 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Genre and Show Identification of Broadcast Media
Jun 10, 2016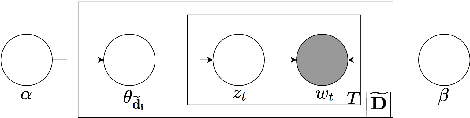
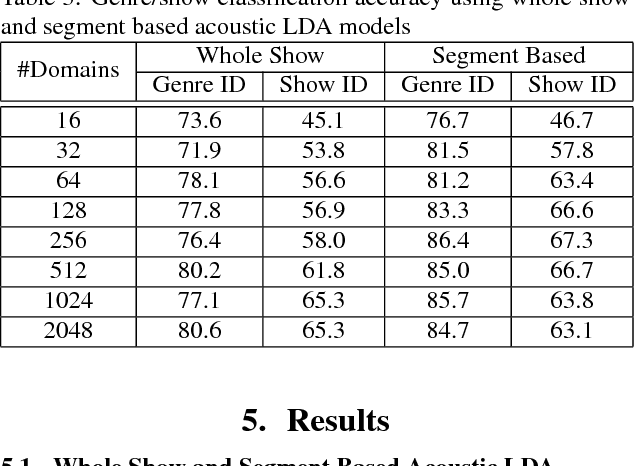
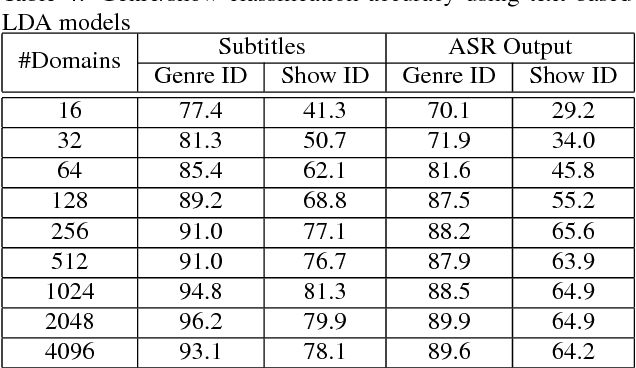
Huge amounts of digital videos are being produced and broadcast every day, leading to giant media archives. Effective techniques are needed to make such data accessible further. Automatic meta-data labelling of broadcast media is an essential task for multimedia indexing, where it is standard to use multi-modal input for such purposes. This paper describes a novel method for automatic detection of media genre and show identities using acoustic features, textual features or a combination thereof. Furthermore the inclusion of available meta-data, such as time of broadcast, is shown to lead to very high performance. Latent Dirichlet Allocation is used to model both acoustics and text, yielding fixed dimensional representations of media recordings that can then be used in Support Vector Machines based classification. Experiments are conducted on more than 1200 hours of TV broadcasts from the British Broadcasting Corporation (BBC), where the task is to categorise the broadcasts into 8 genres or 133 show identities. On a 200-hour test set, accuracies of 98.6% and 85.7% were achieved for genre and show identification respectively, using a combination of acoustic and textual features with meta-data.
