 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA general framework for defining and optimizing robustness
Paper and Code
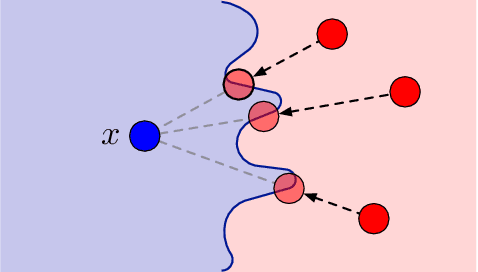
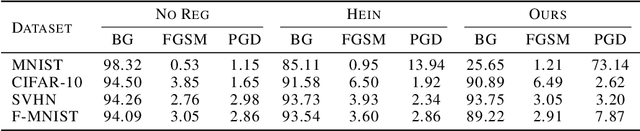
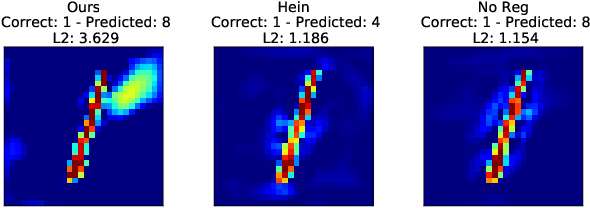
Robustness of neural networks has recently attracted a great amount of interest. The many investigations in this area lack a precise common foundation of robustness concepts. Therefore, in this paper, we propose a rigorous and flexible framework for defining different types of robustness that also help to explain the interplay between adversarial robustness and generalization. The different robustness objectives directly lead to an adjustable family of loss functions. For two robustness concepts of particular interest we show effective ways to minimize the corresponding loss functions. One loss is designed to strengthen robustness against adversarial off-manifold attacks, and another to improve generalization under the given data distribution. Empirical results show that we can effectively train under different robustness objectives, obtaining higher robustness scores and better generalization, for the two examples respectively, compared to the state-of-the-art data augmentation and regularization techniques.