 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of Chain-of-Thought in Distilling Reasoning Capability from Large Language Models
Nov 07, 2025Chain-of-Thought (CoT) prompting is a widely used method to improve the reasoning capability of Large Language Models (LLMs). More recently, CoT has been leveraged in Knowledge Distillation (KD) to transfer reasoning capability from a larger LLM to a smaller one. This paper examines the role of CoT in distilling the reasoning capability from larger LLMs to smaller LLMs using white-box KD, analysing its effectiveness in improving the performance of the distilled models for various natural language reasoning and understanding tasks. We conduct white-box KD experiments using LLMs from the Qwen and Llama2 families, employing CoT data from the CoT-Collection dataset. The distilled models are then evaluated on natural language reasoning and understanding tasks from the BIG-Bench-Hard (BBH) benchmark, which presents complex challenges for smaller LLMs. Experimental results demonstrate the role of CoT in improving white-box KD effectiveness, enabling the distilled models to achieve better average performance in natural language reasoning and understanding tasks from BBH.
WHISMA: A Speech-LLM to Perform Zero-shot Spoken Language Understanding
Aug 29, 2024



Speech large language models (speech-LLMs) integrate speech and text-based foundation models to provide a unified framework for handling a wide range of downstream tasks. In this paper, we introduce WHISMA, a speech-LLM tailored for spoken language understanding (SLU) that demonstrates robust performance in various zero-shot settings. WHISMA combines the speech encoder from Whisper with the Llama-3 LLM, and is fine-tuned in a parameter-efficient manner on a comprehensive collection of SLU-related datasets. Our experiments show that WHISMA significantly improves the zero-shot slot filling performance on the SLURP benchmark, achieving a relative gain of 26.6% compared to the current state-of-the-art model. Furthermore, to evaluate WHISMA's generalisation capabilities to unseen domains, we develop a new task-agnostic benchmark named SLU-GLUE. The evaluation results indicate that WHISMA outperforms an existing speech-LLM (Qwen-Audio) with a relative gain of 33.0%.
Improving Accented Speech Recognition using Data Augmentation based on Unsupervised Text-to-Speech Synthesis
Jul 04, 2024



This paper investigates the use of unsupervised text-to-speech synthesis (TTS) as a data augmentation method to improve accented speech recognition. TTS systems are trained with a small amount of accented speech training data and their pseudo-labels rather than manual transcriptions, and hence unsupervised. This approach enables the use of accented speech data without manual transcriptions to perform data augmentation for accented speech recognition. Synthetic accented speech data, generated from text prompts by using the TTS systems, are then combined with available non-accented speech data to train automatic speech recognition (ASR) systems. ASR experiments are performed in a self-supervised learning framework using a Wav2vec2.0 model which was pre-trained on large amount of unsupervised accented speech data. The accented speech data for training the unsupervised TTS are read speech, selected from L2-ARCTIC and British Isles corpora, while spontaneous conversational speech from the Edinburgh international accents of English corpus are used as the evaluation data. Experimental results show that Wav2vec2.0 models which are fine-tuned to downstream ASR task with synthetic accented speech data, generated by the unsupervised TTS, yield up to 6.1% relative word error rate reductions compared to a Wav2vec2.0 baseline which is fine-tuned with the non-accented speech data from Librispeech corpus.
Prompting Whisper for QA-driven Zero-shot End-to-end Spoken Language Understanding
Jun 21, 2024



Zero-shot spoken language understanding (SLU) enables systems to comprehend user utterances in new domains without prior exposure to training data. Recent studies often rely on large language models (LLMs), leading to excessive footprints and complexity. This paper proposes the use of Whisper, a standalone speech processing model, for zero-shot end-to-end (E2E) SLU. To handle unseen semantic labels, SLU tasks are integrated into a question-answering (QA) framework, which prompts the Whisper decoder for semantics deduction. The system is efficiently trained with prefix-tuning, optimising a minimal set of parameters rather than the entire Whisper model. We show that the proposed system achieves a 40.7% absolute gain for slot filling (SLU-F1) on SLURP compared to a recently introduced zero-shot benchmark. Furthermore, it performs comparably to a Whisper-GPT-2 modular system under both in-corpus and cross-corpus evaluation settings, but with a relative 34.8% reduction in model parameters.
Geodesic interpolation of frame-wise speaker embeddings for the diarization of meeting scenarios
Jan 08, 2024



