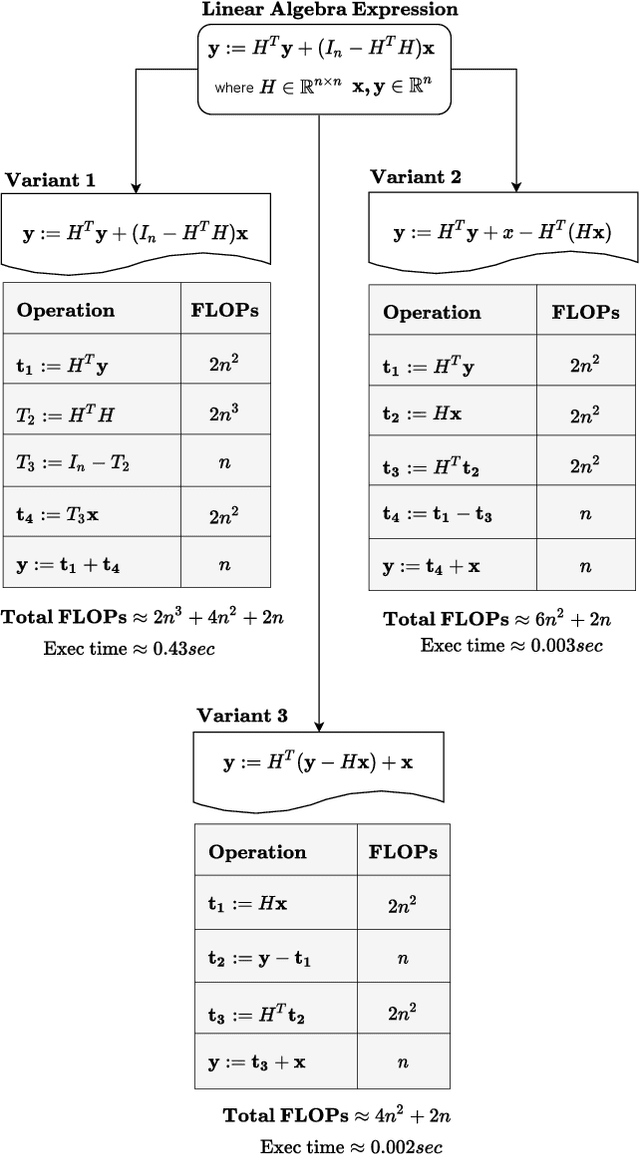
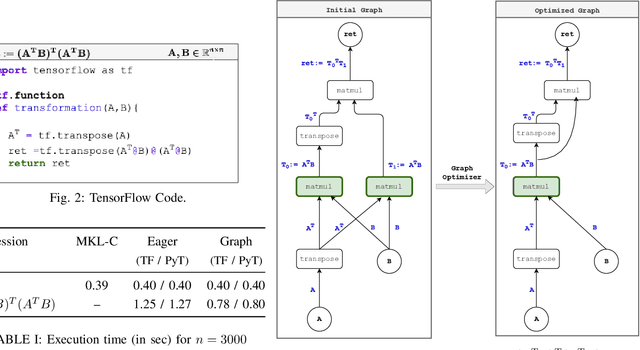
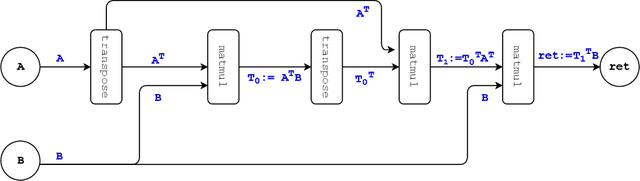
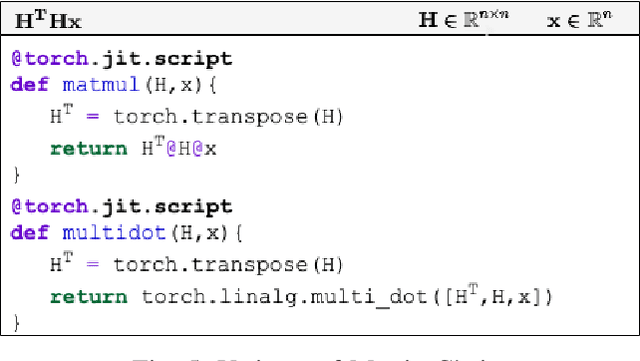
Linear algebra operations, which are ubiquitous in machine learning, form major performance bottlenecks. The High-Performance Computing community invests significant effort in the development of architecture-specific optimized kernels, such as those provided by the BLAS and LAPACK libraries, to speed up linear algebra operations. However, end users are progressively less likely to go through the error prone and time-consuming process of directly using said kernels; instead, frameworks such as TensorFlow (TF) and PyTorch (PyT), which facilitate the development of machine learning applications, are becoming more and more popular. Although such frameworks link to BLAS and LAPACK, it is not clear whether or not they make use of linear algebra knowledge to speed up computations. For this reason, in this paper we develop benchmarks to investigate the linear algebra optimization capabilities of TF and PyT. Our analyses reveal that a number of linear algebra optimizations are still missing; for instance, reducing the number of scalar operations by applying the distributive law, and automatically identifying the optimal parenthesization of a matrix chain. In this work, we focus on linear algebra computations in TF and PyT; we both expose opportunities for performance enhancement to the benefit of the developers of the frameworks and provide end users with guidelines on how to achieve performance gains.
