 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWHISMA: A Speech-LLM to Perform Zero-shot Spoken Language Understanding
Aug 29, 2024



Speech large language models (speech-LLMs) integrate speech and text-based foundation models to provide a unified framework for handling a wide range of downstream tasks. In this paper, we introduce WHISMA, a speech-LLM tailored for spoken language understanding (SLU) that demonstrates robust performance in various zero-shot settings. WHISMA combines the speech encoder from Whisper with the Llama-3 LLM, and is fine-tuned in a parameter-efficient manner on a comprehensive collection of SLU-related datasets. Our experiments show that WHISMA significantly improves the zero-shot slot filling performance on the SLURP benchmark, achieving a relative gain of 26.6% compared to the current state-of-the-art model. Furthermore, to evaluate WHISMA's generalisation capabilities to unseen domains, we develop a new task-agnostic benchmark named SLU-GLUE. The evaluation results indicate that WHISMA outperforms an existing speech-LLM (Qwen-Audio) with a relative gain of 33.0%.
Semantic Map-based Generation of Navigation Instructions
Mar 28, 2024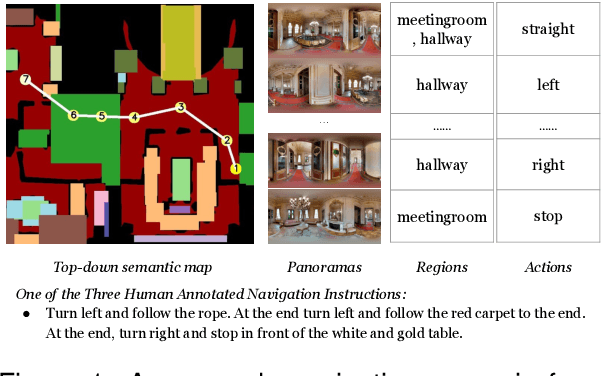
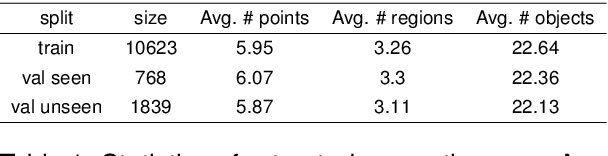
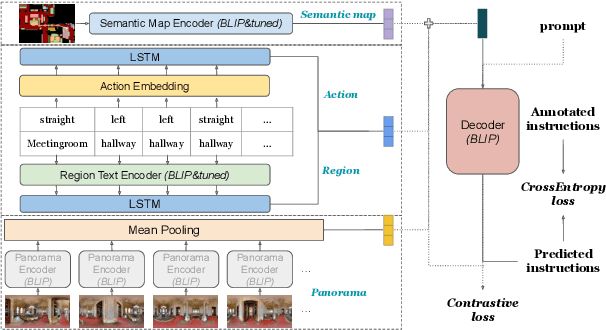
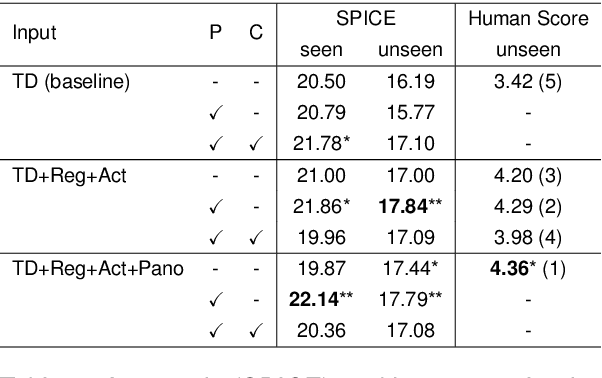
We are interested in the generation of navigation instructions, either in their own right or as training material for robotic navigation task. In this paper, we propose a new approach to navigation instruction generation by framing the problem as an image captioning task using semantic maps as visual input. Conventional approaches employ a sequence of panorama images to generate navigation instructions. Semantic maps abstract away from visual details and fuse the information in multiple panorama images into a single top-down representation, thereby reducing computational complexity to process the input. We present a benchmark dataset for instruction generation using semantic maps, propose an initial model and ask human subjects to manually assess the quality of generated instructions. Our initial investigations show promise in using semantic maps for instruction generation instead of a sequence of panorama images, but there is vast scope for improvement. We release the code for data preparation and model training at https://github.com/chengzu-li/VLGen.
Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
Sep 21, 2023
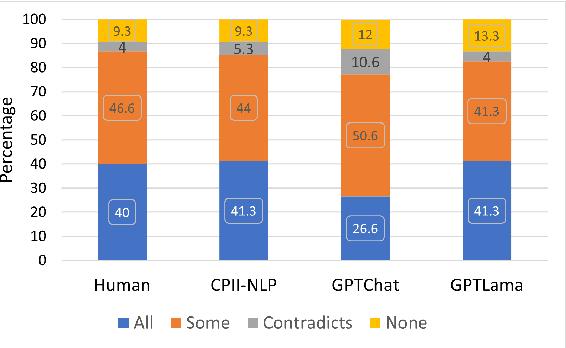


