 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Support Vector Machine Classifiers with the $\ell_0$-Norm Hinge Loss
Jun 24, 2023Support Vector Machine (SVM) has been one of the most successful machine learning techniques for binary classification problems. The key idea is to maximize the margin from the data to the hyperplane subject to correct classification on training samples. The commonly used hinge loss and its variations are sensitive to label noise, and unstable for resampling due to its unboundedness. This paper is concentrated on the kernel SVM with the $\ell_0$-norm hinge loss (referred as $\ell_0$-KSVM), which is a composite function of hinge loss and $\ell_0$-norm and then could overcome the difficulties mentioned above. In consideration of the nonconvexity and nonsmoothness of $\ell_0$-norm hinge loss, we first characterize the limiting subdifferential of the $\ell_0$-norm hinge loss and then derive the equivalent relationship among the proximal stationary point, the Karush-Kuhn-Tucker point, and the local optimal solution of $\ell_0$-KSVM. Secondly, we develop an ADMM algorithm for $\ell_0$-KSVM, and obtain that any limit point of the sequence generated by the proposed algorithm is a locally optimal solution. Lastly, some experiments on the synthetic and real datasets are illuminated to show that $\ell_0$-KSVM can achieve comparable accuracy compared with the standard KSVM while the former generally enjoys fewer support vectors.
Multi-turn RNN-T for streaming recognition of multi-party speech
Dec 19, 2021



Automatic speech recognition (ASR) of single channel far-field recordings with an unknown number of speakers is traditionally tackled by cascaded modules. Recent research shows that end-to-end (E2E) multi-speaker ASR models can achieve superior recognition accuracy compared to modular systems. However, these models do not ensure real-time applicability due to their dependency on full audio context. This work takes real-time applicability as the first priority in model design and addresses a few challenges in previous work on multi-speaker recurrent neural network transducer (MS-RNN-T). First, we introduce on-the-fly overlapping speech simulation during training, yielding 14% relative word error rate (WER) improvement on LibriSpeechMix test set. Second, we propose a novel multi-turn RNN-T (MT-RNN-T) model with an overlap-based target arrangement strategy that generalizes to an arbitrary number of speakers without changes in the model architecture. We investigate the impact of the maximum number of speakers seen during training on MT-RNN-T performance on LibriCSS test set, and report 28% relative WER improvement over the two-speaker MS-RNN-T. Third, we experiment with a rich transcription strategy for joint recognition and segmentation of multi-party speech. Through an in-depth analysis, we discuss potential pitfalls of the proposed system as well as promising future research directions.