ADTOF: A large dataset of non-synthetic music for automatic drum transcription
Nov 23, 2021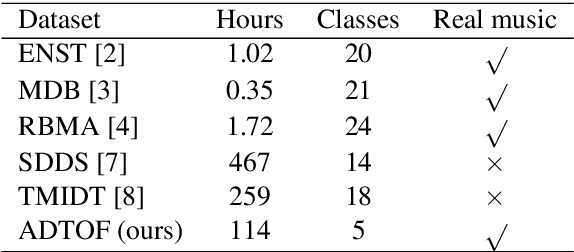

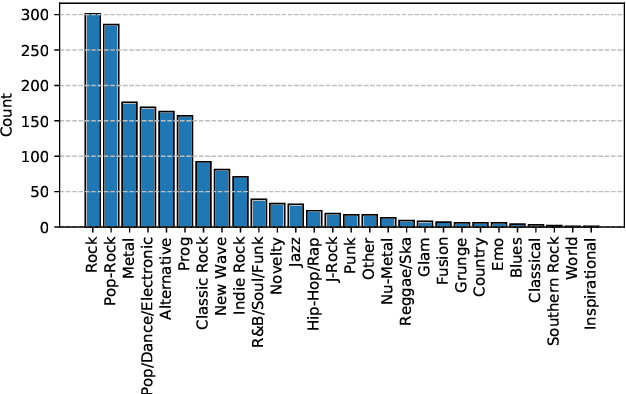
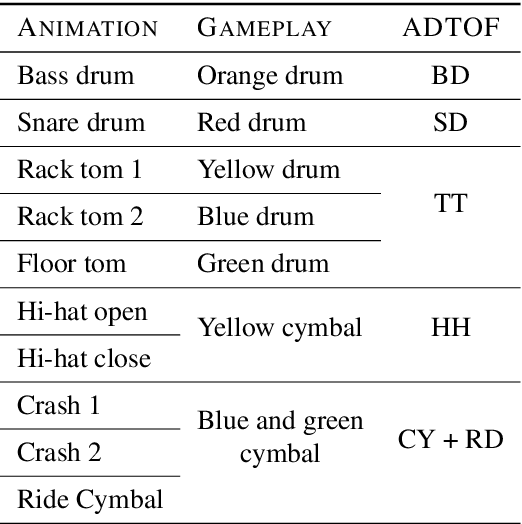
The state-of-the-art methods for drum transcription in the presence of melodic instruments (DTM) are machine learning models trained in a supervised manner, which means that they rely on labeled datasets. The problem is that the available public datasets are limited either in size or in realism, and are thus suboptimal for training purposes. Indeed, the best results are currently obtained via a rather convoluted multi-step training process that involves both real and synthetic datasets. To address this issue, starting from the observation that the communities of rhythm games players provide a large amount of annotated data, we curated a new dataset of crowdsourced drum transcriptions. This dataset contains real-world music, is manually annotated, and is about two orders of magnitude larger than any other non-synthetic dataset, making it a prime candidate for training purposes. However, due to crowdsourcing, the initial annotations contain mistakes. We discuss how the quality of the dataset can be improved by automatically correcting different types of mistakes. When used to train a popular DTM model, the dataset yields a performance that matches that of the state-of-the-art for DTM, thus demonstrating the quality of the annotations.
