 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADTOF: A large dataset of non-synthetic music for automatic drum transcription
Paper and Code
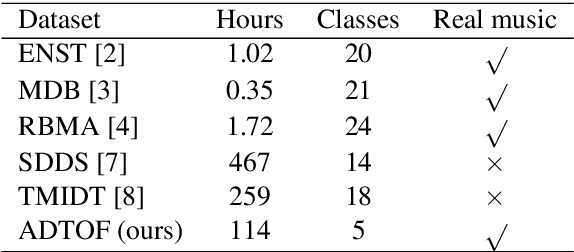

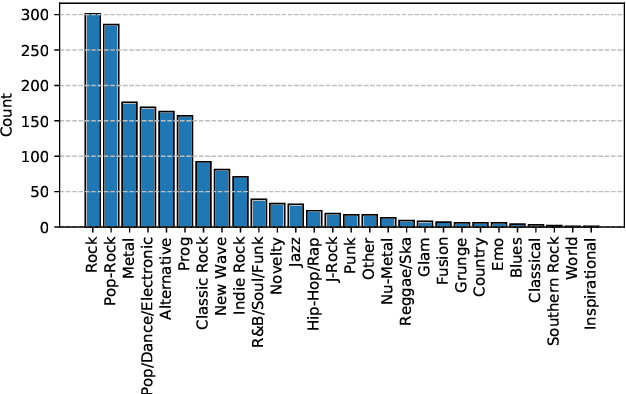
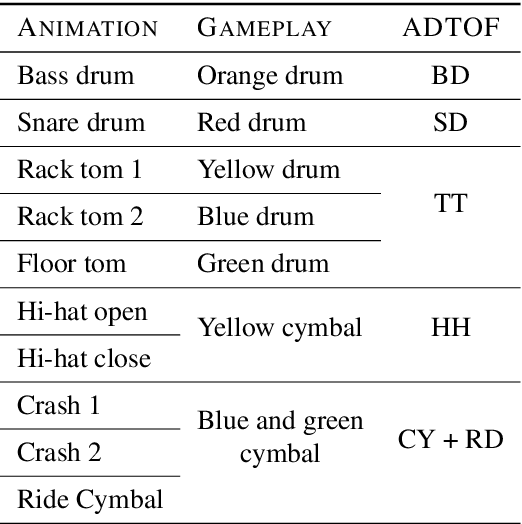
The state-of-the-art methods for drum transcription in the presence of melodic instruments (DTM) are machine learning models trained in a supervised manner, which means that they rely on labeled datasets. The problem is that the available public datasets are limited either in size or in realism, and are thus suboptimal for training purposes. Indeed, the best results are currently obtained via a rather convoluted multi-step training process that involves both real and synthetic datasets. To address this issue, starting from the observation that the communities of rhythm games players provide a large amount of annotated data, we curated a new dataset of crowdsourced drum transcriptions. This dataset contains real-world music, is manually annotated, and is about two orders of magnitude larger than any other non-synthetic dataset, making it a prime candidate for training purposes. However, due to crowdsourcing, the initial annotations contain mistakes. We discuss how the quality of the dataset can be improved by automatically correcting different types of mistakes. When used to train a popular DTM model, the dataset yields a performance that matches that of the state-of-the-art for DTM, thus demonstrating the quality of the annotations.