SynthASR: Unlocking Synthetic Data for Speech Recognition
Jun 14, 2021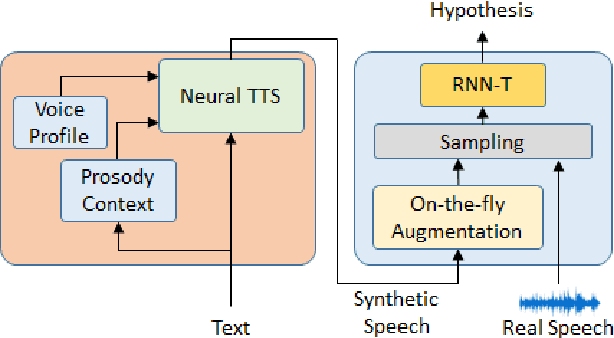
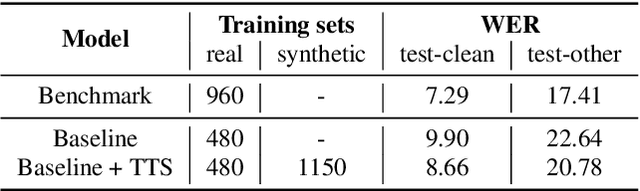
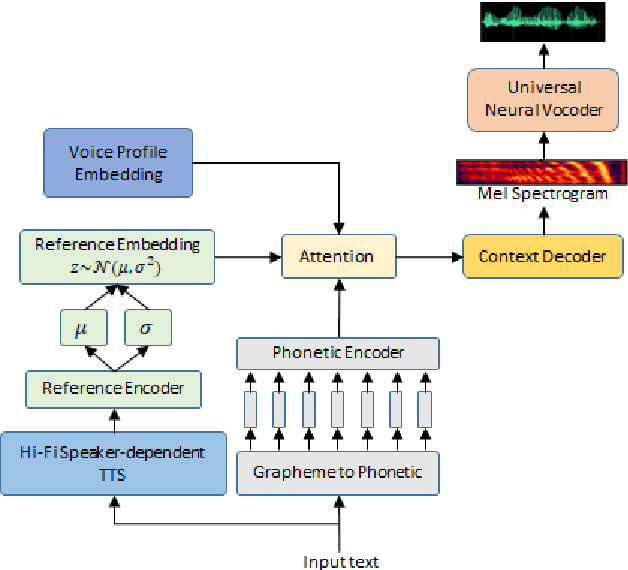
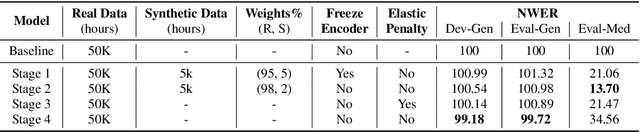
End-to-end (E2E) automatic speech recognition (ASR) models have recently demonstrated superior performance over the traditional hybrid ASR models. Training an E2E ASR model requires a large amount of data which is not only expensive but may also raise dependency on production data. At the same time, synthetic speech generated by the state-of-the-art text-to-speech (TTS) engines has advanced to near-human naturalness. In this work, we propose to utilize synthetic speech for ASR training (SynthASR) in applications where data is sparse or hard to get for ASR model training. In addition, we apply continual learning with a novel multi-stage training strategy to address catastrophic forgetting, achieved by a mix of weighted multi-style training, data augmentation, encoder freezing, and parameter regularization. In our experiments conducted on in-house datasets for a new application of recognizing medication names, training ASR RNN-T models with synthetic audio via the proposed multi-stage training improved the recognition performance on new application by more than 65% relative, without degradation on existing general applications. Our observations show that SynthASR holds great promise in training the state-of-the-art large-scale E2E ASR models for new applications while reducing the costs and dependency on production data.
Bootstrap an end-to-end ASR system by multilingual training, transfer learning, text-to-text mapping and synthetic audio
Nov 25, 2020
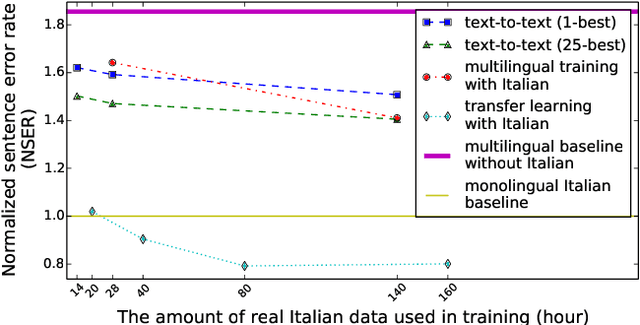
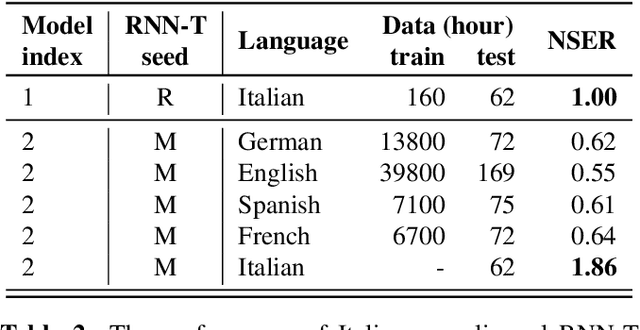
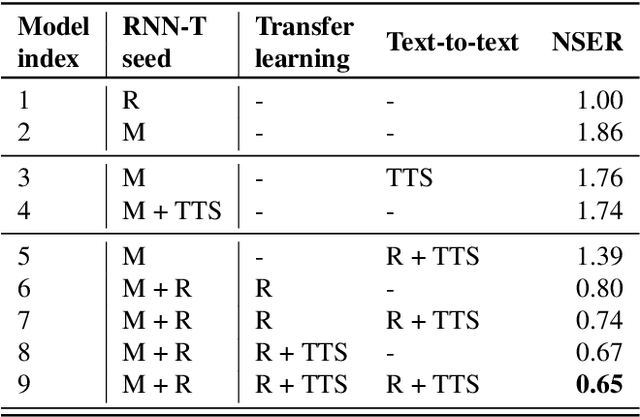
Bootstrapping speech recognition on limited data resources has been an area of active research for long. The recent transition to all-neural models and end-to-end (E2E) training brought along particular challenges as these models are known to be data hungry, but also came with opportunities around language-agnostic representations derived from multilingual data as well as shared word-piece output representations across languages that share script and roots.Here, we investigate the effectiveness of different strategies to bootstrap an RNN Transducer (RNN-T) based automatic speech recognition (ASR) system in the low resource regime,while exploiting the abundant resources available in other languages as well as the synthetic audio from a text-to-speech(TTS) engine. Experiments show that the combination of a multilingual RNN-T word-piece model, post-ASR text-to-text mapping, and synthetic audio can effectively bootstrap an ASR system for a new language in a scalable fashion with little target language data.