We propose a modified teacher-student training for the extraction of frame-wise speaker embeddings that allows for an effective diarization of meeting scenarios containing partially overlapping speech. To this end, a geodesic distance loss is used that enforces the embeddings computed from regions with two active speakers to lie on the shortest path on a sphere between the points given by the d-vectors of each of the active speakers. Using those frame-wise speaker embeddings in clustering-based diarization outperforms segment-level clustering-based diarization systems such as VBx and Spectral Clustering. By extending our approach to a mixture-model-based diarization, the performance can be further improved, approaching the diarization error rates of diarization systems that use a dedicated overlap detection, and outperforming these systems when also employing an additional overlap detection.
Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
Sep 21, 2023
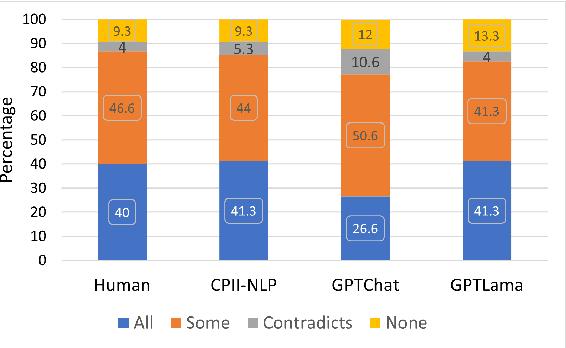


In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
A Teacher-Student approach for extracting informative speaker embeddings from speech mixtures
Jun 01, 2023



We introduce a monaural neural speaker embeddings extractor that computes an embedding for each speaker present in a speech mixture. To allow for supervised training, a teacher-student approach is employed: the teacher computes the target embeddings from each speaker's utterance before the utterances are added to form the mixture, and the student embedding extractor is then tasked to reproduce those embeddings from the speech mixture at its input. The system much more reliably verifies the presence or absence of a given speaker in a mixture than a conventional speaker embedding extractor, and even exhibits comparable performance to a multi-channel approach that exploits spatial information for embedding extraction. Further, it is shown that a speaker embedding computed from a mixture can be used to check for the presence of that speaker in another mixture.
Frame-wise and overlap-robust speaker embeddings for meeting diarization
Jun 01, 2023



Using a Teacher-Student training approach we developed a speaker embedding extraction system that outputs embeddings at frame rate. Given this high temporal resolution and the fact that the student produces sensible speaker embeddings even for segments with speech overlap, the frame-wise embeddings serve as an appropriate representation of the input speech signal for an end-to-end neural meeting diarization (EEND) system. We show in experiments that this representation helps mitigate a well-known problem of EEND systems: when increasing the number of speakers the diarization performance drop is significantly reduced. We also introduce block-wise processing to be able to diarize arbitrarily long meetings.
Adversarial learning of neural user simulators for dialogue policy optimisation
Jun 01, 2023



Reinforcement learning based dialogue policies are typically trained in interaction with a user simulator. To obtain an effective and robust policy, this simulator should generate user behaviour that is both realistic and varied. Current data-driven simulators are trained to accurately model the user behaviour in a dialogue corpus. We propose an alternative method using adversarial learning, with the aim to simulate realistic user behaviour with more variation. We train and evaluate several simulators on a corpus of restaurant search dialogues, and then use them to train dialogue system policies. In policy cross-evaluation experiments we demonstrate that an adversarially trained simulator produces policies with 8.3% higher success rate than those trained with a maximum likelihood simulator. Subjective results from a crowd-sourced dialogue system user evaluation confirm the effectiveness of adversarially training user simulators.
Self-regularised Minimum Latency Training for Streaming Transformer-based Speech Recognition
Apr 24, 2023



This paper proposes a self-regularised minimum latency training (SR-MLT) method for streaming Transformer-based automatic speech recognition (ASR) systems. In previous works, latency was optimised by truncating the online attention weights based on the hard alignments obtained from conventional ASR models, without taking into account the potential loss of ASR accuracy. On the contrary, here we present a strategy to obtain the alignments as a part of the model training without external supervision. The alignments produced by the proposed method are dynamically regularised on the training data, such that the latency reduction does not result in the loss of ASR accuracy. SR-MLT is applied as a fine-tuning step on the pre-trained Transformer models that are based on either monotonic chunkwise attention (MoChA) or cumulative attention (CA) algorithms for online decoding. ASR experiments on the AIShell-1 and Librispeech datasets show that when applied on a decent pre-trained MoChA or CA baseline model, SR-MLT can effectively reduce the latency with the relative gains ranging from 11.8% to 39.5%. Furthermore, we also demonstrate that under certain accuracy levels, the models trained with SR-MLT can achieve lower latency when compared to those supervised using external hard alignments.