 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and scalable exchange-correlation with deep learning
Jun 18, 2025Density Functional Theory (DFT) is the most widely used electronic structure method for predicting the properties of molecules and materials. Although DFT is, in principle, an exact reformulation of the Schr\"odinger equation, practical applications rely on approximations to the unknown exchange-correlation (XC) functional. Most existing XC functionals are constructed using a limited set of increasingly complex, hand-crafted features that improve accuracy at the expense of computational efficiency. Yet, no current approximation achieves the accuracy and generality for predictive modeling of laboratory experiments at chemical accuracy -- typically defined as errors below 1 kcal/mol. In this work, we present Skala, a modern deep learning-based XC functional that bypasses expensive hand-designed features by learning representations directly from data. Skala achieves chemical accuracy for atomization energies of small molecules while retaining the computational efficiency typical of semi-local DFT. This performance is enabled by training on an unprecedented volume of high-accuracy reference data generated using computationally intensive wavefunction-based methods. Notably, Skala systematically improves with additional training data covering diverse chemistry. By incorporating a modest amount of additional high-accuracy data tailored to chemistry beyond atomization energies, Skala achieves accuracy competitive with the best-performing hybrid functionals across general main group chemistry, at the cost of semi-local DFT. As the training dataset continues to expand, Skala is poised to further enhance the predictive power of first-principles simulations.
Bootstrap an end-to-end ASR system by multilingual training, transfer learning, text-to-text mapping and synthetic audio
Nov 25, 2020
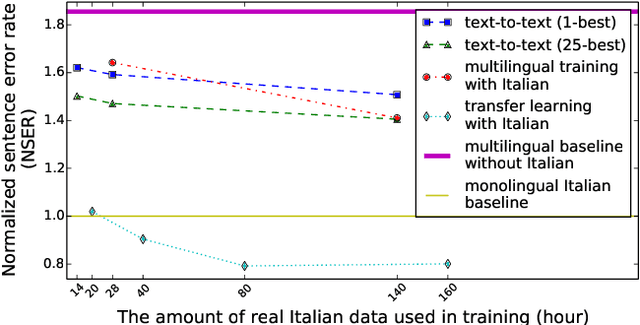
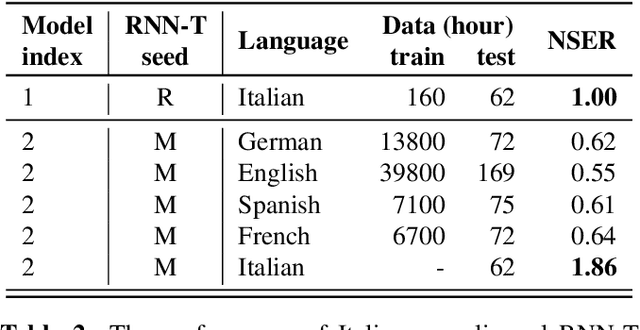
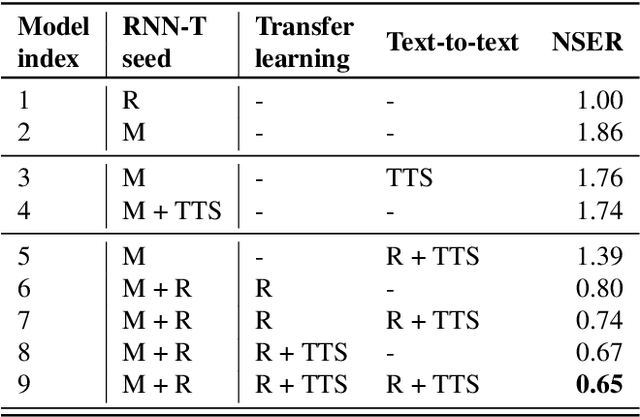
Bootstrapping speech recognition on limited data resources has been an area of active research for long. The recent transition to all-neural models and end-to-end (E2E) training brought along particular challenges as these models are known to be data hungry, but also came with opportunities around language-agnostic representations derived from multilingual data as well as shared word-piece output representations across languages that share script and roots.Here, we investigate the effectiveness of different strategies to bootstrap an RNN Transducer (RNN-T) based automatic speech recognition (ASR) system in the low resource regime,while exploiting the abundant resources available in other languages as well as the synthetic audio from a text-to-speech(TTS) engine. Experiments show that the combination of a multilingual RNN-T word-piece model, post-ASR text-to-text mapping, and synthetic audio can effectively bootstrap an ASR system for a new language in a scalable fashion with little target language data.