 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePepINVENT: Generative peptide design beyond the natural amino acids
Sep 21, 2024


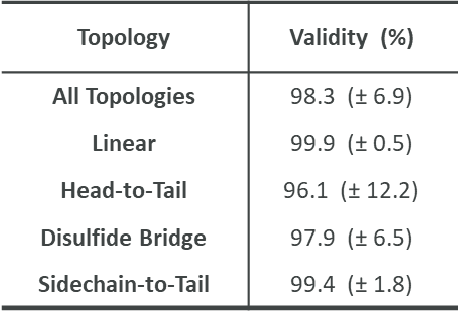
Peptides play a crucial role in the drug design and discovery whether as a therapeutic modality or a delivery agent. Non-natural amino acids (NNAAs) have been used to enhance the peptide properties from binding affinity, plasma stability to permeability. Incorporating novel NNAAs facilitates the design of more effective peptides with improved properties. The generative models used in the field, have focused on navigating the peptide sequence space. The sequence space is formed by combinations of a predefined set of amino acids. However, there is still a need for a tool to explore the peptide landscape beyond this enumerated space to unlock and effectively incorporate de novo design of new amino acids. To thoroughly explore the theoretical chemical space of the peptides, we present PepINVENT, a novel generative AI-based tool as an extension to the small molecule molecular design platform, REINVENT. PepINVENT navigates the vast space of natural and non-natural amino acids to propose valid, novel, and diverse peptide designs. The generative model can serve as a central tool for peptide-related tasks, as it was not trained on peptides with specific properties or topologies. The prior was trained to understand the granularity of peptides and to design amino acids for filling the masked positions within a peptide. PepINVENT coupled with reinforcement learning enables the goal-oriented design of peptides using its chemistry-informed generative capabilities. This study demonstrates PepINVENT's ability to explore the peptide space with unique and novel designs, and its capacity for property optimization in the context of therapeutically relevant peptides. Our tool can be employed for multi-parameter learning objectives, peptidomimetics, lead optimization, and variety of other tasks within the peptide domain.
Efficient 3D Molecular Generation with Flow Matching and Scale Optimal Transport
Jun 11, 2024



Generative models for 3D drug design have gained prominence recently for their potential to design ligands directly within protein pockets. Current approaches, however, often suffer from very slow sampling times or generate molecules with poor chemical validity. Addressing these limitations, we propose Semla, a scalable E(3)-equivariant message passing architecture. We further introduce a molecular generation model, MolFlow, which is trained using flow matching along with scale optimal transport, a novel extension of equivariant optimal transport. Our model produces state-of-the-art results on benchmark datasets with just 100 sampling steps. Crucially, MolFlow samples high quality molecules with as few as 20 steps, corresponding to a two order-of-magnitude speed-up compared to state-of-the-art, without sacrificing performance. Furthermore, we highlight limitations of current evaluation methods for 3D generation and propose new benchmark metrics for unconditional molecular generators. Finally, using these new metrics, we compare our model's ability to generate high quality samples against current approaches and further demonstrate MolFlow's strong performance.