Concurrent Alternating Least Squares for multiple simultaneous Canonical Polyadic Decompositions
Oct 09, 2020
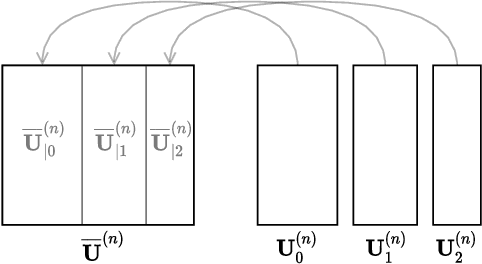
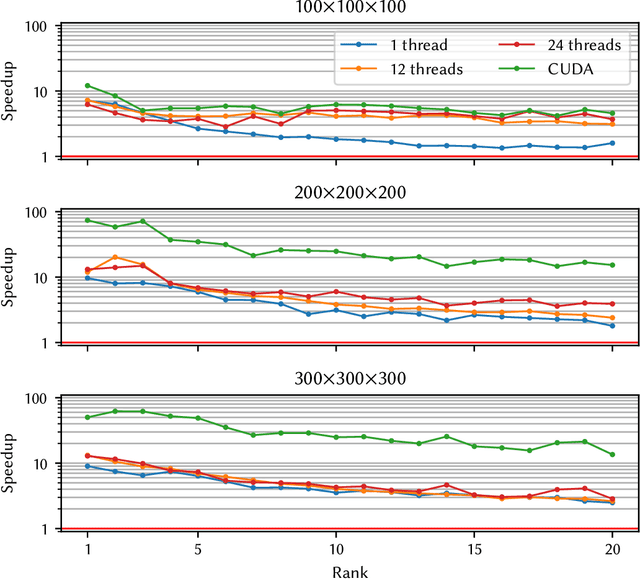
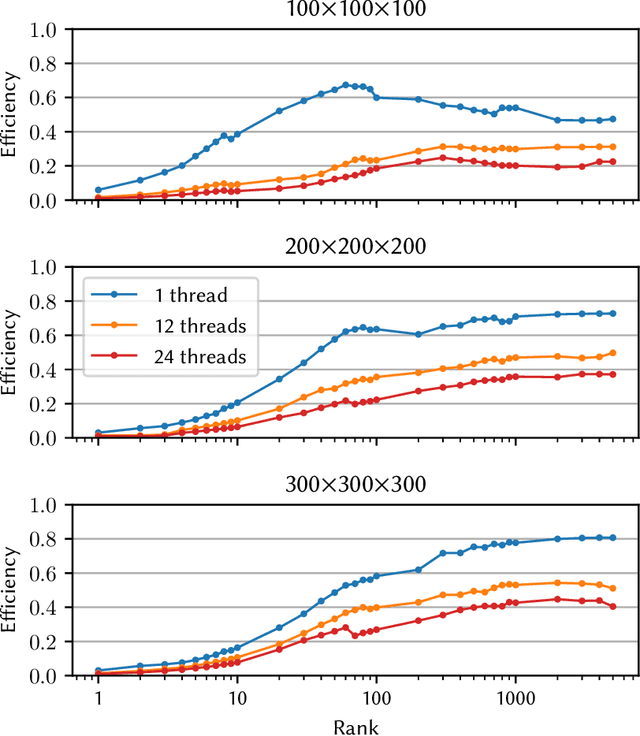
Tensor decompositions, such as CANDECOMP/PARAFAC (CP), are widely used in a variety of applications, such as chemometrics, signal processing, and machine learning. A broadly used method for computing such decompositions relies on the Alternating Least Squares (ALS) algorithm. When the number of components is small, regardless of its implementation, ALS exhibits low arithmetic intensity, which severely hinders its performance and makes GPU offloading ineffective. We observe that, in practice, experts often have to compute multiple decompositions of the same tensor, each with a small number of components (typically fewer than 20), to ultimately find the best ones to use for the application at hand. In this paper, we illustrate how multiple decompositions of the same tensor can be fused together at the algorithmic level to increase the arithmetic intensity. Therefore, it becomes possible to make efficient use of GPUs for further speedups; at the same time the technique is compatible with many enhancements typically used in ALS, such as line search, extrapolation, and non-negativity constraints. We introduce the Concurrent ALS algorithm and library, which offers an interface to Matlab, and a mechanism to effectively deal with the issue that decompositions complete at different times. Experimental results on artificial and real datasets demonstrate a shorter time to completion due to increased arithmetic intensity.