Streaming Multi-speaker ASR with RNN-T
Nov 23, 2020
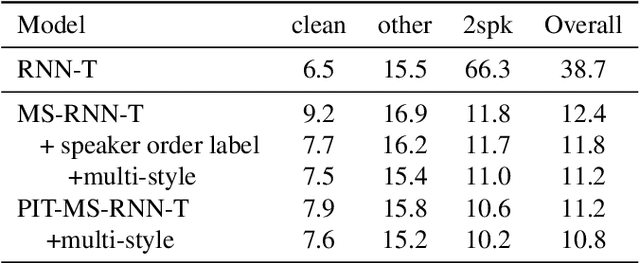
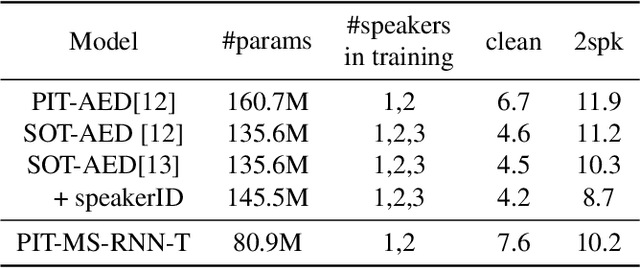
Recent research shows end-to-end ASR systems can recognize overlapped speech from multiple speakers. However, all published works have assumed no latency constraints during inference, which does not hold for most voice assistant interactions. This work focuses on multi-speaker speech recognition based on a recurrent neural network transducer (RNN-T) that has been shown to provide high recognition accuracy at a low latency online recognition regime. We investigate two approaches to multi-speaker model training of the RNN-T: deterministic output-target assignment and permutation invariant training. We show that guiding separation with speaker order labels in the former case enhances the high-level speaker tracking capability of RNN-T. Apart from that, with multistyle training on single- and multi-speaker utterances, the resulting models gain robustness against ambiguous numbers of speakers during inference. Our best model achieves a WER of 10.2% on simulated 2-speaker LibriSpeech data, which is competitive with the previously reported state-of-the-art nonstreaming model (10.3%), while the proposed model could be directly applied for streaming applications.
Equivalent Lipschitz surrogates for zero-norm and rank optimization problems
Apr 30, 2018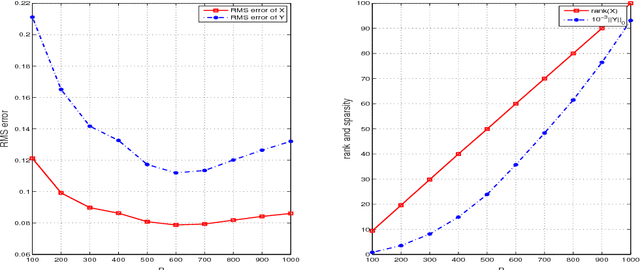
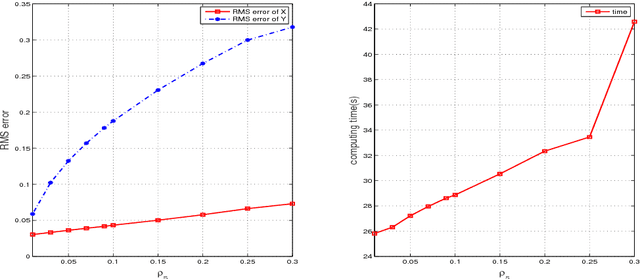
This paper proposes a mechanism to produce equivalent Lipschitz surrogates for zero-norm and rank optimization problems by means of the global exact penalty for their equivalent mathematical programs with an equilibrium constraint (MPECs). Specifically, we reformulate these combinatorial problems as equivalent MPECs by the variational characterization of the zero-norm and rank function, show that their penalized problems, yielded by moving the equilibrium constraint into the objective, are the global exact penalization, and obtain the equivalent Lipschitz surrogates by eliminating the dual variable in the global exact penalty. These surrogates, including the popular SCAD function in statistics, are also difference of two convex functions (D.C.) if the function and constraint set involved in zero-norm and rank optimization problems are convex. We illustrate an application by designing a multi-stage convex relaxation approach to the rank plus zero-norm regularized minimization problem.