Graph Neural Networks for Microbial Genome Recovery
Apr 26, 2022
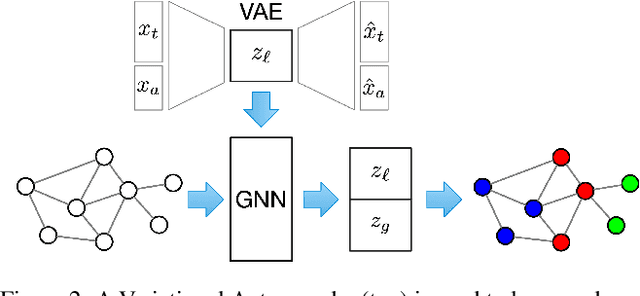
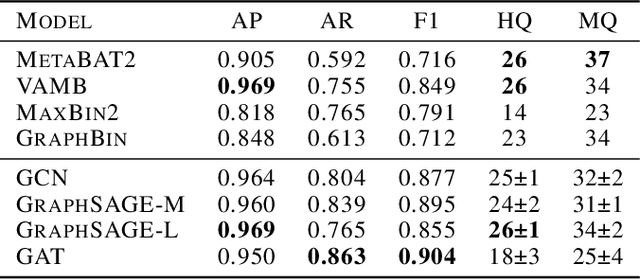
Microbes have a profound impact on our health and environment, but our understanding of the diversity and function of microbial communities is severely limited. Through DNA sequencing of microbial communities (metagenomics), DNA fragments (reads) of the individual microbes can be obtained, which through assembly graphs can be combined into long contiguous DNA sequences (contigs). Given the complexity of microbial communities, single contig microbial genomes are rarely obtained. Instead, contigs are eventually clustered into bins, with each bin ideally making up a full genome. This process is referred to as metagenomic binning. Current state-of-the-art techniques for metagenomic binning rely only on the local features for the individual contigs. These techniques therefore fail to exploit the similarities between contigs as encoded by the assembly graph, in which the contigs are organized. In this paper, we propose to use Graph Neural Networks (GNNs) to leverage the assembly graph when learning contig representations for metagenomic binning. Our method, VaeG-Bin, combines variational autoencoders for learning latent representations of the individual contigs, with GNNs for refining these representations by taking into account the neighborhood structure of the contigs in the assembly graph. We explore several types of GNNs and demonstrate that VaeG-Bin recovers more high-quality genomes than other state-of-the-art binners on both simulated and real-world datasets.
Inducing Gaussian Process Networks
Apr 21, 2022
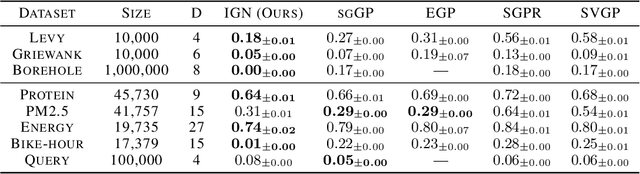


Gaussian processes (GPs) are powerful but computationally expensive machine learning models, requiring an estimate of the kernel covariance matrix for every prediction. In large and complex domains, such as graphs, sets, or images, the choice of suitable kernel can also be non-trivial to determine, providing an additional obstacle to the learning task. Over the last decade, these challenges have resulted in significant advances being made in terms of scalability and expressivity, exemplified by, e.g., the use of inducing points and neural network kernel approximations. In this paper, we propose inducing Gaussian process networks (IGN), a simple framework for simultaneously learning the feature space as well as the inducing points. The inducing points, in particular, are learned directly in the feature space, enabling a seamless representation of complex structured domains while also facilitating scalable gradient-based learning methods. We consider both regression and (binary) classification tasks and report on experimental results for real-world data sets showing that IGNs provide significant advances over state-of-the-art methods. We also demonstrate how IGNs can be used to effectively model complex domains using neural network architectures.
Learning Aggregation Functions
Dec 15, 2020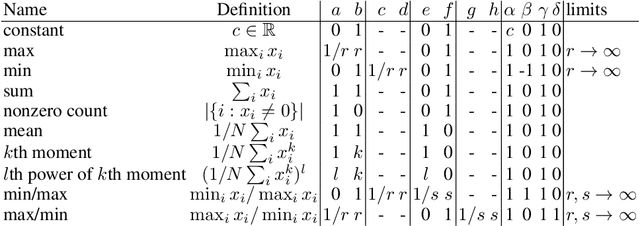
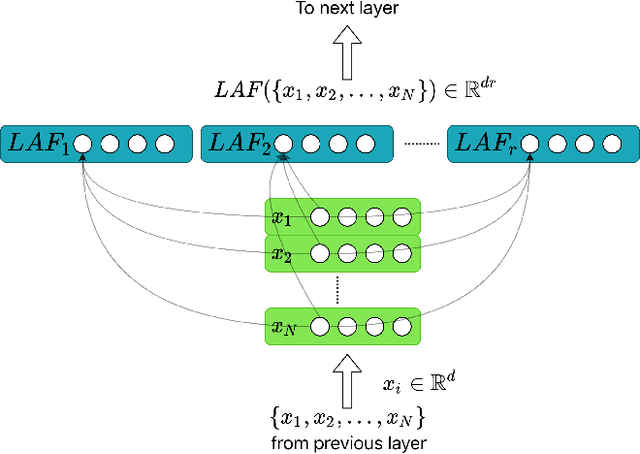

Learning on sets is increasingly gaining attention in the machine learning community, due to its widespread applicability. Typically, representations over sets are computed by using fixed aggregation functions such as sum or maximum. However, recent results showed that universal function representation by sum- (or max-) decomposition requires either highly discontinuous (and thus poorly learnable) mappings, or a latent dimension equal to the maximum number of elements in the set. To mitigate this problem, we introduce LAF (Learning Aggregation Functions), a learnable aggregator for sets of arbitrary cardinality. LAF can approximate several extensively used aggregators (such as average, sum, maximum) as well as more complex functions (e.g. variance and skewness). We report experiments on semi-synthetic and real data showing that LAF outperforms state-of-the-art sum- (max-) decomposition architectures such as DeepSets and library-based architectures like Principal Neighborhood Aggregation.