The 2015 Sheffield System for Transcription of Multi-Genre Broadcast Media
Dec 21, 2015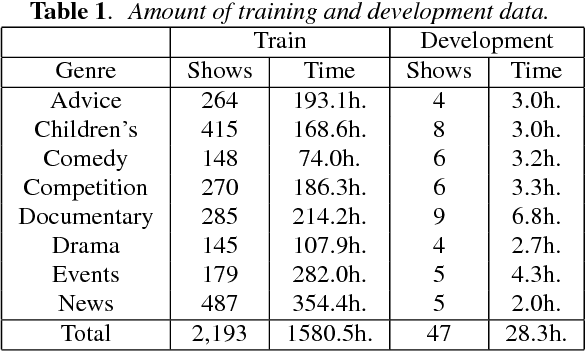
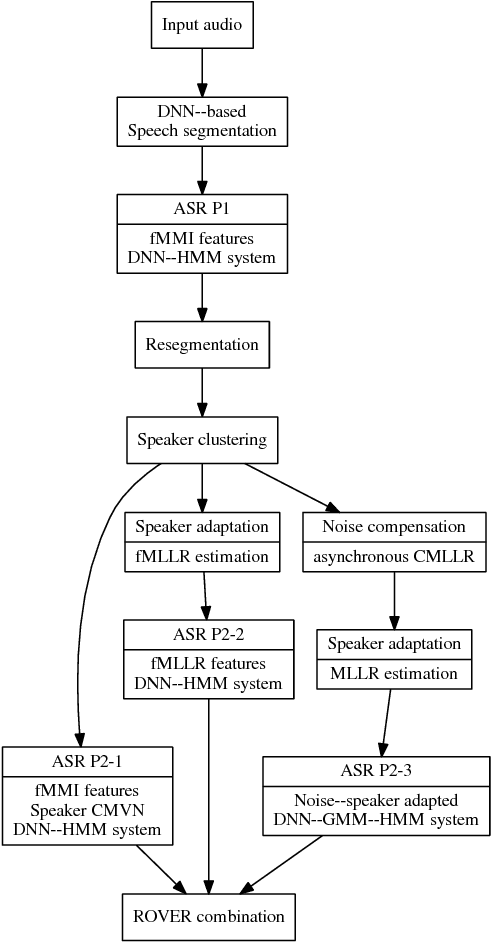
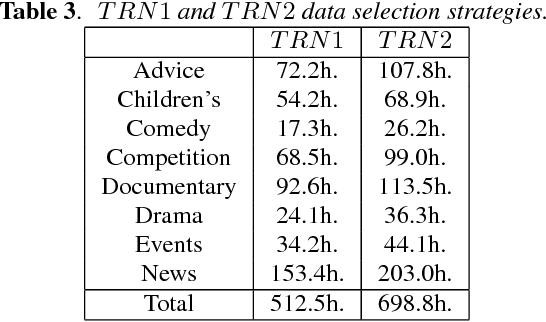
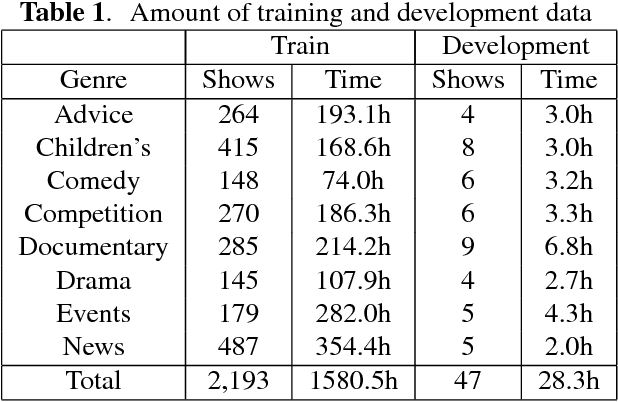
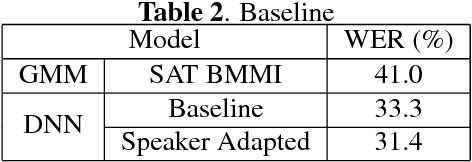
We describe the University of Sheffield system for participation in the 2015 Multi-Genre Broadcast (MGB) challenge task of transcribing multi-genre broadcast shows. Transcription was one of four tasks proposed in the MGB challenge, with the aim of advancing the state of the art of automatic speech recognition, speaker diarisation and automatic alignment of subtitles for broadcast media. Four topics are investigated in this work: Data selection techniques for training with unreliable data, automatic speech segmentation of broadcast media shows, acoustic modelling and adaptation in highly variable environments, and language modelling of multi-genre shows. The final system operates in multiple passes, using an initial unadapted decoding stage to refine segmentation, followed by three adapted passes: a hybrid DNN pass with input features normalised by speaker-based cepstral normalisation, another hybrid stage with input features normalised by speaker feature-MLLR transformations, and finally a bottleneck-based tandem stage with noise and speaker factorisation. The combination of these three system outputs provides a final error rate of 27.5% on the official development set, consisting of 47 multi-genre shows.
