 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Robustness to Disfluencies in RNN-Transducer Based Speech Recognition
Dec 11, 2020



Automatic Speech Recognition (ASR) based on Recurrent Neural Network Transducers (RNN-T) is gaining interest in the speech community. We investigate data selection and preparation choices aiming for improved robustness of RNN-T ASR to speech disfluencies with a focus on partial words. For evaluation we use clean data, data with disfluencies and a separate dataset with speech affected by stuttering. We show that after including a small amount of data with disfluencies in the training set the recognition accuracy on the tests with disfluencies and stuttering improves. Increasing the amount of training data with disfluencies gives additional gains without degradation on the clean data. We also show that replacing partial words with a dedicated token helps to get even better accuracy on utterances with disfluencies and stutter. The evaluation of our best model shows 22.5% and 16.4% relative WER reduction on those two evaluation sets.
Bootstrap an end-to-end ASR system by multilingual training, transfer learning, text-to-text mapping and synthetic audio
Nov 25, 2020
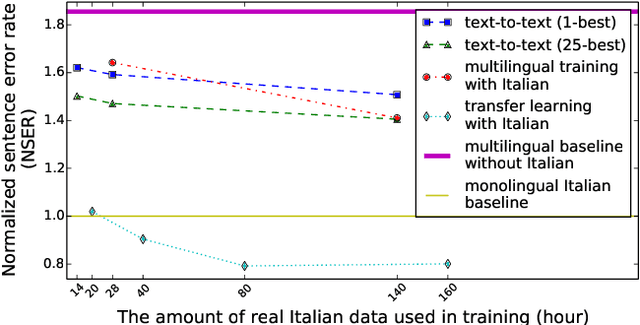
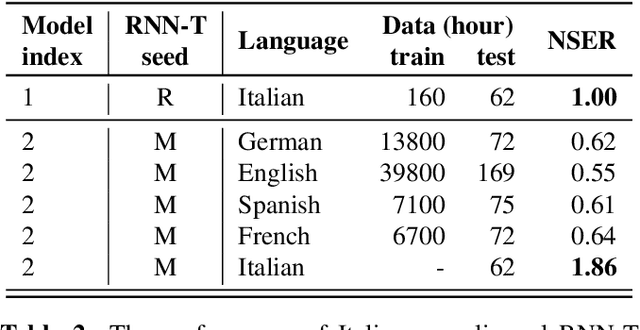
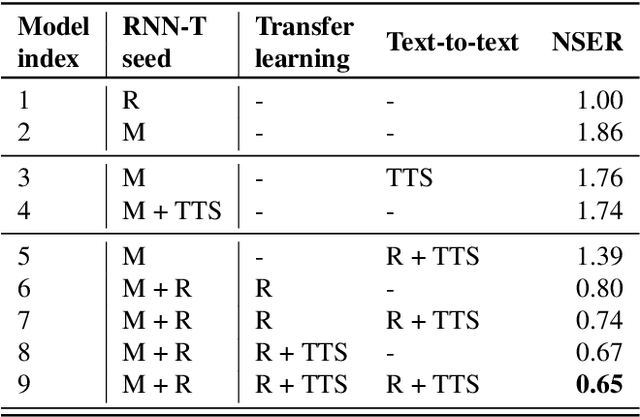
Bootstrapping speech recognition on limited data resources has been an area of active research for long. The recent transition to all-neural models and end-to-end (E2E) training brought along particular challenges as these models are known to be data hungry, but also came with opportunities around language-agnostic representations derived from multilingual data as well as shared word-piece output representations across languages that share script and roots.Here, we investigate the effectiveness of different strategies to bootstrap an RNN Transducer (RNN-T) based automatic speech recognition (ASR) system in the low resource regime,while exploiting the abundant resources available in other languages as well as the synthetic audio from a text-to-speech(TTS) engine. Experiments show that the combination of a multilingual RNN-T word-piece model, post-ASR text-to-text mapping, and synthetic audio can effectively bootstrap an ASR system for a new language in a scalable fashion with little target language data.