In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
Adversarial learning of neural user simulators for dialogue policy optimisation
Jun 01, 2023



Reinforcement learning based dialogue policies are typically trained in interaction with a user simulator. To obtain an effective and robust policy, this simulator should generate user behaviour that is both realistic and varied. Current data-driven simulators are trained to accurately model the user behaviour in a dialogue corpus. We propose an alternative method using adversarial learning, with the aim to simulate realistic user behaviour with more variation. We train and evaluate several simulators on a corpus of restaurant search dialogues, and then use them to train dialogue system policies. In policy cross-evaluation experiments we demonstrate that an adversarially trained simulator produces policies with 8.3% higher success rate than those trained with a maximum likelihood simulator. Subjective results from a crowd-sourced dialogue system user evaluation confirm the effectiveness of adversarially training user simulators.
Opening up Minds with Argumentative Dialogues
Jan 16, 2023

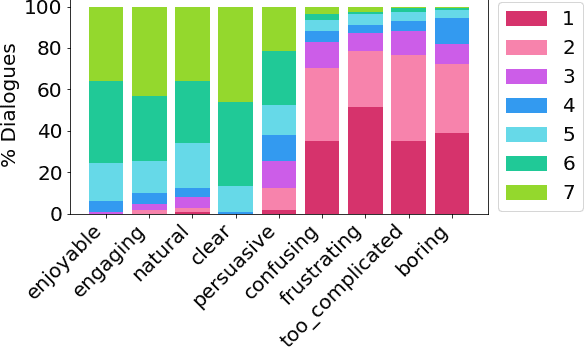
Recent research on argumentative dialogues has focused on persuading people to take some action, changing their stance on the topic of discussion, or winning debates. In this work, we focus on argumentative dialogues that aim to open up (rather than change) people's minds to help them become more understanding to views that are unfamiliar or in opposition to their own convictions. To this end, we present a dataset of 183 argumentative dialogues about 3 controversial topics: veganism, Brexit and COVID-19 vaccination. The dialogues were collected using the Wizard of Oz approach, where wizards leverage a knowledge-base of arguments to converse with participants. Open-mindedness is measured before and after engaging in the dialogue using a questionnaire from the