A general framework for defining and optimizing robustness
Jun 19, 2020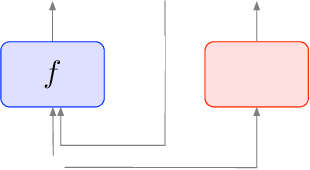
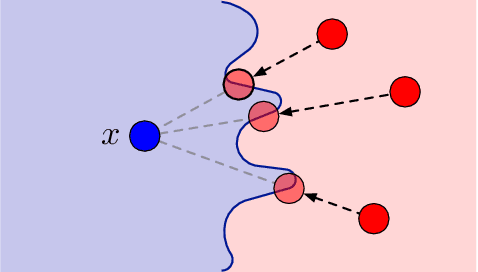
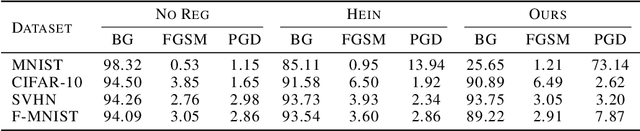
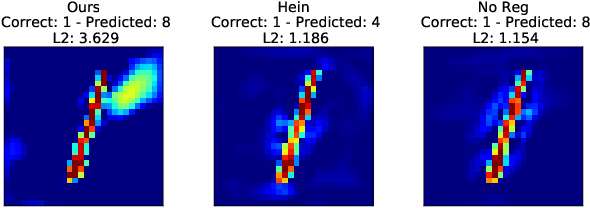
Robustness of neural networks has recently attracted a great amount of interest. The many investigations in this area lack a precise common foundation of robustness concepts. Therefore, in this paper, we propose a rigorous and flexible framework for defining different types of robustness that also help to explain the interplay between adversarial robustness and generalization. The different robustness objectives directly lead to an adjustable family of loss functions. For two robustness concepts of particular interest we show effective ways to minimize the corresponding loss functions. One loss is designed to strengthen robustness against adversarial off-manifold attacks, and another to improve generalization under the given data distribution. Empirical results show that we can effectively train under different robustness objectives, obtaining higher robustness scores and better generalization, for the two examples respectively, compared to the state-of-the-art data augmentation and regularization techniques.