Latent Dirichlet Allocation Based Organisation of Broadcast Media Archives for Deep Neural Network Adaptation
Nov 16, 2015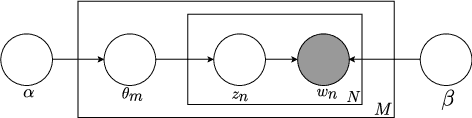
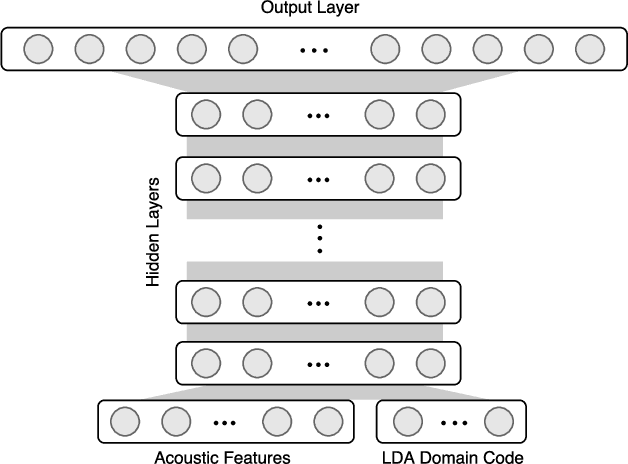
This paper presents a new method for the discovery of latent domains in diverse speech data, for the use of adaptation of Deep Neural Networks (DNNs) for Automatic Speech Recognition. Our work focuses on transcription of multi-genre broadcast media, which is often only categorised broadly in terms of high level genres such as sports, news, documentary, etc. However, in terms of acoustic modelling these categories are coarse. Instead, it is expected that a mixture of latent domains can better represent the complex and diverse behaviours within a TV show, and therefore lead to better and more robust performance. We propose a new method, whereby these latent domains are discovered with Latent Dirichlet Allocation, in an unsupervised manner. These are used to adapt DNNs using the Unique Binary Code (UBIC) representation for the LDA domains. Experiments conducted on a set of BBC TV broadcasts, with more than 2,000 shows for training and 47 shows for testing, show that the use of LDA-UBIC DNNs reduces the error up to 13% relative compared to the baseline hybrid DNN models.
The USFD Spoken Language Translation System for IWSLT 2014
Sep 13, 2015
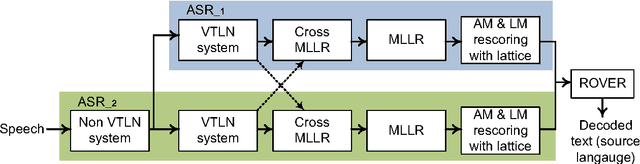
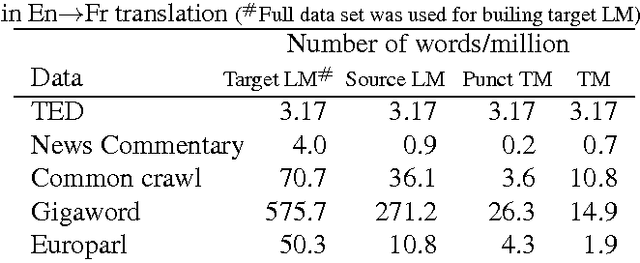
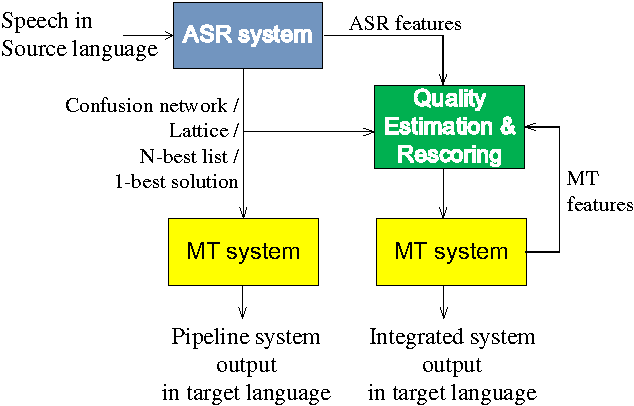
The University of Sheffield (USFD) participated in the International Workshop for Spoken Language Translation (IWSLT) in 2014. In this paper, we will introduce the USFD SLT system for IWSLT. Automatic speech recognition (ASR) is achieved by two multi-pass deep neural network systems with adaptation and rescoring techniques. Machine translation (MT) is achieved by a phrase-based system. The USFD primary system incorporates state-of-the-art ASR and MT techniques and gives a BLEU score of 23.45 and 14.75 on the English-to-French and English-to-German speech-to-text translation task with the IWSLT 2014 data. The USFD contrastive systems explore the integration of ASR and MT by using a quality estimation system to rescore the ASR outputs, optimising towards better translation. This gives a further 0.54 and 0.26 BLEU improvement respectively on the IWSLT 2012 and 2014 evaluation data.