psychology literature, and success of the dialogue is measured as the change in the participant's stance towards those who hold opinions different to theirs. We evaluate two dialogue models: a Wikipedia-based and an argument-based model. We show that while both models perform closely in terms of opening up minds, the argument-based model is significantly better on other dialogue properties such as engagement and clarity.
Dialogue Strategy Adaptation to New Action Sets Using Multi-dimensional Modelling
Apr 14, 2022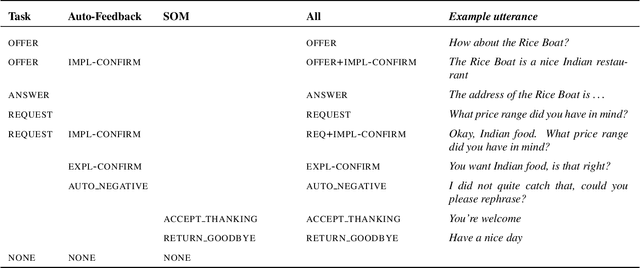
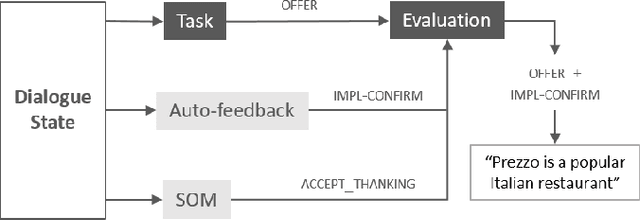
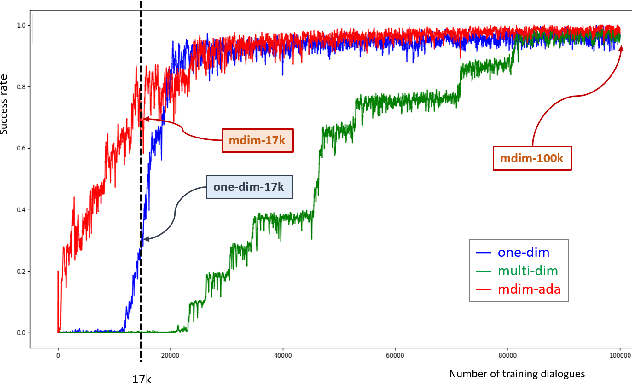
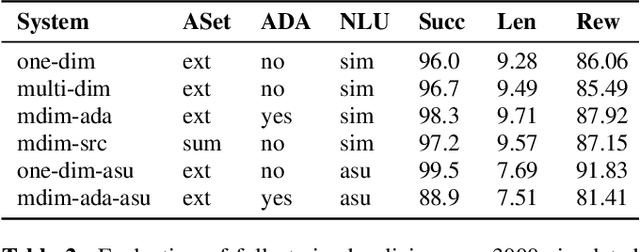
A major bottleneck for building statistical spoken dialogue systems for new domains and applications is the need for large amounts of training data. To address this problem, we adopt the multi-dimensional approach to dialogue management and evaluate its potential for transfer learning. Specifically, we exploit pre-trained task-independent policies to speed up training for an extended task-specific action set, in which the single summary action for requesting a slot is replaced by multiple slot-specific request actions. Policy optimisation and evaluation experiments using an agenda-based user simulator show that with limited training data, much better performance levels can be achieved when using the proposed multi-dimensional adaptation method. We confirm this improvement in a crowd-sourced human user evaluation of our spoken dialogue system, comparing partially trained policies. The multi-dimensional system (with adaptation on limited training data in the target scenario) outperforms the one-dimensional baseline (without adaptation on the same amount of training data) by 7% perceived success rate.
A study on cross-corpus speech emotion recognition and data augmentation
Jan 10, 2022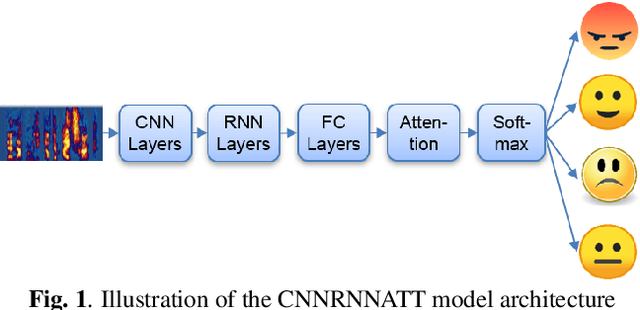
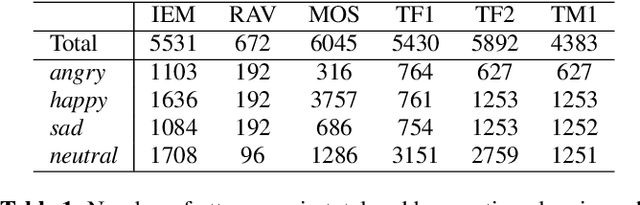