Learning and Interpreting Multi-Multi-Instance Learning Networks
Oct 26, 2018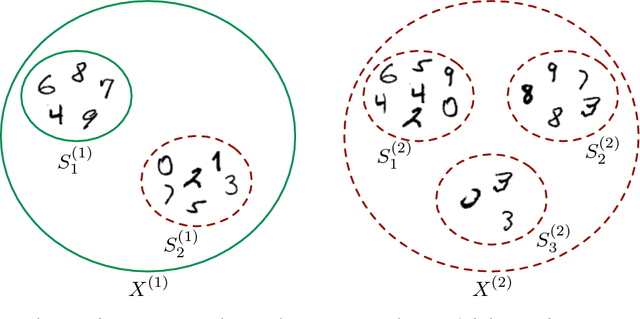
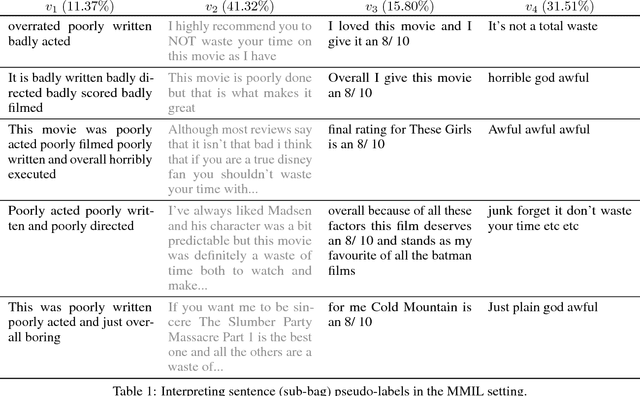
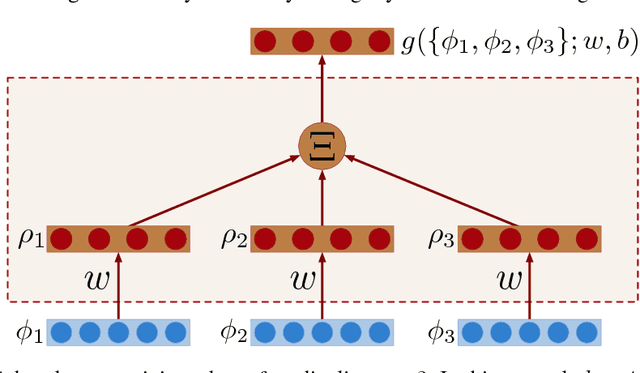
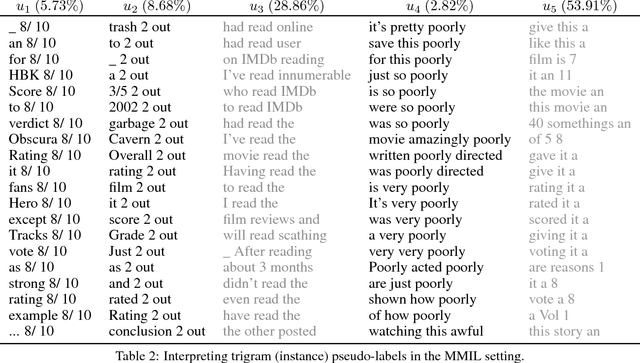
We introduce an extension of the multi-instance learning problem where examples are organized as nested bags of instances (e.g., a document could be represented as a bag of sentences, which in turn are bags of words). This framework can be useful in various scenarios, such as text and image classification, but also supervised learning over graphs. As a further advantage, multi-multi instance learning enables a particular way of interpreting predictions and the decision function. Our approach is based on a special neural network layer, called bag-layer, whose units aggregate bags of inputs of arbitrary size. We prove theoretically that the associated class of functions contains all Boolean functions over sets of sets of instances and we provide empirical evidence that functions of this kind can be actually learned on semi-synthetic datasets. We finally present experiments on text classification and on citation graphs and social graph data, showing that our model obtains competitive results with respect to other approaches such as convolutional networks on graphs.
