 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
Sep 21, 2023
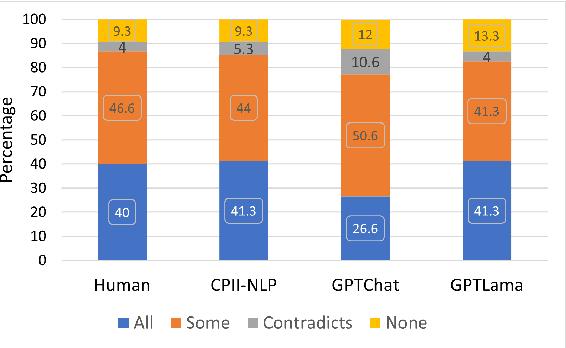


In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
Adversarial learning of neural user simulators for dialogue policy optimisation
Jun 01, 2023



Reinforcement learning based dialogue policies are typically trained in interaction with a user simulator. To obtain an effective and robust policy, this simulator should generate user behaviour that is both realistic and varied. Current data-driven simulators are trained to accurately model the user behaviour in a dialogue corpus. We propose an alternative method using adversarial learning, with the aim to simulate realistic user behaviour with more variation. We train and evaluate several simulators on a corpus of restaurant search dialogues, and then use them to train dialogue system policies. In policy cross-evaluation experiments we demonstrate that an adversarially trained simulator produces policies with 8.3% higher success rate than those trained with a maximum likelihood simulator. Subjective results from a crowd-sourced dialogue system user evaluation confirm the effectiveness of adversarially training user simulators.
Dialogue Strategy Adaptation to New Action Sets Using Multi-dimensional Modelling
Apr 14, 2022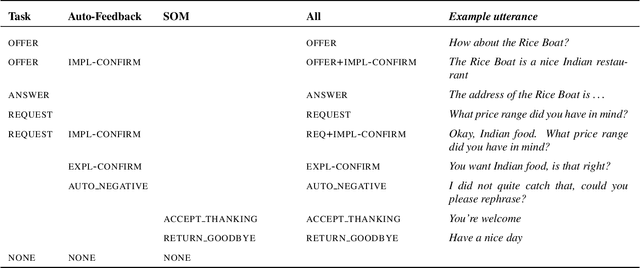
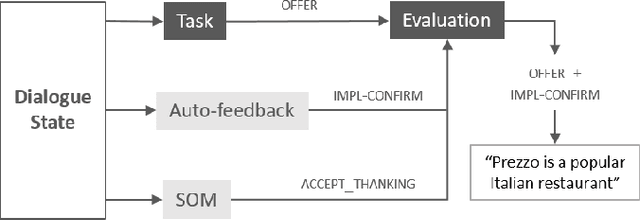
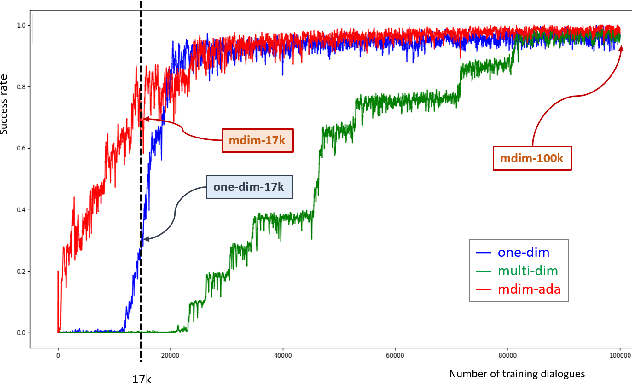
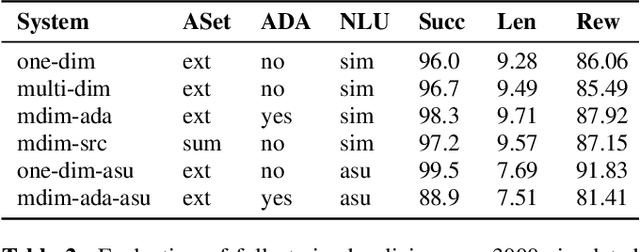
A major bottleneck for building statistical spoken dialogue systems for new domains and applications is the need for large amounts of training data. To address this problem, we adopt the multi-dimensional approach to dialogue management and evaluate its potential for transfer learning. Specifically, we exploit pre-trained task-independent policies to speed up training for an extended task-specific action set, in which the single summary action for requesting a slot is replaced by multiple slot-specific request actions. Policy optimisation and evaluation experiments using an agenda-based user simulator show that with limited training data, much better performance levels can be achieved when using the proposed multi-dimensional adaptation method. We confirm this improvement in a crowd-sourced human user evaluation of our spoken dialogue system, comparing partially trained policies. The multi-dimensional system (with adaptation on limited training data in the target scenario) outperforms the one-dimensional baseline (without adaptation on the same amount of training data) by 7% perceived success rate.
A study on cross-corpus speech emotion recognition and data augmentation
Jan 10, 2022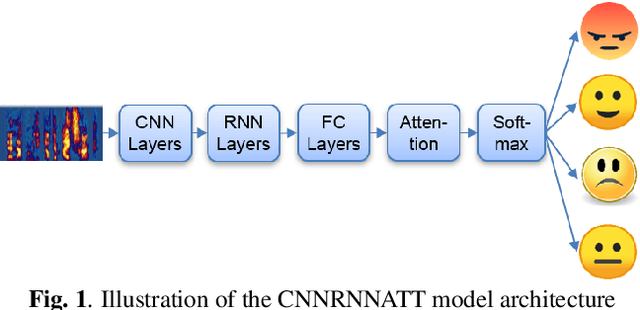
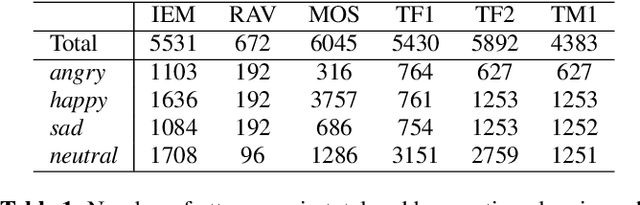

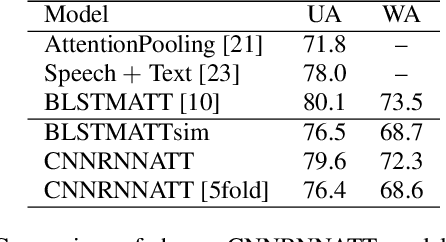
Models that can handle a wide range of speakers and acoustic conditions are essential in speech emotion recognition (SER). Often, these models tend to show mixed results when presented with speakers or acoustic conditions that were not visible during training. This paper investigates the impact of cross-corpus data complementation and data augmentation on the performance of SER models in matched (test-set from same corpus) and mismatched (test-set from different corpus) conditions. Investigations using six emotional speech corpora that include single and multiple speakers as well as variations in emotion style (acted, elicited, natural) and recording conditions are presented. Observations show that, as expected, models trained on single corpora perform best in matched conditions while performance decreases between 10-40% in mismatched conditions, depending on corpus specific features. Models trained on mixed corpora can be more stable in mismatched contexts, and the performance reductions range from 1 to 8% when compared with single corpus models in matched conditions. Data augmentation yields additional gains up to 4% and seem to benefit mismatched conditions more than matched ones.