 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness for All: Investigating Harms to Within-Group Individuals in Producer Fairness Re-ranking Optimization -- A Reproducibility Study
Sep 30, 2023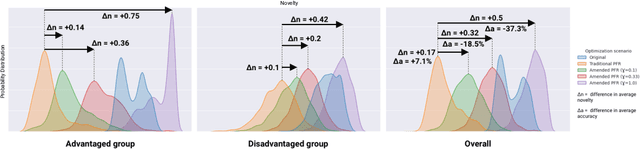
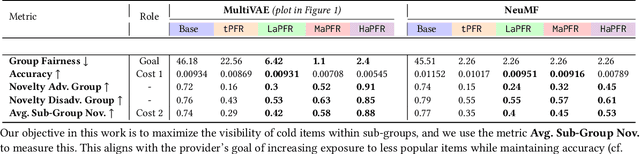
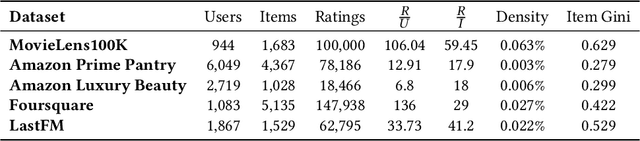
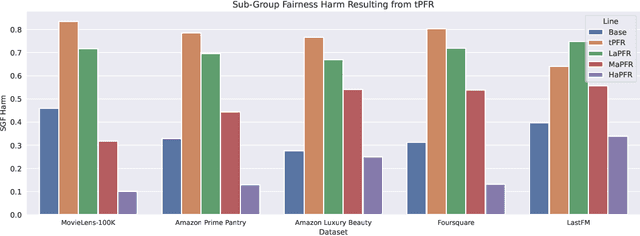
Recommender systems are widely used to provide personalized recommendations to users. Recent research has shown that recommender systems may be subject to different types of biases, such as popularity bias, leading to an uneven distribution of recommendation exposure among producer groups. To mitigate this, producer-centered fairness re-ranking (PFR) approaches have been proposed to ensure equitable recommendation utility across groups. However, these approaches overlook the harm they may cause to within-group individuals associated with colder items, which are items with few or no interactions. This study reproduces previous PFR approaches and shows that they significantly harm colder items, leading to a fairness gap for these items in both advantaged and disadvantaged groups. Surprisingly, the unfair base recommendation models were providing greater exposure opportunities to these individual cold items, even though at the group level, they appeared to be unfair. To address this issue, the study proposes an amendment to the PFR approach that regulates the number of colder items recommended by the system. This modification achieves a balance between accuracy and producer fairness while optimizing the selection of colder items within each group, thereby preventing or reducing harm to within-group individuals and augmenting the novelty of all recommended items. The proposed method is able to register an increase in sub-group fairness (SGF) from 0.3104 to 0.3782, 0.6156, and 0.9442 while also improving group-level fairness (GF) (112% and 37% with respect to base models and traditional PFR). Moreover, the proposed method achieves these improvements with minimal or no reduction in accuracy (or even an increase sometimes). We evaluate the proposed method on various recommendation datasets and demonstrate promising results independent of the underlying model or datasets.
Phase-Retrieval with Incomplete Autocorrelations Using Deep Convolutional Autoencoders
Apr 18, 2023



Phase-retrieval techniques aim to recover the original signal from just the modulus of its Fourier transform, which is usually much easier to measure than its phase, but the standard iterative techniques tend to fail if only part of the modulus information is available. We show that a neural network can be trained to perform phase retrieval using only incomplete information, and we discuss advantages and limitations of this approach.
A Review of Modern Fashion Recommender Systems
Feb 06, 2022


