 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Map-based Generation of Navigation Instructions
Mar 28, 2024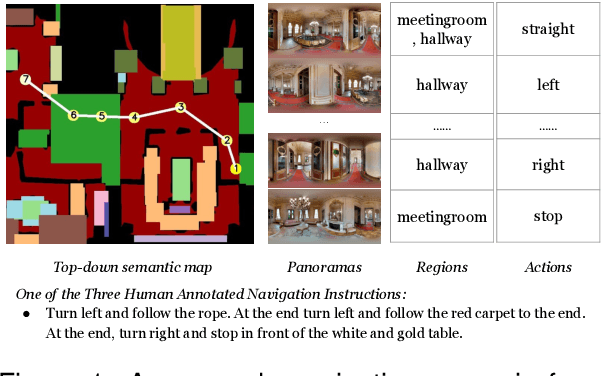
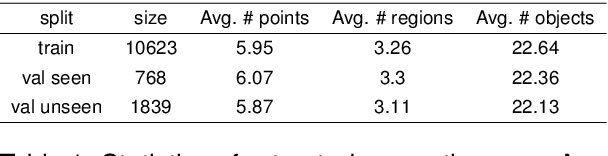
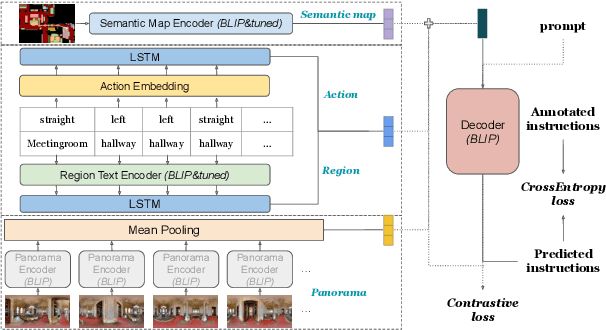
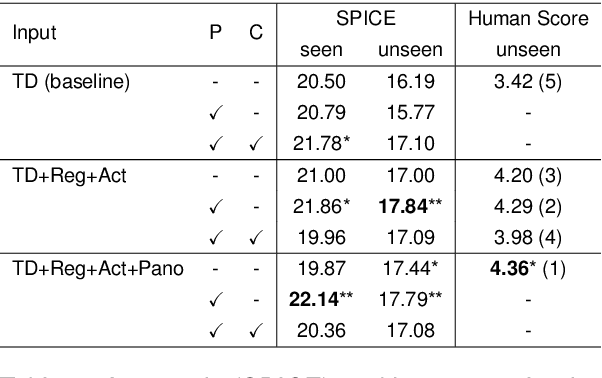
We are interested in the generation of navigation instructions, either in their own right or as training material for robotic navigation task. In this paper, we propose a new approach to navigation instruction generation by framing the problem as an image captioning task using semantic maps as visual input. Conventional approaches employ a sequence of panorama images to generate navigation instructions. Semantic maps abstract away from visual details and fuse the information in multiple panorama images into a single top-down representation, thereby reducing computational complexity to process the input. We present a benchmark dataset for instruction generation using semantic maps, propose an initial model and ask human subjects to manually assess the quality of generated instructions. Our initial investigations show promise in using semantic maps for instruction generation instead of a sequence of panorama images, but there is vast scope for improvement. We release the code for data preparation and model training at https://github.com/chengzu-li/VLGen.