Unsupervised Domain Discovery using Latent Dirichlet Allocation for Acoustic Modelling in Speech Recognition
Sep 08, 2015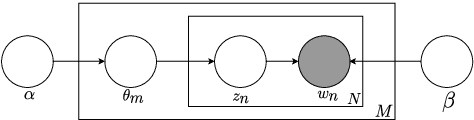
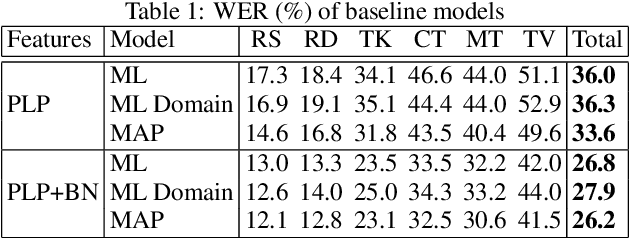


Speech recognition systems are often highly domain dependent, a fact widely reported in the literature. However the concept of domain is complex and not bound to clear criteria. Hence it is often not evident if data should be considered to be out-of-domain. While both acoustic and language models can be domain specific, work in this paper concentrates on acoustic modelling. We present a novel method to perform unsupervised discovery of domains using Latent Dirichlet Allocation (LDA) modelling. Here a set of hidden domains is assumed to exist in the data, whereby each audio segment can be considered to be a weighted mixture of domain properties. The classification of audio segments into domains allows the creation of domain specific acoustic models for automatic speech recognition. Experiments are conducted on a dataset of diverse speech data covering speech from radio and TV broadcasts, telephone conversations, meetings, lectures and read speech, with a joint training set of 60 hours and a test set of 6 hours. Maximum A Posteriori (MAP) adaptation to LDA based domains was shown to yield relative Word Error Rate (WER) improvements of up to 16% relative, compared to pooled training, and up to 10%, compared with models adapted with human-labelled prior domain knowledge.
Data-selective Transfer Learning for Multi-Domain Speech Recognition
Sep 08, 2015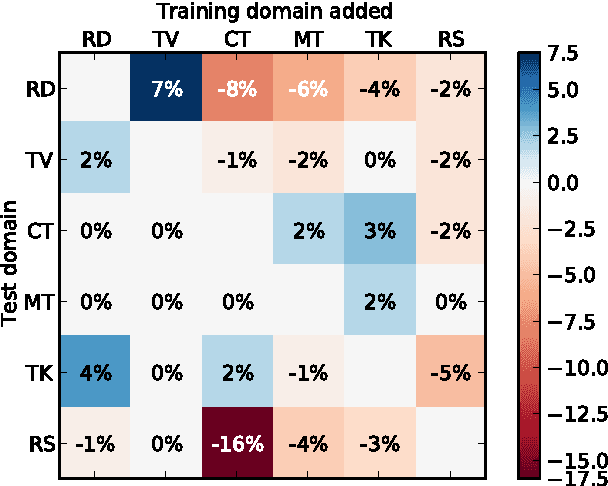


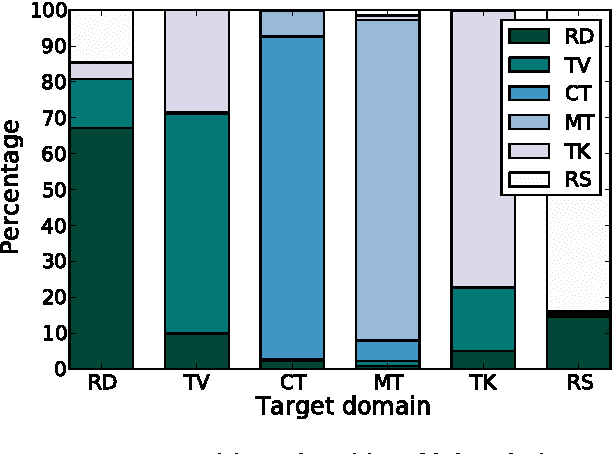
Negative transfer in training of acoustic models for automatic speech recognition has been reported in several contexts such as domain change or speaker characteristics. This paper proposes a novel technique to overcome negative transfer by efficient selection of speech data for acoustic model training. Here data is chosen on relevance for a specific target. A submodular function based on likelihood ratios is used to determine how acoustically similar each training utterance is to a target test set. The approach is evaluated on a wide-domain data set, covering speech from radio and TV broadcasts, telephone conversations, meetings, lectures and read speech. Experiments demonstrate that the proposed technique both finds relevant data and limits negative transfer. Results on a 6--hour test set show a relative improvement of 4% with data selection over using all data in PLP based models, and 2% with DNN features.