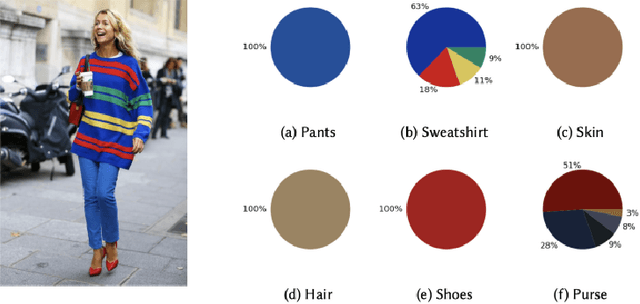
The textile and apparel industries have grown tremendously over the last years. Customers no longer have to visit many stores, stand in long queues, or try on garments in dressing rooms as millions of products are now available in online catalogs. However, given the plethora of options available, an effective recommendation system is necessary to properly sort, order, and communicate relevant product material or information to users. Effective fashion RS can have a noticeable impact on billions of customers' shopping experiences and increase sales and revenues on the provider-side. The goal of this survey is to provide a review of recommender systems that operate in the specific vertical domain of garment and fashion products. We have identified the most pressing challenges in fashion RS research and created a taxonomy that categorizes the literature according to the objective they are trying to accomplish (e.g., item or outfit recommendation, size recommendation, explainability, among others) and type of side-information (users, items, context). We have also identified the most important evaluation goals and perspectives (outfit generation, outfit recommendation, pairing recommendation, and fill-in-the-blank outfit compatibility prediction) and the most commonly used datasets and evaluation metrics.
Learning Aggregation Functions
Dec 15, 2020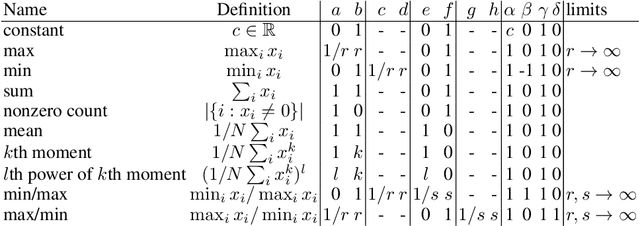
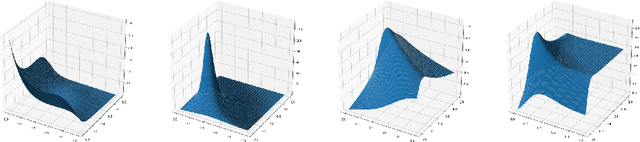
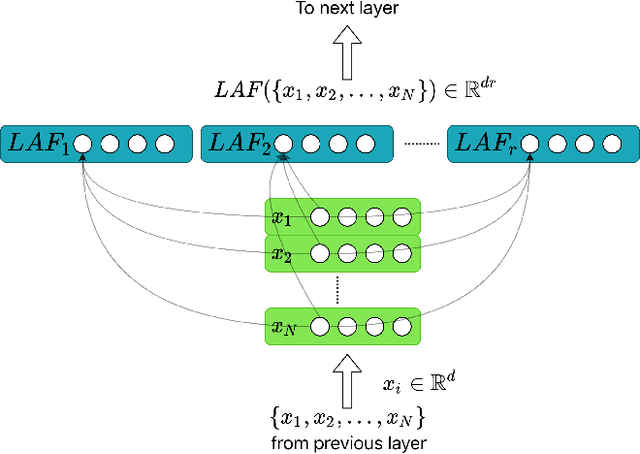

Learning on sets is increasingly gaining attention in the machine learning community, due to its widespread applicability. Typically, representations over sets are computed by using fixed aggregation functions such as sum or maximum. However, recent results showed that universal function representation by sum- (or max-) decomposition requires either highly discontinuous (and thus poorly learnable) mappings, or a latent dimension equal to the maximum number of elements in the set. To mitigate this problem, we introduce LAF (Learning Aggregation Functions), a learnable aggregator for sets of arbitrary cardinality. LAF can approximate several extensively used aggregators (such as average, sum, maximum) as well as more complex functions (e.g. variance and skewness). We report experiments on semi-synthetic and real data showing that LAF outperforms state-of-the-art sum- (max-) decomposition architectures such as DeepSets and library-based architectures like Principal Neighborhood Aggregation.