The 2015 Sheffield System for Transcription of Multi-Genre Broadcast Media
Dec 21, 2015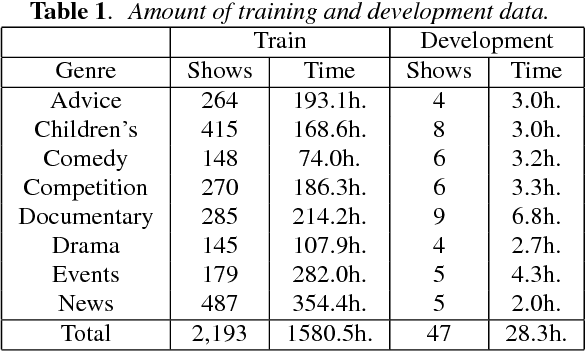
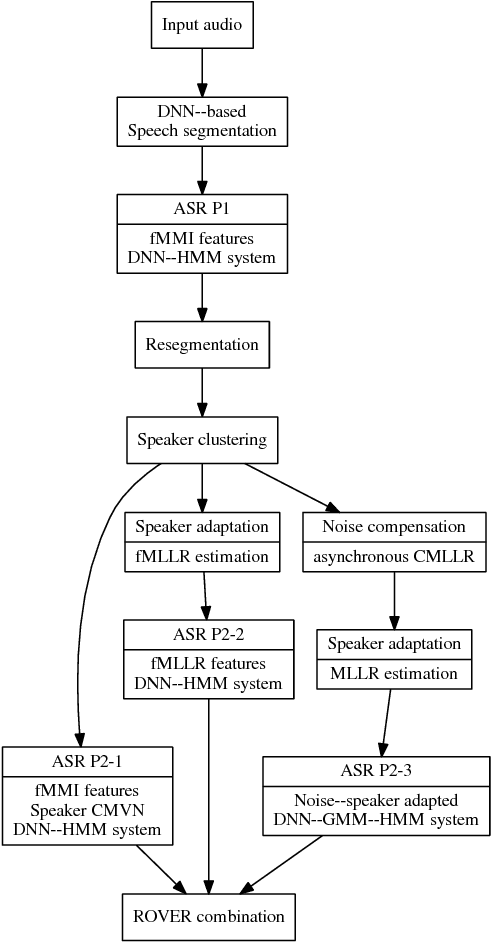
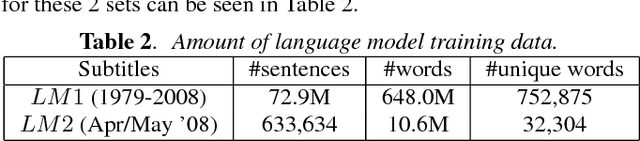
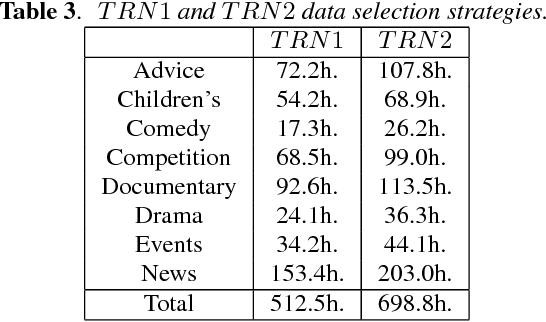
We describe the University of Sheffield system for participation in the 2015 Multi-Genre Broadcast (MGB) challenge task of transcribing multi-genre broadcast shows. Transcription was one of four tasks proposed in the MGB challenge, with the aim of advancing the state of the art of automatic speech recognition, speaker diarisation and automatic alignment of subtitles for broadcast media. Four topics are investigated in this work: Data selection techniques for training with unreliable data, automatic speech segmentation of broadcast media shows, acoustic modelling and adaptation in highly variable environments, and language modelling of multi-genre shows. The final system operates in multiple passes, using an initial unadapted decoding stage to refine segmentation, followed by three adapted passes: a hybrid DNN pass with input features normalised by speaker-based cepstral normalisation, another hybrid stage with input features normalised by speaker feature-MLLR transformations, and finally a bottleneck-based tandem stage with noise and speaker factorisation. The combination of these three system outputs provides a final error rate of 27.5% on the official development set, consisting of 47 multi-genre shows.