 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Dirichlet Allocation Based Organisation of Broadcast Media Archives for Deep Neural Network Adaptation
Paper and Code
Nov 16, 2015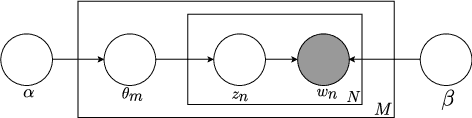
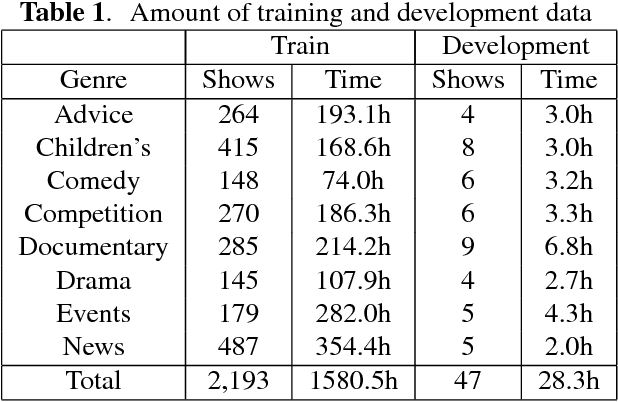
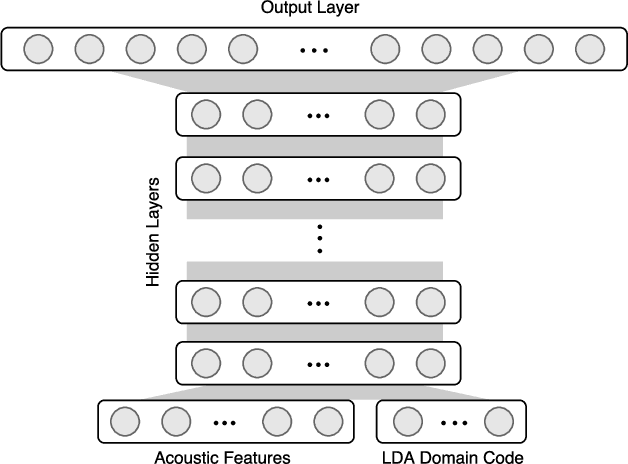
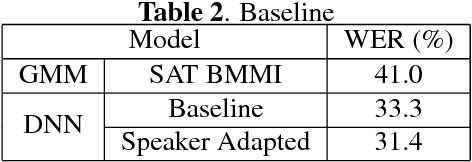
This paper presents a new method for the discovery of latent domains in diverse speech data, for the use of adaptation of Deep Neural Networks (DNNs) for Automatic Speech Recognition. Our work focuses on transcription of multi-genre broadcast media, which is often only categorised broadly in terms of high level genres such as sports, news, documentary, etc. However, in terms of acoustic modelling these categories are coarse. Instead, it is expected that a mixture of latent domains can better represent the complex and diverse behaviours within a TV show, and therefore lead to better and more robust performance. We propose a new method, whereby these latent domains are discovered with Latent Dirichlet Allocation, in an unsupervised manner. These are used to adapt DNNs using the Unique Binary Code (UBIC) representation for the LDA domains. Experiments conducted on a set of BBC TV broadcasts, with more than 2,000 shows for training and 47 shows for testing, show that the use of LDA-UBIC DNNs reduces the error up to 13% relative compared to the baseline hybrid DNN models.