Extended pipeline for content-based feature engineering in music genre recognition
May 12, 2018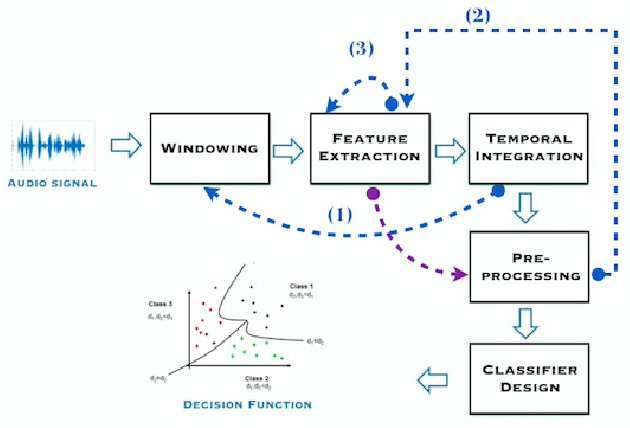
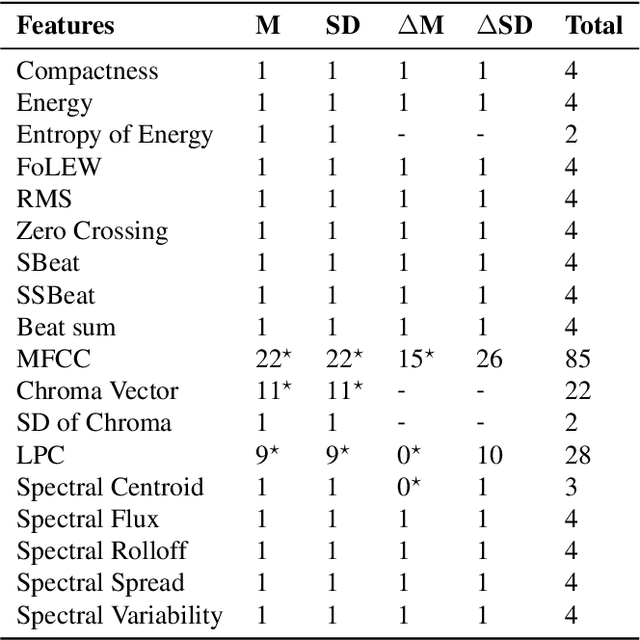
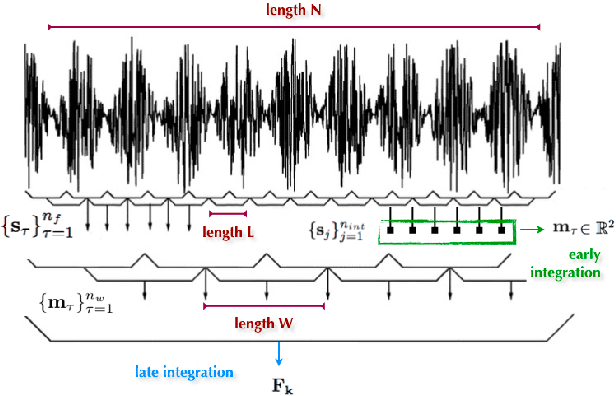

We present a feature engineering pipeline for the construction of musical signal characteristics, to be used for the design of a supervised model for musical genre identification. The key idea is to extend the traditional two-step process of extraction and classification with additive stand-alone phases which are no longer organized in a waterfall scheme. The whole system is realized by traversing backtrack arrows and cycles between various stages. In order to give a compact and effective representation of the features, the standard early temporal integration is combined with other selection and extraction phases: on the one hand, the selection of the most meaningful characteristics based on information gain, and on the other hand, the inclusion of the nonlinear correlation between this subset of features, determined by an autoencoder. The results of the experiments conducted on GTZAN dataset reveal a noticeable contribution of this methodology towards the model's performance in classification task.