Extended pipeline for content-based feature engineering in music genre recognition
May 12, 2018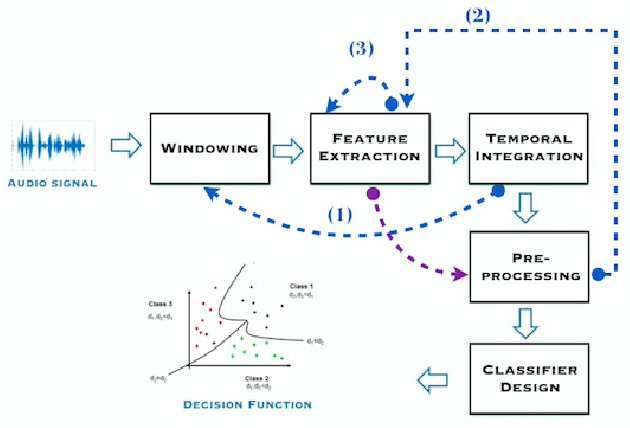
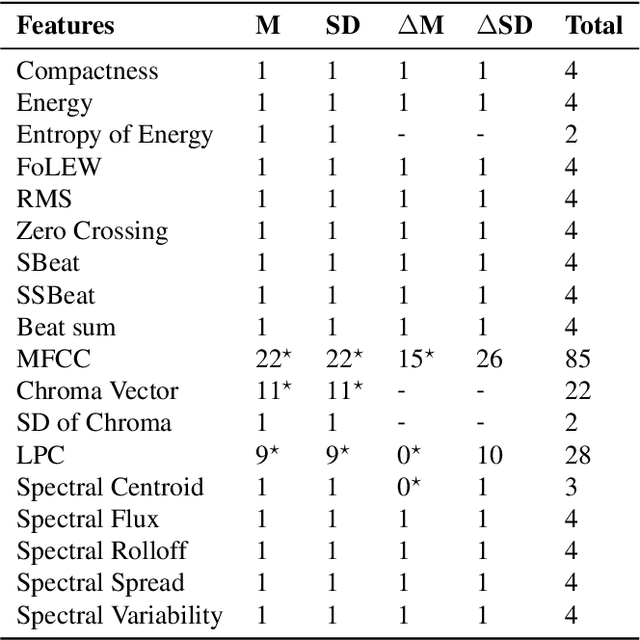
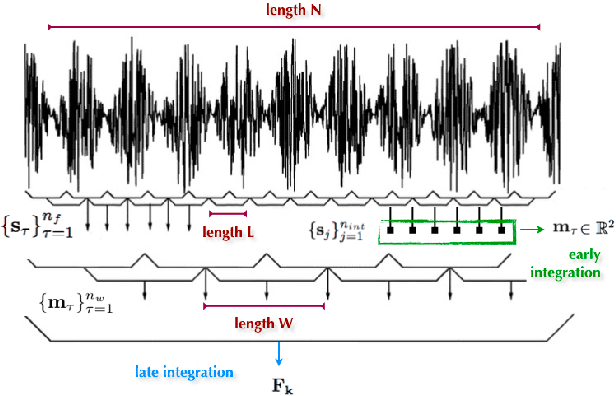

We present a feature engineering pipeline for the construction of musical signal characteristics, to be used for the design of a supervised model for musical genre identification. The key idea is to extend the traditional two-step process of extraction and classification with additive stand-alone phases which are no longer organized in a waterfall scheme. The whole system is realized by traversing backtrack arrows and cycles between various stages. In order to give a compact and effective representation of the features, the standard early temporal integration is combined with other selection and extraction phases: on the one hand, the selection of the most meaningful characteristics based on information gain, and on the other hand, the inclusion of the nonlinear correlation between this subset of features, determined by an autoencoder. The results of the experiments conducted on GTZAN dataset reveal a noticeable contribution of this methodology towards the model's performance in classification task.
Off the Beaten Track: Using Deep Learning to Interpolate Between Music Genres
May 02, 2018
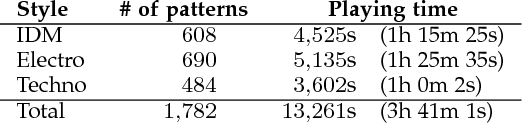
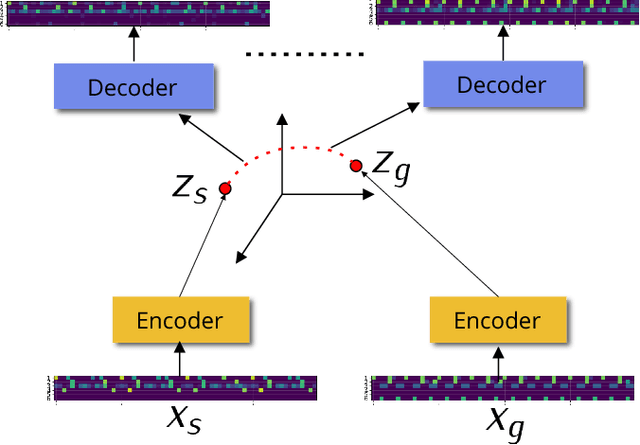
We describe a system based on deep learning that generates drum patterns in the electronic dance music domain. Experimental results reveal that generated patterns can be employed to produce musically sound and creative transitions between different genres, and that the process of generation is of interest to practitioners in the field.