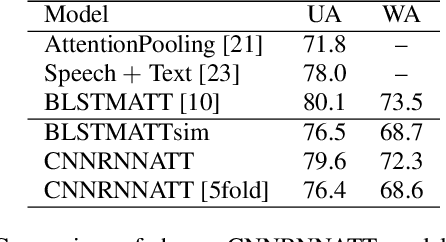
Models that can handle a wide range of speakers and acoustic conditions are essential in speech emotion recognition (SER). Often, these models tend to show mixed results when presented with speakers or acoustic conditions that were not visible during training. This paper investigates the impact of cross-corpus data complementation and data augmentation on the performance of SER models in matched (test-set from same corpus) and mismatched (test-set from different corpus) conditions. Investigations using six emotional speech corpora that include single and multiple speakers as well as variations in emotion style (acted, elicited, natural) and recording conditions are presented. Observations show that, as expected, models trained on single corpora perform best in matched conditions while performance decreases between 10-40% in mismatched conditions, depending on corpus specific features. Models trained on mixed corpora can be more stable in mismatched contexts, and the performance reductions range from 1 to 8% when compared with single corpus models in matched conditions. Data augmentation yields additional gains up to 4% and seem to benefit mismatched conditions more than matched ones.
Towards Handling Unconstrained User Preferences in Dialogue
Sep 17, 2021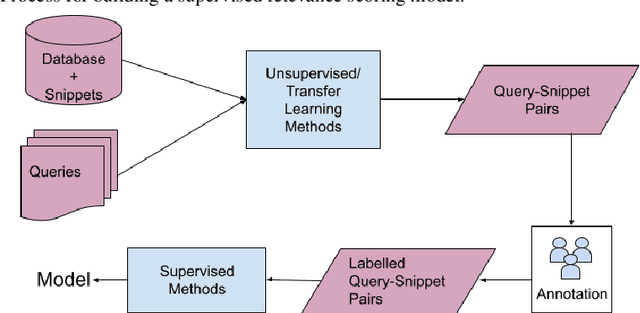

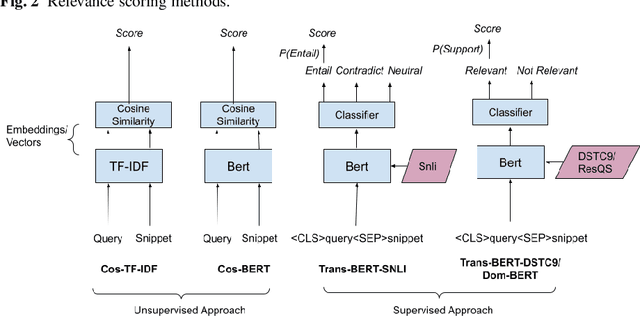
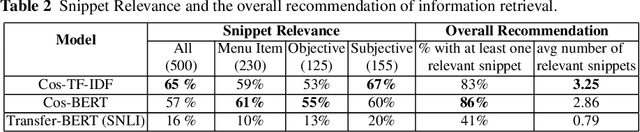
A user input to a schema-driven dialogue information navigation system, such as venue search, is typically constrained by the underlying database which restricts the user to specify a predefined set of preferences, or slots, corresponding to the database fields. We envision a more natural information navigation dialogue interface where a user has flexibility to specify unconstrained preferences that may not match a predefined schema. We propose to use information retrieval from unstructured knowledge to identify entities relevant to a user request. We update the Cambridge restaurants database with unstructured knowledge snippets (reviews and information from the web) for each of the restaurants and annotate a set of query-snippet pairs with a relevance label. We use the annotated dataset to train and evaluate snippet relevance classifiers, as a proxy to evaluating recommendation accuracy. We show that with a pretrained transformer model as an encoder, an unsupervised/supervised classifier achieves a weighted F1 of .661/.856.
Action State Update Approach to Dialogue Management
Nov 10, 2020
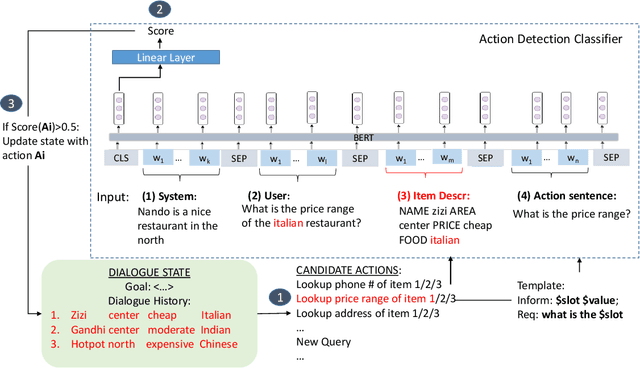


Utterance interpretation is one of the main functions of a dialogue manager, which is the key component of a dialogue system. We propose the action state update approach (ASU) for utterance interpretation, featuring a statistically trained binary classifier used to detect dialogue state update actions in the text of a user utterance. Our goal is to interpret referring expressions in user input without a domain-specific natural language understanding component. For training the model, we use active learning to automatically select simulated training examples. With both user-simulated and interactive human evaluations, we show that the ASU approach successfully interprets user utterances in a dialogue system, including those with referring expressions.